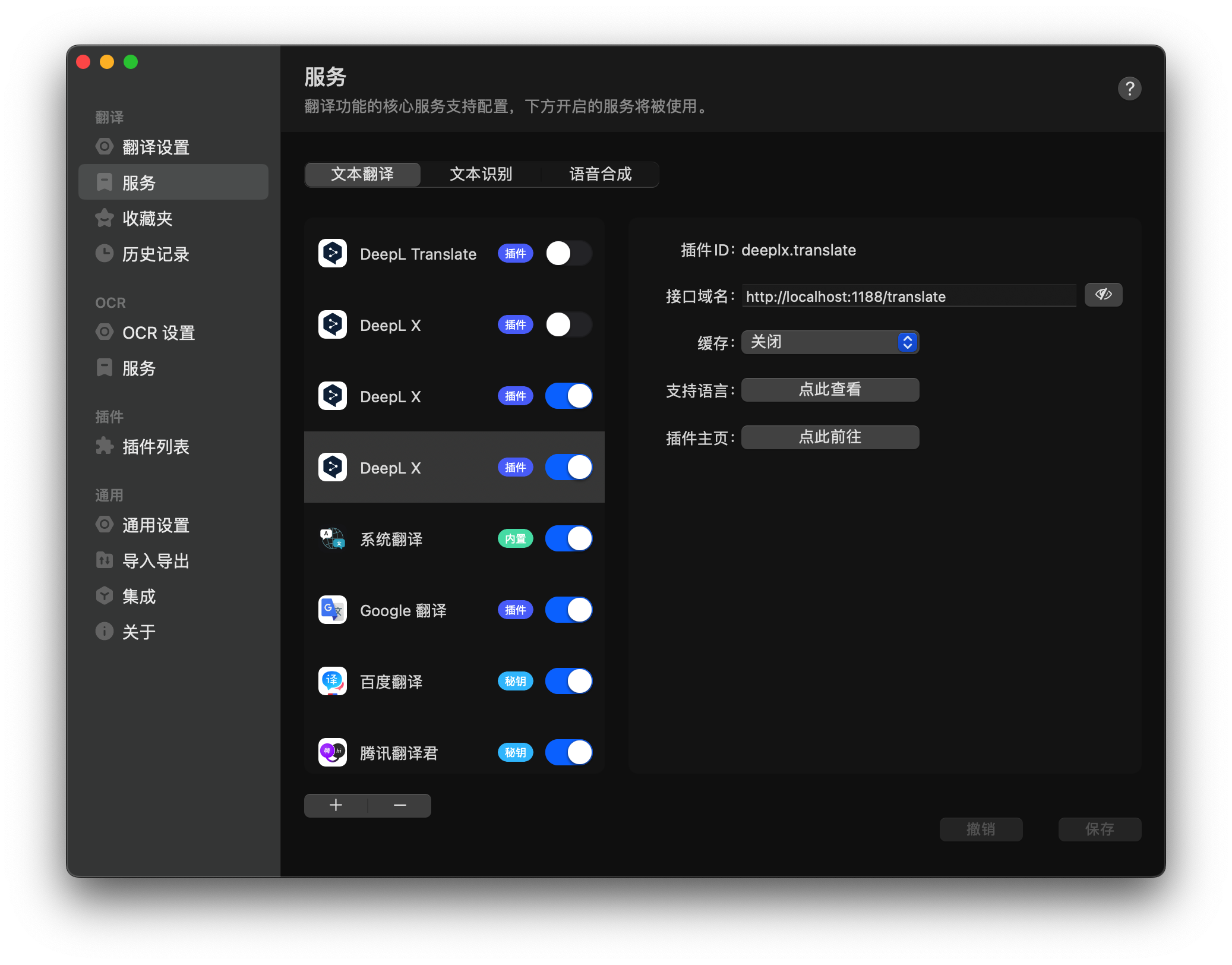
CPU 性能的高低直接影响计算机的运行速度和处理能力,广泛应用于个人电脑、服务器、嵌入式设备等各类计算设备中
-名称:中央处理单元(Central Processing Unit,CPU)
-背景与拓展:它是计算机的核心部件,负责执行计算机程序的指令,进行算术运算、逻辑运算、数据处理等操作,如同计算机的“大脑”。在计算机系统中,CPU 性能的高低直接影响计算机的运行速度和处理能力,广泛应用于个人电脑、服务器、嵌入式设备等各类计算设备中。
CPU 主要由三个核心部分组成:
-
控制单元(Control Unit, CU)
- 负责从内存中提取指令、解码并执行,协调和控制整个计算机系统的操作。
- 类似于“指挥官”,管理数据流动和各部件之间的协同工作。
-
算术逻辑单元(Arithmetic Logic Unit, ALU)
- 执行所有的算术运算(如加减乘除)和逻辑运算(如与、或、非、比较)。
- 是实现计算功能的核心引擎。
-
寄存器组(Registers)
- 高速存储单元,用于暂存指令、数据和地址,供 CPU 快速访问。
- 包括程序计数器(PC)、指令寄存器(IR)、累加器(ACC)等。
此外,现代 CPU 还包含高速缓存(Cache)(L1、L2、L3),用于缓解主存速度瓶颈,提升整体运行效率。
⚙️ CPU 的工作流程(取指-译码-执行-写回)
- 取指令(Fetch):从内存中读取下一条指令
- 译码(Decode):解析指令含义,确定所需操作和操作数
- 执行(Execute):ALU 执行相应运算
- 写回(Write-back):将结果写回寄存器或内存
这一过程称为“指令周期”,由时钟信号驱动,每秒可完成数十亿次循环(以 GHz 衡量)。
🔍 影响 CPU 性能的关键指标
| 指标 | 说明 |
|---|---|
| 主频(Clock Speed) | 单位 GHz,表示每秒执行的时钟周期数,频率越高,运算越快 |
| 核心数(Cores) | 多核 CPU 可同时处理多个任务,提升多任务和并行计算能力 |
| 线程数(Threads) | 支持超线程技术(如 Intel HT)可让单核模拟双线程,提高利用率 |
| 缓存大小 | 缓存越大,访问速度越快,减少等待内存的时间 |
| 制程工艺 | 如 7nm、5nm,越小功耗越低、集成度越高 |
| 指令集架构 | 如 x86(Intel/AMD)、ARM(移动设备),决定兼容性和应用场景 |
💡 常见 CPU 架构对比
| 架构 | 代表厂商 | 应用场景 | 特点 |
|---|---|---|---|
| x86-64 | Intel、AMD | 台式机、服务器 | 高性能、复杂指令集(CISC)、功耗较高 |
| ARM | Apple(M系列)、高通、华为 | 手机、平板、嵌入式 | 精简指令集(RISC)、低功耗、高能效比 |
| RISC-V | 开源生态 | 物联网、科研 | 开源免费、可定制化强,发展潜力大 |
🧠 实际应用举例
- 个人电脑:Intel Core i7 或 AMD Ryzen 7 提供强大多任务处理能力
- 苹果 M1/M2/M3 芯片:基于 ARM 架构的 SoC(片上系统),集成 CPU、GPU、NPU,实现高性能低功耗
- 服务器 CPU:AMD EPYC 或 Intel Xeon,支持多路处理器、大内存带宽,适合云计算与大数据处理
- 嵌入式系统:MCU 中的 Cortex-M 系列 CPU,用于智能家电、汽车电控单元
📈 发展趋势
- 多核化:从单核到四核、八核甚至几十核,提升并行处理能力
- 异构计算:CPU 与 GPU、NPU 协同工作(如 AI 加速)
- 能效优化:在移动和边缘设备中追求更高性能每瓦特(Performance/Watt)
- Chiplet(芯粒)设计:将 CPU 拆分为多个小芯片封装,提升良率与灵活性(如 AMD Zen 架构)
CPU(Central Processing Unit) 和 GPU(Graphics Processing Unit) 在架构设计和用途上存在本质区别,主要体现在核心设计理念、并行能力、适用任务类型等方面。它们并非互相替代,而是互补协作,共同完成不同类型的计算任务。
🔍 一、核心架构对比
| 特性 | CPU | GPU |
|---|---|---|
| 核心数量 | 少(通常 2~64 核) | 极多(数千个精简核心) |
| 单核性能 | 高(复杂控制逻辑、大缓存) | 较低(简化控制,专注吞吐) |
| 时钟频率 | 高(3~5 GHz) | 相对较低(1~2 GHz) |
| 缓存大小 | 大(L1/L2/L3 缓存丰富) | 相对较小 |
| 功耗管理 | 精细调度,支持睡眠/唤醒 | 高吞吐下功耗较高,需散热优化 |
💡 类比理解:
- CPU 像“少数精英专家”,擅长快速解决复杂问题;
- GPU 像“百万大军”,每个士兵能力一般,但能同时执行大量相似任务。
⚙️ 二、设计目标与工作方式
✅ CPU:通用计算,强调低延迟
- 设计目标:快速响应、高效处理复杂的顺序任务
- 支持复杂的分支预测、流水线、乱序执行等机制
- 擅长运行操作系统、应用程序、数据库事务等控制密集型任务
✅ GPU:专用并行计算,强调高吞吐量
- 初始用于图形渲染(像素、顶点着色),每个像素独立可并行处理
- 现代 GPU 支持通用计算(GPGPU,General-Purpose computing on GPU)
- 使用 CUDA(NVIDIA) 或 OpenCL 编程模型进行大规模并行计算
- 擅长处理矩阵运算、图像处理、深度学习训练等数据并行任务
🧩 三、典型应用场景对比
| 应用场景 | 主要使用 | 原因 |
|---|---|---|
| 操作系统调度 | CPU | 需要精确控制流和中断处理 |
| 文本编辑、网页浏览 | CPU | 交互性强,任务不规则 |
| 视频游戏画面渲染 | GPU | 数百万像素并行计算着色 |
| 深度学习训练(如训练大模型) | GPU / TPU | 大规模矩阵乘法高度并行 |
| 图像识别、视频编码 | GPU | 数据块独立,适合并行处理 |
| 科学模拟(气候、流体) | GPU | 可分解为网格级并行计算 |
| 数据库查询 | CPU | 多为条件判断、索引查找等串行操作 |
📈 四、性能表现差异举例
以一个简单的向量加法为例:
# 计算 A[i] + B[i] → C[i],共 100 万次操作
- CPU:用一个或几个核心逐个或小批量处理,速度快但并发有限
- GPU:将 100 万个计算分配给上千个核心同时执行,总耗时远低于 CPU
在深度学习中,一次前向传播涉及数亿次矩阵乘加操作,GPU 能比 CPU 快 10~100 倍以上
🔄 五、协同工作模式(CPU + GPU)
现代系统通常是 异构计算架构,CPU 和 GPU 协同工作:
-
CPU 负责整体控制:
- 加载程序、管理内存、调度任务
- 将适合并行的任务交给 GPU
-
GPU 执行大规模并行计算:
- 接收数据和指令,完成计算后返回结果
-
通过 PCIe 总线通信:
- 数据在主机内存(RAM)和显存(VRAM)之间传输
示例:AI 推理时,CPU 加载模型和输入数据,启动 GPU 进行推理计算,结果再由 CPU 处理输出
🧠 六、发展趋势
| 方向 | 说明 |
|---|---|
| CPU 集成 GPU | 如 Intel 的 Iris Xe、AMD 的 APU、Apple M 系列芯片,提升能效比 |
| GPU 通用化 | NVIDIA 的 CUDA 生态使 GPU 成为 AI、科学计算主力 |
| 专用加速器兴起 | 如 Google TPU、华为 Ascend,专为 AI 设计,性能更高 |
| 统一内存架构(UMA) | Apple M 系列共享内存,减少 CPU/GPU 数据拷贝开销 |
✅ 总结对比表
| 维度 | CPU | GPU |
|---|---|---|
| 核心思想 | 低延迟、强单核性能 | 高吞吐、大规模并行 |
| 核心数量 | 少而精 | 多而简 |
| 适用任务 | 控制密集、串行逻辑 | 数据并行、计算密集 |
| 典型应用 | 操作系统、办公软件 | 游戏、AI、图像处理 |
| 编程模型 | C/C++、Java 等通用语言 | CUDA、OpenCL、PyTorch/TensorFlow |
| 是否可替代 | 不可替代基础控制功能 | 可部分替代 CPU 的并行计算任务 |
CPU的发展历程是微处理器技术不断突破晶体管集成度、架构设计和性能极限的过程,从1971年首款商用微处理器诞生至今,可清晰划分为五个关键阶段,每个阶段都有标志性产品和技术革新,具体如下:
- 萌芽期(1971 - 1980年):微处理器诞生与x86架构奠基
这一阶段核心是完成从无到有的突破,处理器从4位逐步过渡到16位,为个人电脑发展埋下伏笔。1971年Intel推出全球首款商用微处理器4004,仅含2300个晶体管,4位架构,主频108kHz,主要用于计算器;1972年Intel 8008作为首款8位处理器,集成3500个晶体管,推动了小型计算机的初步发展。1978年Intel 8086问世,这是首款16位x86架构处理器,集成2.9万个晶体管,其确立的x86指令集成为后续PC处理器的核心标准,1979年推出的8088芯片更是成功应用于IBM个人电脑,开启了微处理器在PC领域的应用篇章。 - 性能初步增长期(1980 - 2000年):32位主导与架构逐步成熟
此阶段处理器全面迈入32位时代,通过集成缓存、引入新架构等方式提升性能,市场竞争也开始显现。1985年Intel 80386推出,集成27.5万个晶体管,内存寻址能力提升至4GB,支持多任务操作系统;1989年Intel 80486首次将晶体管数量突破100万,还内置L1缓存和浮点运算单元,性能较前代提升显著。1993年Intel放弃数字命名,推出Pentium(奔腾)处理器,采用超标量架构,推动PC进入多媒体时代;同期AMD推出K6处理器,以高性价比打破Intel的垄断局面。 - 多核过渡与64位普及期(2000 - 2010年):突破主频瓶颈
单纯提升主频引发的功耗和发热问题愈发严重,多核设计和64位架构成为发展主流。2003年AMD推出Athlon 64,作为全球首款64位PC处理器,兼容32位程序,为高端PC和服务器提供了更强算力;2005年Intel推出Pentium D双核处理器,虽为胶水双核设计性能提升有限,但标志着CPU正式进入多核时代。2008年Intel Core i7发布,采用Nehalem架构,集成三通道内存控制器和L3缓存,还引入睿频技术,成为高端CPU的标杆产品,也推动多核技术逐渐成为市场主流。 - 多核成熟与能效优化期(2010 - 2020年):性价比竞争与工艺升级
处理器在多核数量、制程工艺和能效比上持续突破,市场竞争倒逼技术快速迭代。制程工艺从32nm逐步升级至14nm,2015年Intel Skylake系列采用14nm工艺,功耗降低40%,其移动版助力轻薄本的普及。2017年AMD Ryzen系列登场,以8核16线程的设计和高性价比,打破Intel长期的市场优势,推动行业进入多核普及的新阶段,也促使整个市场在性能和价格上形成良性竞争。 - AI集成与架构重构新时代(2020年至今):多元创新突破制程极限
随着AI需求激增和制程逼近物理极限,处理器开始向集成专用算力单元、架构创新和Chiplet(芯粒)设计等方向发展。Intel Core i9 - 12900K采用大小核设计,集成AI算力单元,AI性能大幅提升;AMD Ryzen 7000系列采用5nm工艺,集成核显且支持DDR5内存,能效比显著提升。同时,非x86架构异军突起,如Apple M1 Ultra通过芯片互联技术实现超强算力;RISC - V开源架构也快速发展,被应用于边缘计算和国产芯片中。此外,Intel推进18A工艺研发,AMD采用3D Chiplet堆叠技术,以此突破传统制程的限制。