阿里 Qwen3-Omni-Flash 破局:人设自由背后,藏着大模型与 GPU 服务器的硬核关联
AI 能精准切换 “甜妹” 娇憨语气与 “御姐” 飒爽表达?阿里刚发布的 Qwen3-Omni-Flash 全模态大模型,把这种科幻场景变成了现实。2025 年 12 月 9 日,Qwen 团队官宣的这款升级模型,不仅实现了文本、图像、音视频的无缝交互,更通过开放系统提示词权限刷新了个性化体验 —— 而这一切流畅表现的背后,都离不开 GPU 服务器的强力支撑。

一、拆解核心升级:不止人设切换,更是多模态能力的全面进化
很多人只注意到 “人设自定义” 的新鲜感,却忽略了这是模型底层能力的质变。Qwen3-Omni-Flash 在 Qwen3-Omni 基础上的升级,本质是多模态交互效率与可控性的双重突破:
其一是全模态实时流转技术。不同于传统模型需分别处理文本、图像、音视频的割裂模式,新模型能实现多类型信息的 “无缝输入 - 同步解析 - 流式输出”。比如上传一段含图表的视频并语音提问,模型可同时识别画面数据、解析音频意图,再以自然语音实时反馈,首包延迟低至毫秒级。这背后是对音视频编码、跨模态融合算法的深度优化,让多信息维度的处理实现 “零断层”。
其二是系统提示词的 “权限解放”。被业内称为 AI “隐形脚本” 的系统提示词(System Prompt),是定义模型行为的核心框架。以往这类脚本多由开发者预设,而 Qwen3-Omni-Flash 首次全面开放自定义权限:用户只需通过参数设置明确 “身份(如日系二次元博主)、语气(口语化 / 书面化)、输出规则(500 字以内分点说明)”,模型就能精准落地人设风格。这种可控性的飞跃,让 AI 从 “通用助手” 变成 “专属伙伴”,在虚拟主播、定制化客服等场景极具实用价值。
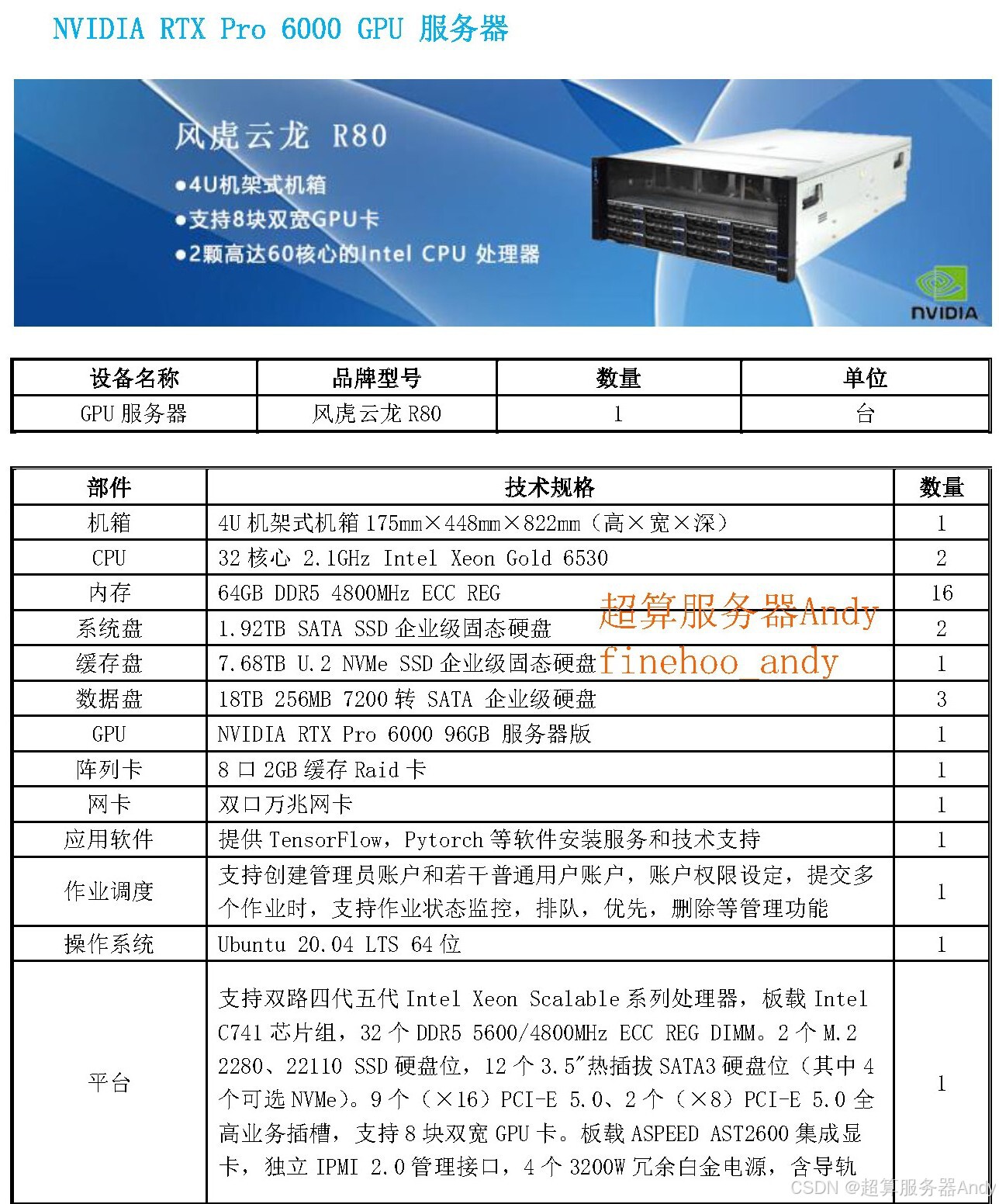
二、关键关联:为什么全模态大模型离不开 GPU 服务器?
不少人疑惑:模型功能升级和 GPU 服务器有什么关系?答案是:没有强大的 GPU 算力支撑,再先进的算法也只是 “空中楼阁”,这一点在全模态模型中体现得尤为明显。
从技术原理看,全模态处理对算力的需求呈指数级增长。Qwen3-Omni-Flash 采用 Thinker-Talker 双体 MoE 架构,仅视觉编码器就包含 540M 参数,音频编码器达 650M,处理 30 秒视频需占用近 90GB 显存。而文本、图像、音视频的同步解析,需要同时调动多个神经网络模块并行运算 —— 这正是 GPU 服务器的核心优势:通过海量 CUDA 核心实现并行计算,将多模态数据的处理效率提升数十倍,避免出现 “上传视频后等待几分钟才响应” 的卡顿问题。
对普通用户而言,轻量级部署可能只需 RTX 3060 级别的显卡,但要实现工业级应用或科研探索,必须依赖专业 GPU 服务器:其多卡互联架构可支持模型分布式部署,显存池化技术能突破单卡显存限制,满足长视频处理、高并发交互等重度需求。简单说,GPU 服务器就是全模态模型的 “动力引擎”,算力强弱直接决定了模型的响应速度、处理精度和应用边界。
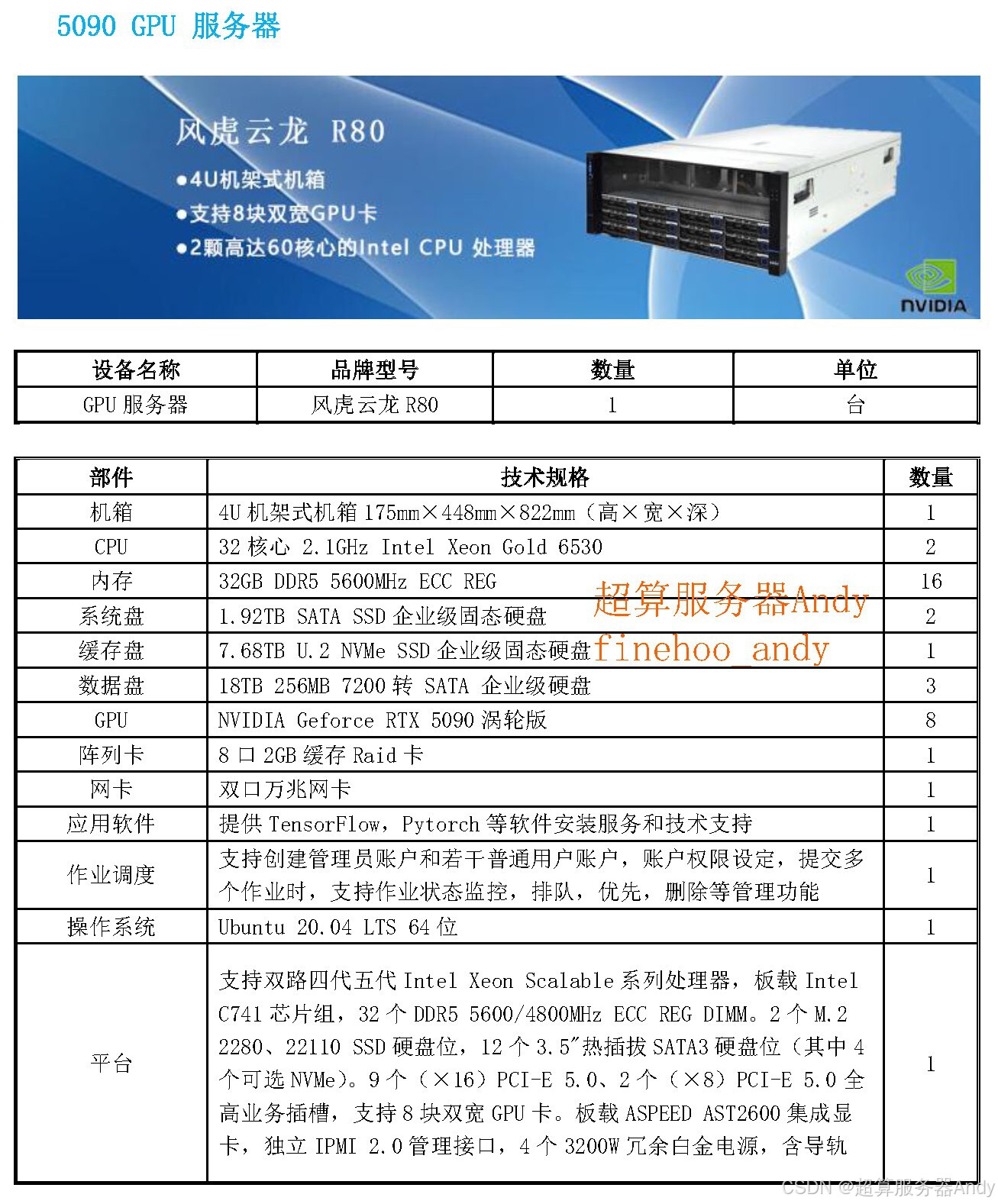
三、科研视角:为什么科研服务器是 AI 研究的 “刚需装备”?
对于科研人员而言,专业科研服务器更是开展大模型研究的 “标配工具”,这源于其三大核心优势:
-
算力弹性与扩展性。科研中常需测试不同参数量(如 7B/30B/70B)模型的性能差异,或进行大规模微调训练。科研服务器支持多 GPU 卡灵活组合(如 8 卡 / 16 卡 NVIDIA A100),可根据实验需求动态分配算力,避免因算力不足导致实验中断。例如微调 Qwen3-Omni-Flash 的语音生成模块时,多卡并行能将训练周期从数月缩短至数周。
-
稳定的多任务处理能力。AI 科研往往需要同时运行 “数据预处理、模型训练、性能测评” 等多流程任务,普通计算机易出现算力分配混乱、系统崩溃等问题。科研服务器的专用计算架构和散热设计,能保障多任务并行时的稳定性,且支持 24 小时不间断运行,满足长周期实验需求。
-
适配科研级软件生态。专业 GPU 服务器预装 CUDA Toolkit、PyTorch 等深度学习框架,兼容 vLLM 等高效部署工具,可直接对接 Qwen 系列模型的开源代码库。这让科研人员无需在环境配置上耗费精力,能专注于算法优化、模态融合机制等核心研究,大幅提升科研效率。
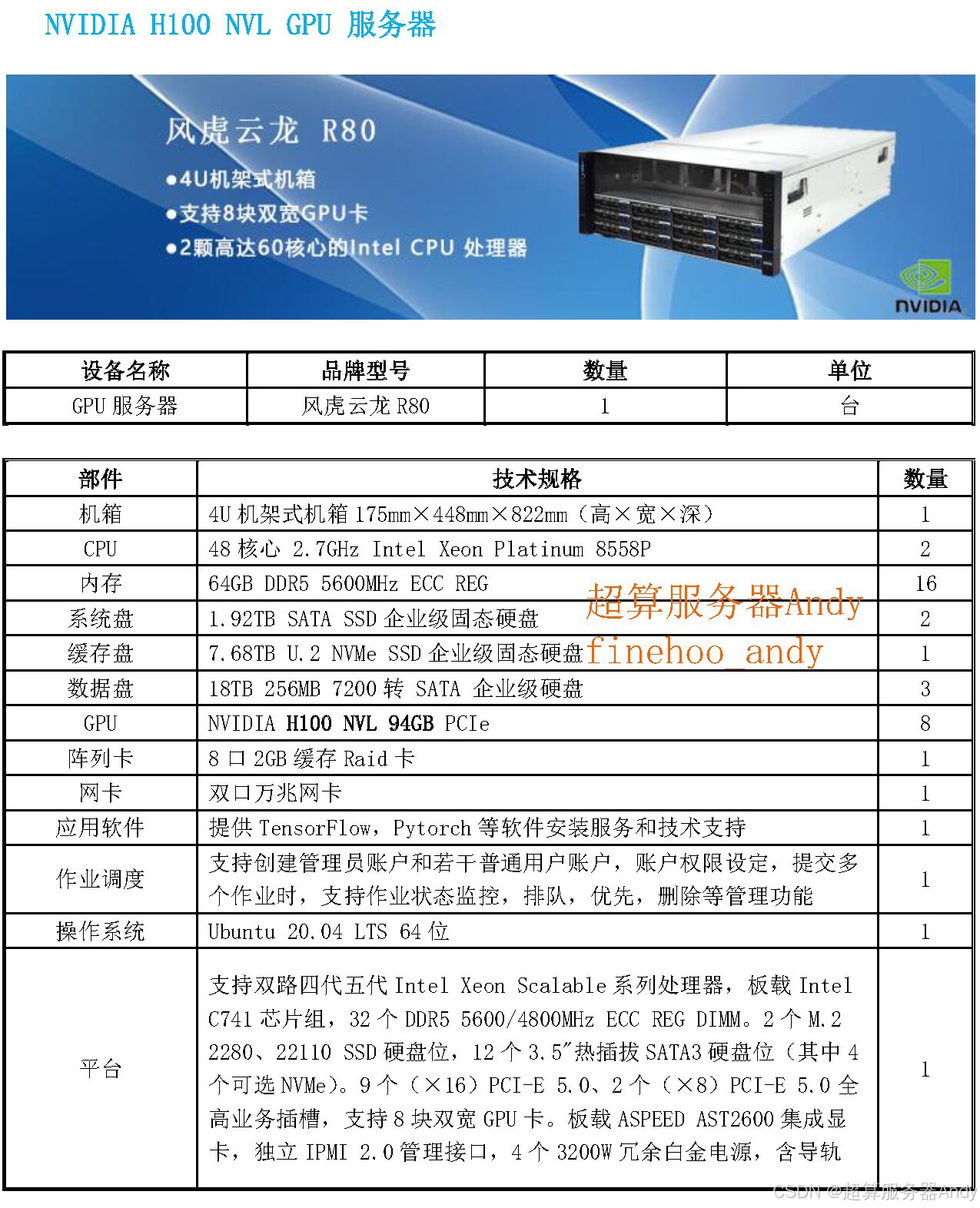
从阿里 Qwen 系列的迭代轨迹可见,大模型的每一次突破都伴随着算力需求的升级,而 GPU 服务器则在 “算法创新” 与 “落地应用” 之间搭建了关键桥梁。对于普通用户,Qwen3-Omni-Flash 带来了更懂需求的 AI 交互;对于科研人员,它则为多模态智能、人机交互等领域的探索提供了优质 “试验田”—— 而这一切,都离不开算力基础设施的坚实支撑。