Parsr多语言支持:中文文档解析的特殊处理与优化
Parsr多语言支持:中文文档解析的特殊处理与优化
【免费下载链接】Parsr Transforms PDF, Documents and Images into Enriched Structured Data  项目地址: https://gitcode.com/gh_mirrors/pa/Parsr
项目地址: https://gitcode.com/gh_mirrors/pa/Parsr
Parsr作为一款强大的文档解析工具,在中文文档处理方面有着独特的优势和技术实现。本文将深入解析Parsr在中文文档解析过程中的特殊处理机制和优化策略,帮助用户更好地理解和运用这一功能。🎯
Parsr支持将PDF、文档和图像转换为结构化数据,特别在处理中文文档时,通过OCR引擎和文本处理模块的协同工作,能够准确识别和提取中文内容。对于包含中文的PDF文件和图像文档,Parsr提供了完整的解决方案。
🔍 中文文档解析的核心挑战
中文文档解析面临几个独特的技术挑战:
字符识别复杂性:中文拥有数千个常用字符,相比英文26个字母的识别要复杂得多。Parsr通过Tesseract OCR引擎的多语言支持,配合专门的中文语言包,实现了高精度的中文字符识别。
排版多样性:中文文档可能包含竖排文字、表格、图片等多种复杂排版格式。Parsr通过模块化处理流程,逐个解决这些难题。
 Parsr的GUI界面支持中文文档上传与解析
Parsr的GUI界面支持中文文档上传与解析
🛠️ 中文OCR配置优化
在Parsr的配置文件中,针对中文文档的OCR设置需要特别注意:
{
"extractor": {
"pdf": "pdfminer",
"ocr": "tesseract",
"language": ["chi_sim", "eng"]
}
}
语言包配置:必须确保安装了Tesseract的中文语言包(chi_sim.traineddata),这是实现中文识别的关键基础。
📊 中文文档处理流程
Parsr处理中文文档的完整流程包括:
- 文档预处理:自动检测文档语言特征,优化后续处理参数
- 文本提取:根据文档类型选择合适的提取器
- 结构分析:识别段落、表格、标题等文档结构
- 内容优化:对识别结果进行后处理,提高准确性
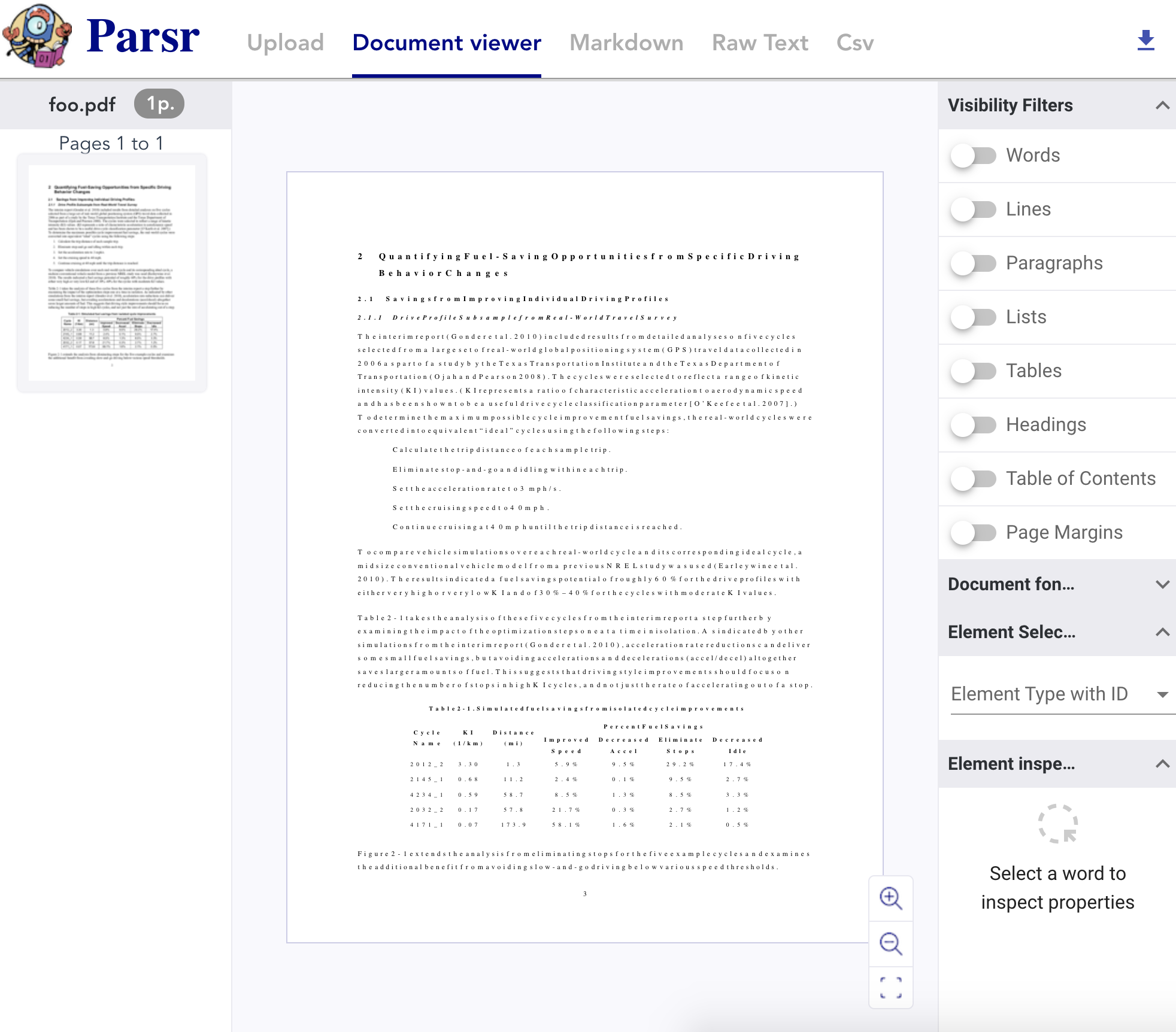 Parsr对中文文档的解析结果展示
Parsr对中文文档的解析结果展示
🎯 中文特殊字符处理
中文文档中常见的特殊字符和格式需要特别处理:
标点符号识别:中文特有的标点符号(如顿号、书名号等)在解析过程中需要特殊算法支持。
字体兼容性:不同中文字体在PDF中的编码方式可能不同,Parsr能够自动适配这些差异。
🔧 配置参数详解
在defaultConfig.json中,与中文处理相关的关键参数包括:
language:设置识别语言为中文(chi_sim)confidence-threshold:调整识别置信度阈值preprocessing:优化图像预处理参数
📈 性能优化建议
为了获得更好的中文文档解析效果,建议:
- 文档质量保证:确保扫描文档清晰度,避免模糊或扭曲
- 字体选择:尽量使用标准中文字体,避免艺术字体
- 分辨率设置:对于图像文档,建议分辨率不低于300dpi
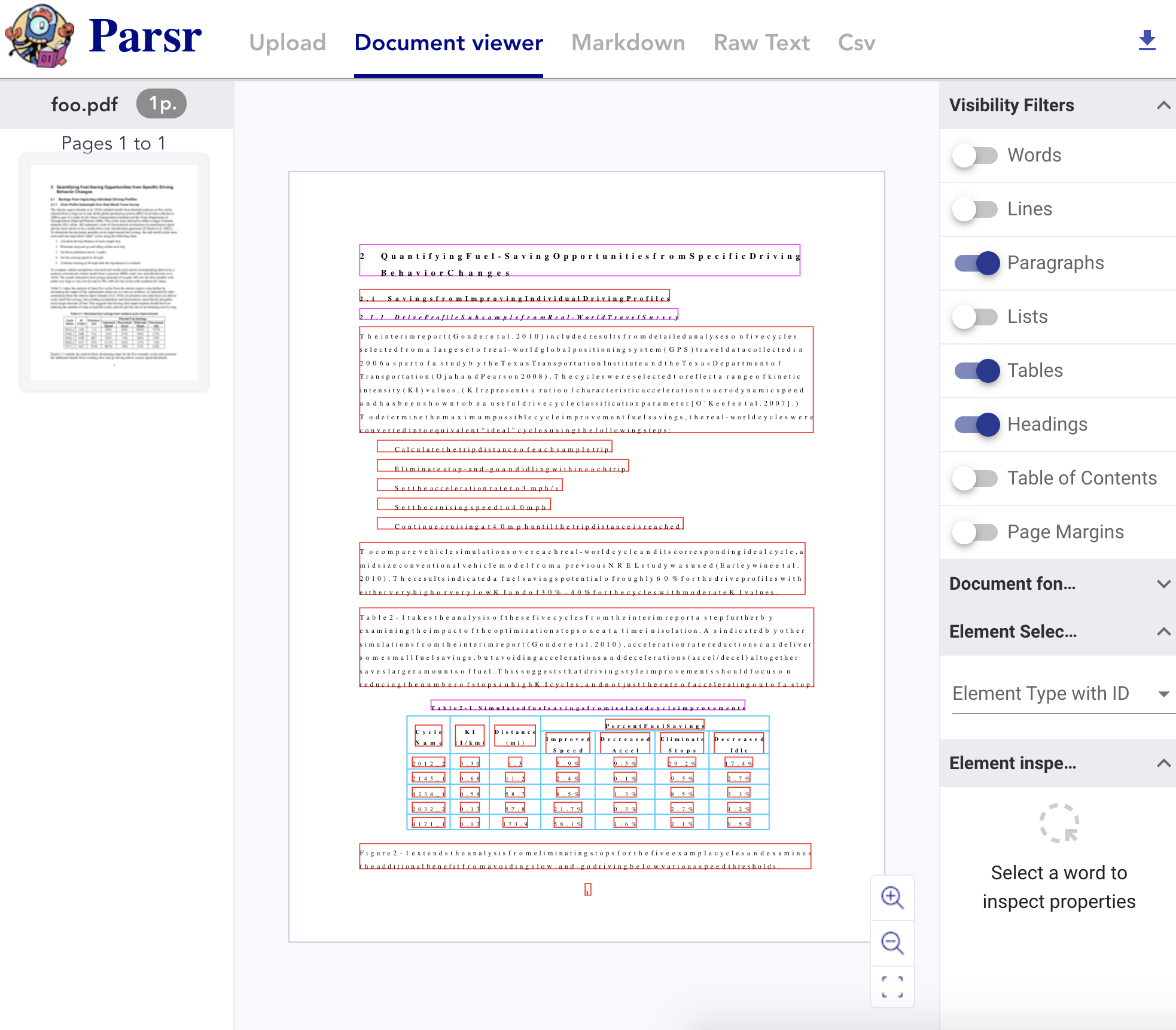 Parsr高级功能对中文复杂排版的支持
Parsr高级功能对中文复杂排版的支持
💡 实用技巧与最佳实践
批量处理优化:对于大量中文文档,建议使用API接口进行自动化处理。
错误处理机制:当遇到无法识别的中文字符时,Parsr会记录日志并提供修复建议。
🚀 进阶应用场景
Parsr在中文文档处理方面的进阶应用包括:
- 智能表格提取:准确识别中文表格结构和内容
- 关键词标注:自动标记文档中的关键中文词汇
- 语义分析:基于上下文理解中文语义关系
通过合理配置和优化,Parsr能够为中文用户提供高效、准确的文档解析服务,大大提升文档处理的工作效率。✨
【免费下载链接】Parsr Transforms PDF, Documents and Images into Enriched Structured Data 项目地址: https://gitcode.com/gh_mirrors/pa/Parsr