Prometheus监控GPU算力服务器
概要
Prometheus如何监控GPU资源相关指标数据,原生插件并不支持GPU监控,可以基于“nvidia_gpu_expoter”第三方插件对GPU算力服务器资源进行指标收集,通过“Grafana”图形化展示监控数据。
技术细节
GPU服务器操作系统: Ubuntu 22.04.5 LTS
Prometheus:2.53.5
Grafana:12.0.2
nvidia_gpu_expoter:1.3.2
部署流程
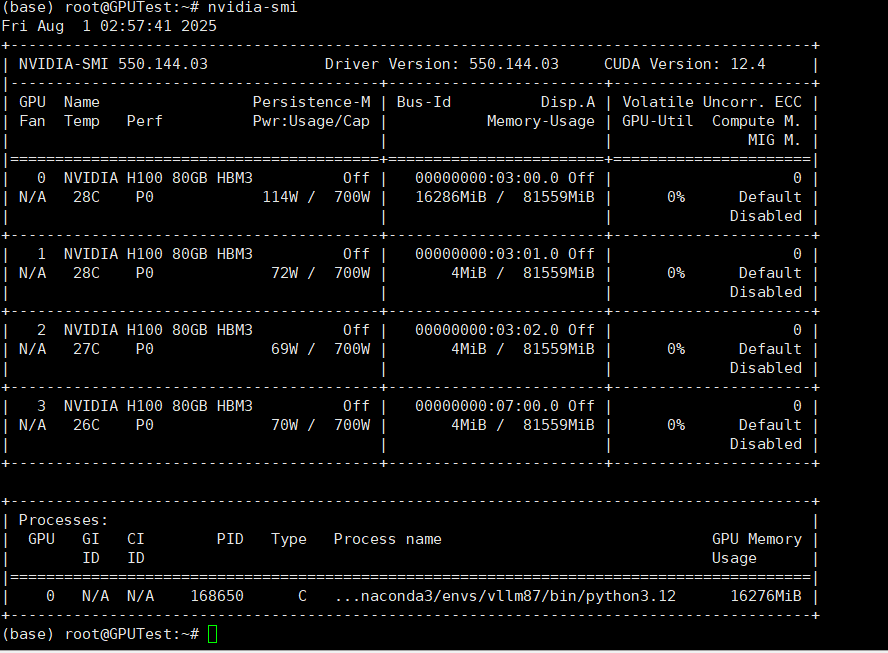
1.查看显卡状态信息
root@GPUTest:~# nvidia-smi
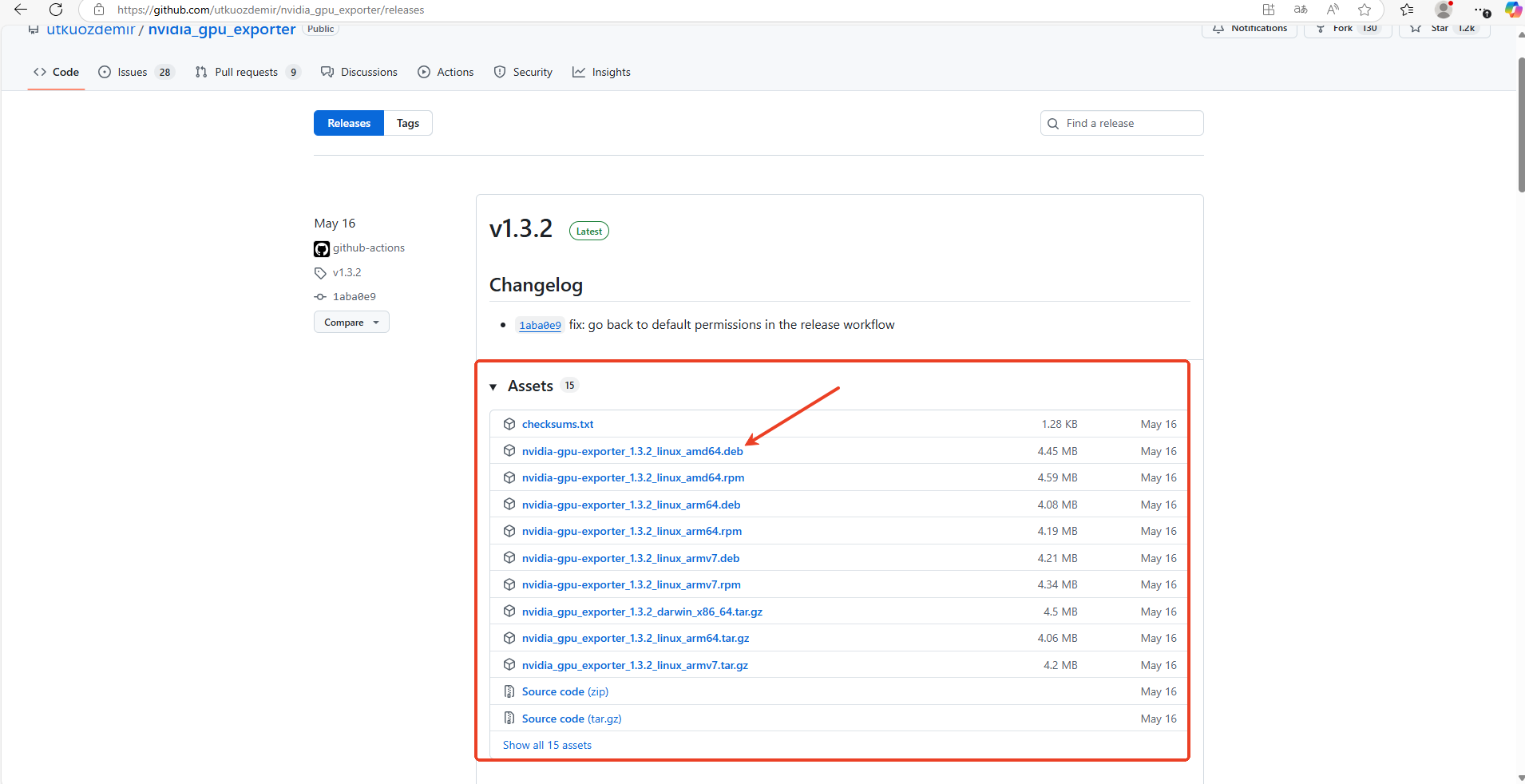
2.获取适配系统版本的nvidia_gpu_expoter
nvidia_gpu_expoter:
GitHub项目地址: https://github.com/utkuozdemir/nvidia_gpu_exporter
不同环境版本格式: https://github.com/utkuozdemir/nvidia_gpu_exporter/releases
不同环境安装方式: https://github.com/utkuozdemir/nvidia_gpu_exporter/blob/master/INSTALL.md
根据系统选择对应的版本,我的服务器是Ubuntu版本,故选择deb包安装
3.下载安装nvidia_gpu_expoter
1.创建并进入插件下载目录
root@GPUTest:~# mkdir /prometheus
root@GPUTest:~# cd /prometheus/
2.下载nvidia_gpu_expoter插件 由于是GitHub拉取可能因网络原因造成下载失败 自行准备科学上网工具
root@GPUTest:/prometheus# wget https://github.com/utkuozdemir/nvidia_gpu_exporter/releases/download/v1.3.2/nvidia-gpu-exporter_1.3.2_linux_amd64.deb
3.安装查看服务运行状态
root@GPUTest:/prometheus# dpkg -i nvidia-gpu-exporter_1.3.2_linux_amd64.deb
root@GPUTest:/prometheus# systemctl status nvidia_gpu_exporter.service

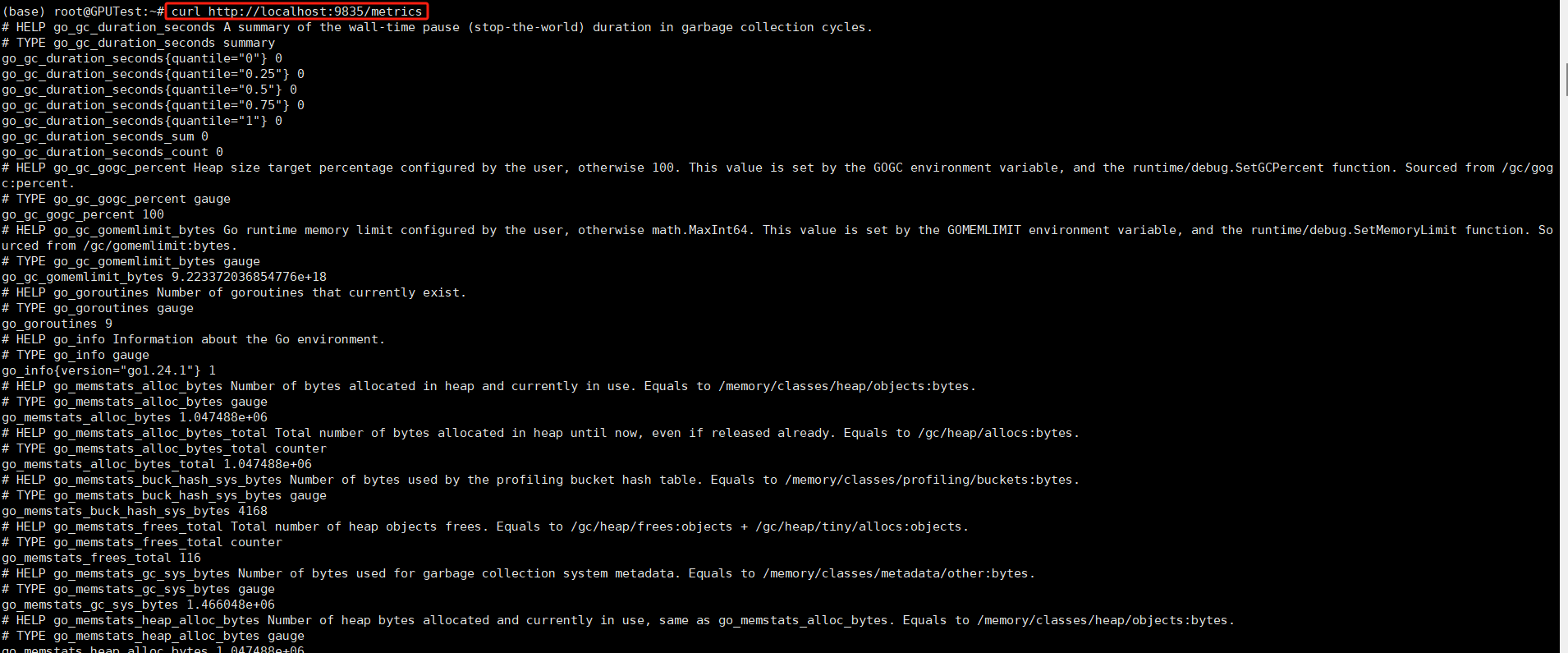
1.nvidia_gpu_exporter默认监听端口“”9835“ 测试是否能够获取到GPU指标
root@GPUTest:~# curl http://localhost:9835/metrics
...
nvidia_smi_gpu_info{driver_model_current="[N/A]",driver_model_pending="[N/A]",driver_version="550.144.03",name="NVIDIA H100 80GB HBM3",uuid="361dbfc5-47fc-fac9-e586-2ca07e238cbc",vbios_version="96.00.89.00.01"} 1
nvidia_smi_gpu_info{driver_model_current="[N/A]",driver_model_pending="[N/A]",driver_version="550.144.03",name="NVIDIA H100 80GB HBM3",uuid="3864c5f2-ab9d-b20f-f1e4-4b0cde613c88",vbios_version="96.00.89.00.01"} 1
nvidia_smi_gpu_info{driver_model_current="[N/A]",driver_model_pending="[N/A]",driver_version="550.144.03",name="NVIDIA H100 80GB HBM3",uuid="46c4da72-8ce8-995a-65a4-4edd6d51e554",vbios_version="96.00.89.00.01"} 1
nvidia_smi_gpu_info{driver_model_current="[N/A]",driver_model_pending="[N/A]",driver_version="550.144.03",name="NVIDIA H100 80GB HBM3",uuid="a232ff97-585a-7e4b-dfbe-95c50bd90d78",vbios_version="96.00.89.00.01"} 1
...
4.Prometheus配置
1.修改Prometheus配置文件
[root@localhost conf]# cat prometheus.yml
global:
scrape_interval: 15s
rule_files:
- /etc/prometheus/alert.rules.yml
scrape_configs:
- job_name: 'GPU_Test'
static_configs:
- targets: ['10.0.40.91:9835'] #更改为你GPU服务器IP
[root@localhost conf]#
2.热加载更新配置文件或重启Prometheus服务
[root@localhost conf]# curl -X POST http://localhost:9090/-/reload
查看Prometheus Web界面配置已生效
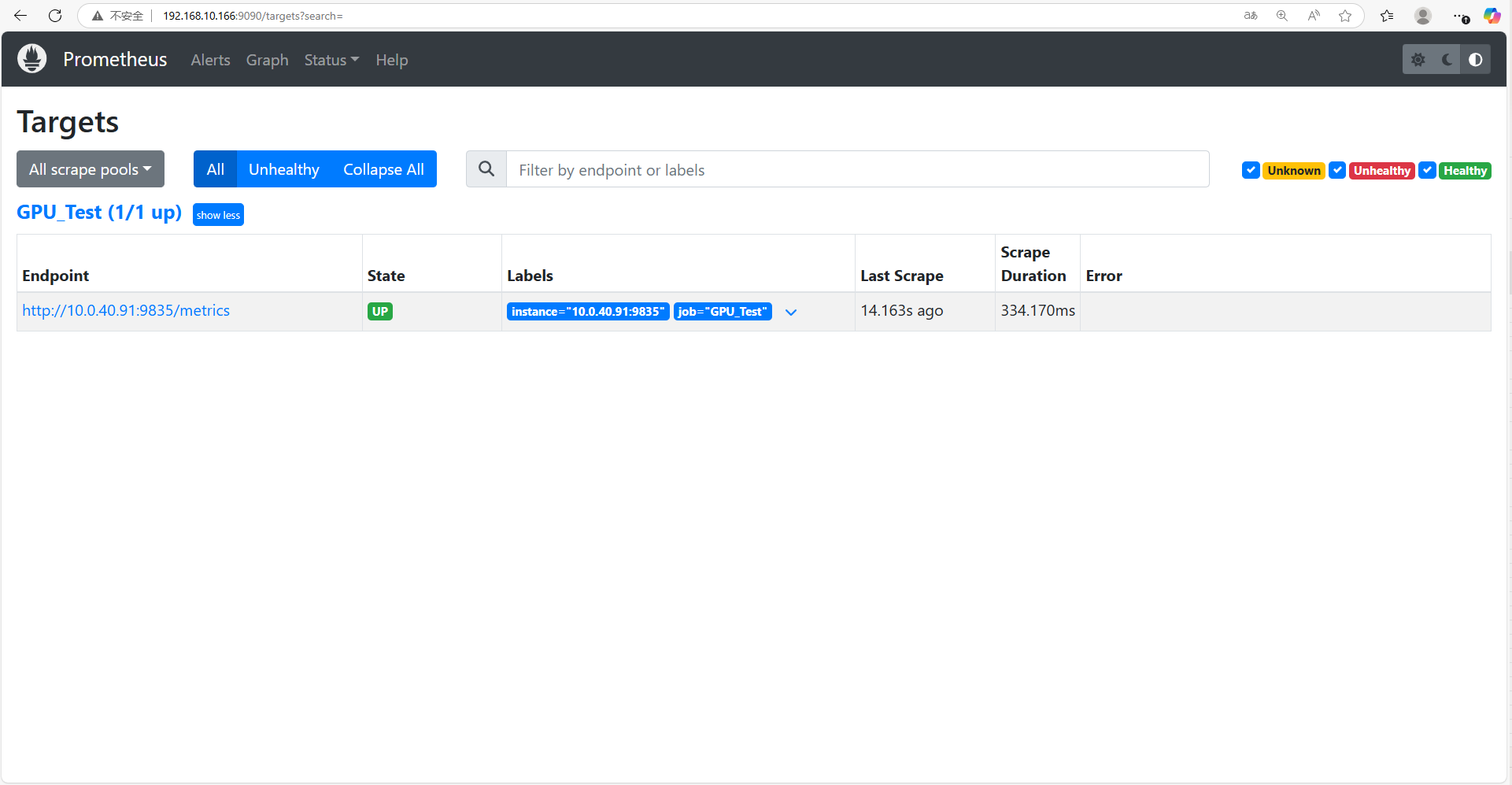
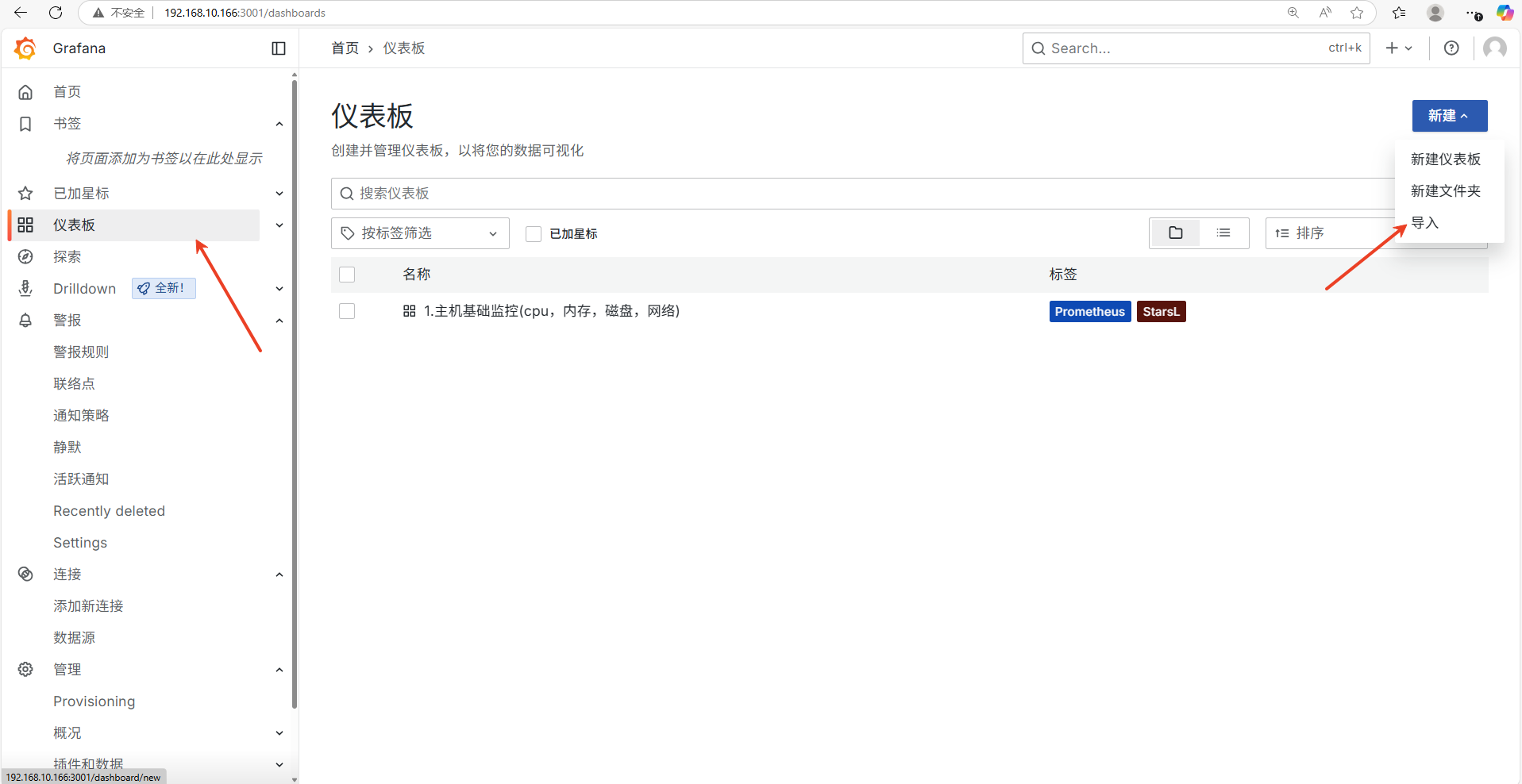
5.Grafana配置
导入仪表盘进行图形化界面展示
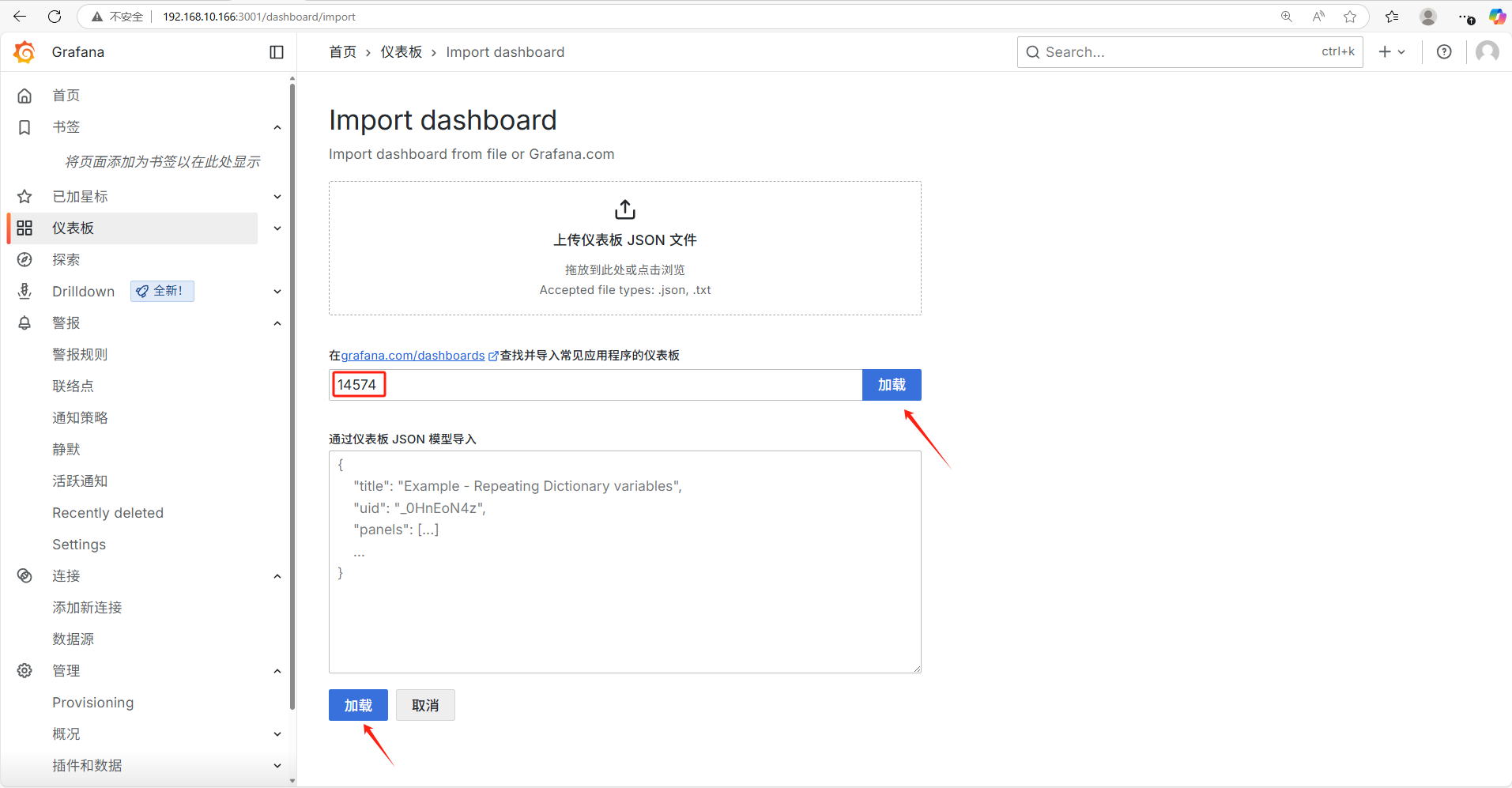
模版ID:14574
加载模版ID
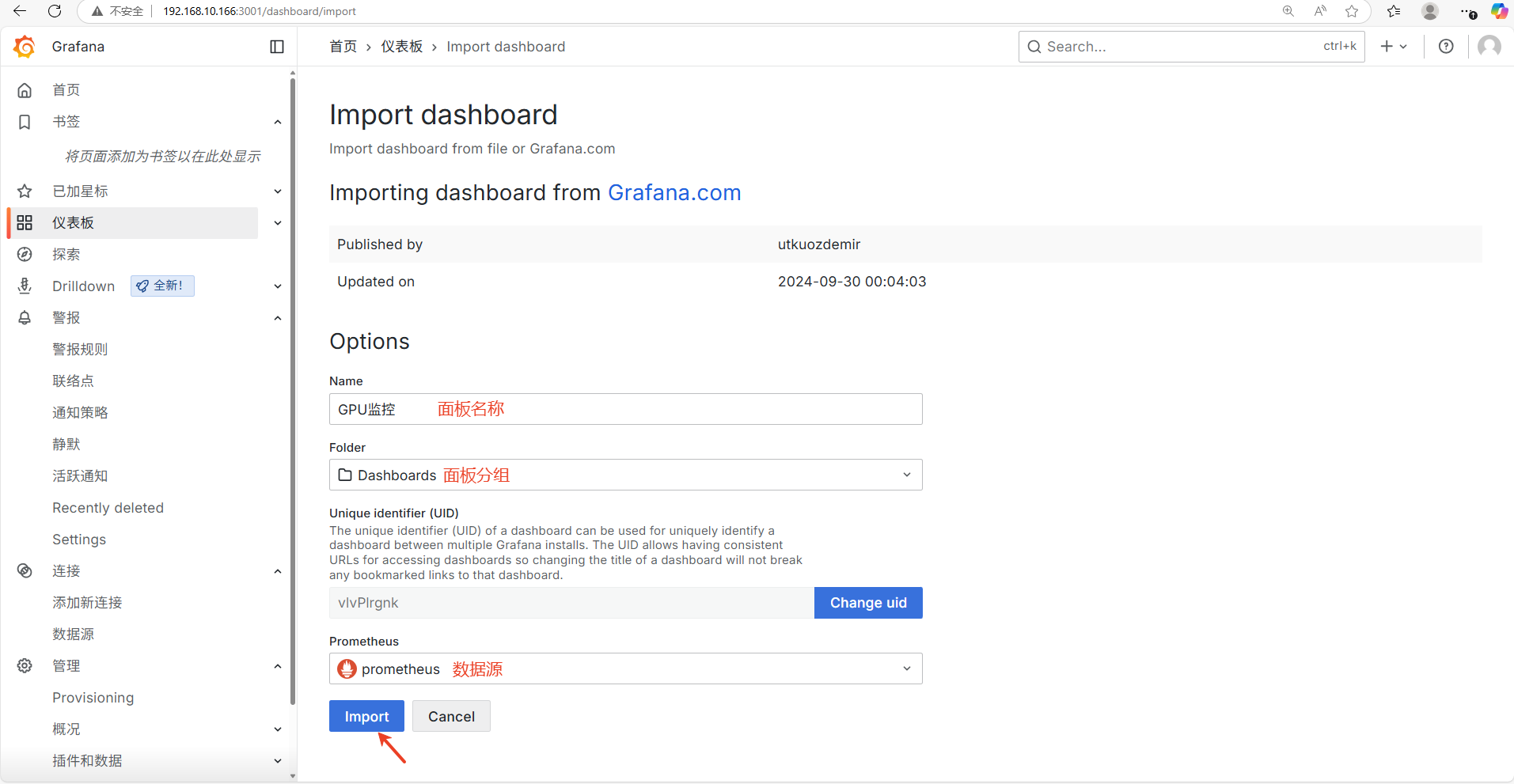
设置监控面板的名称、分组、数据源(数据源这里我已经配置好Prometheus源,如果数据源这里为空需要先配置下数据源)
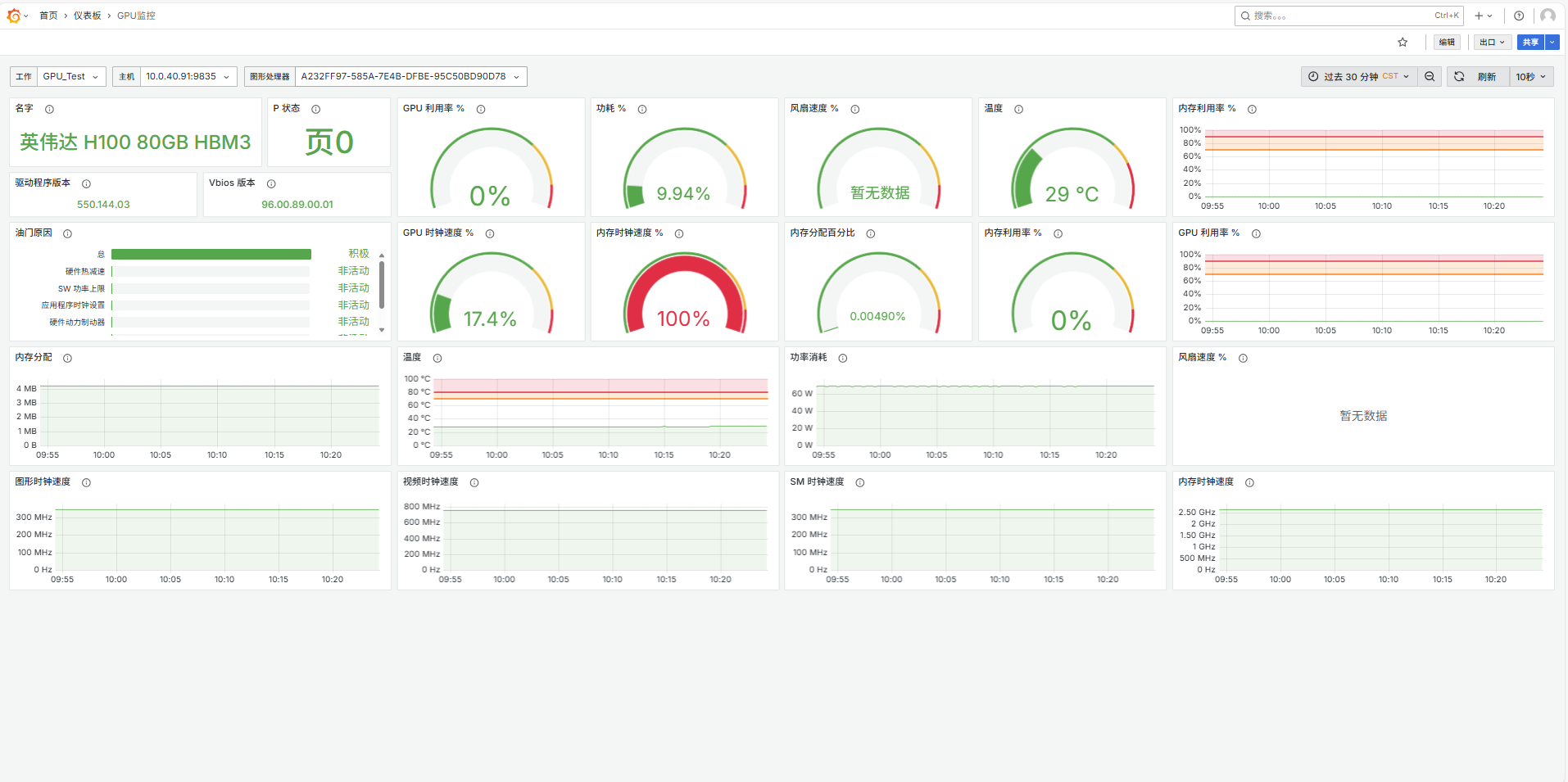
H100监控数据图表展示 由于H100和普通显卡散热结构的区别,所以H100是没有风扇相关数据的
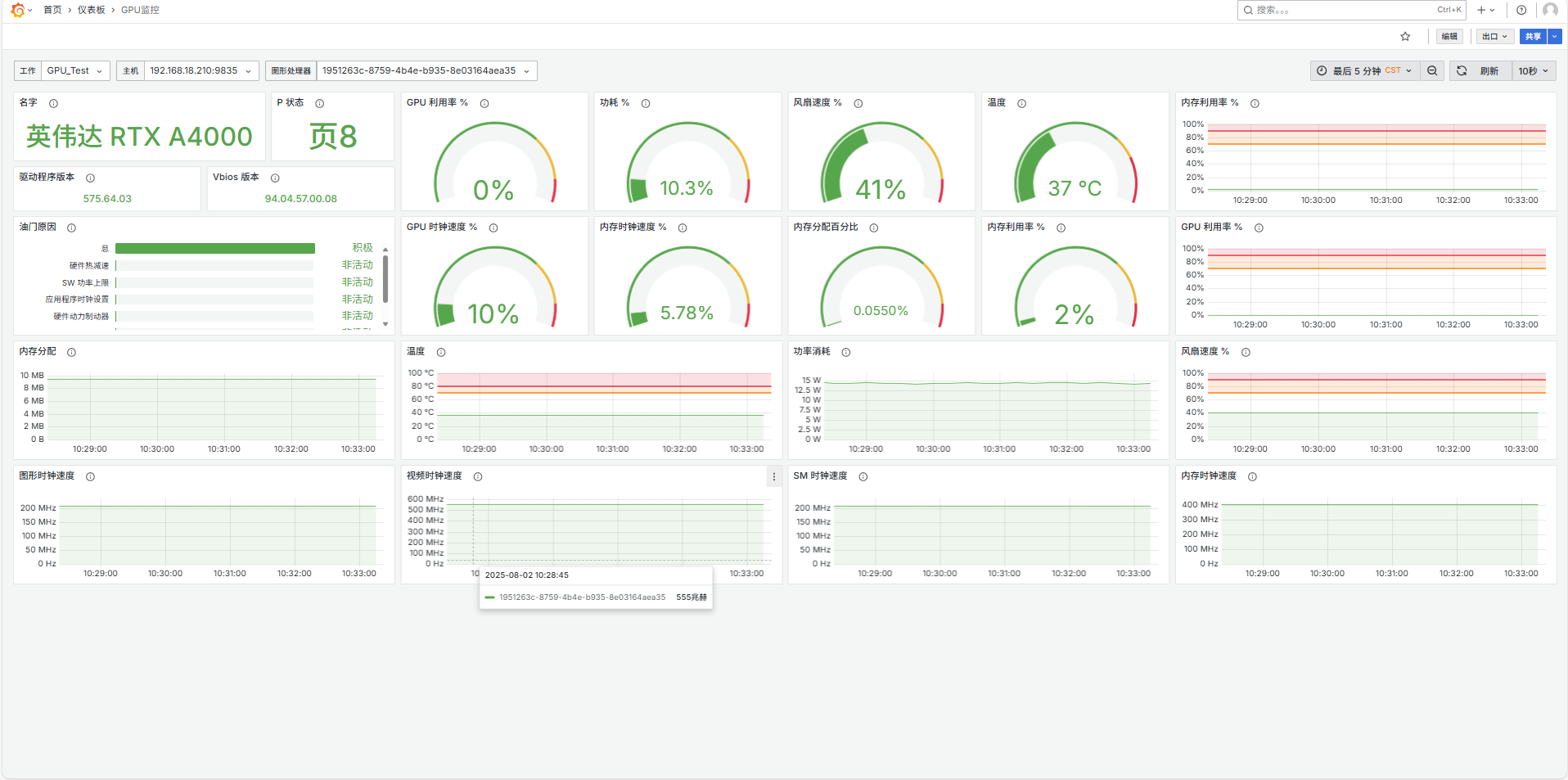
自用A4000显卡监控数据图表展示
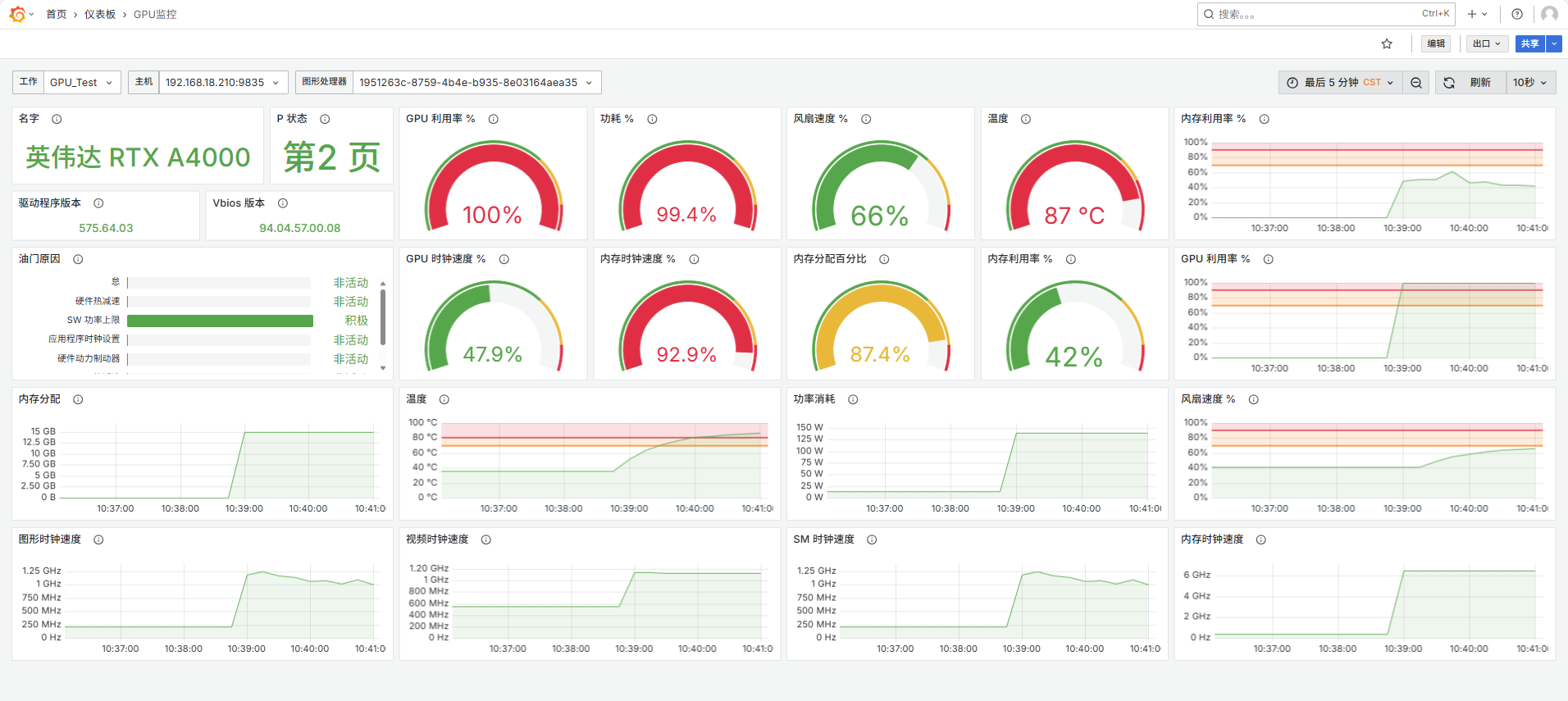
这里对显卡进行一下压力测试,实时查看GPU使用率上升
1.下载显卡压测工具
root@ubuntu:~# git clone https://github.com/wilicc/gpu-burn.git
root@ubuntu:~# cd gpu-burn/
2.编译后执行压测脚本 600表示压测持续时间 单位:秒 这里设置为10分钟
root@ubuntu:~# make
root@ubuntu:~# ./gpu_burn 600
显卡实时利用率和功耗瞬间飙升
小结
本篇文章基于 Prometheus、Grafana 和 nvidia_gpu_exporter 构建的 GPU 资源监控方案,实现了从数据采集到可视化展示的完整流程。在生产环境中,结合标签分类与告警规则配置,可显著提升运维效率并确保及时告警通知。