【Oracle篇】基于OGG 21c全程图形化实现9TB数据从Oracle 11g到19c的不停机迁移(中):源端与目标端配置,及全量和增量同步配置详解(第二篇,总共三篇)
💫《博主主页》:
🔎 CSDN主页: 奈斯DB
🔎 IF Club社区主页: 奈斯、
🔎 微信公众号: 奈斯DB
🔥《擅长领域》:
🗃️ 数据库:阿里云AnalyticDB (云原生分布式数据仓库)、Oracle、MySQL、SQLserver、NoSQL(Redis)
🛠️ 运维平台与工具:Prometheus监控、DataX离线异构同步工具
💖如果觉得文章对你有所帮助,欢迎点赞收藏加关注💖

一、源生产库
注意:采用的是微服务架构部署OGG,微服务架构可以采用中心枢纽(Hub)部署模式。这是一个重要的改进,可以将OGG微服务部署在独立于源端和目标端数据库的第三方服务器上。因此源生产库上关于经典架构OGG的操作都可以只在专属的OGG微服务服务器上操作。
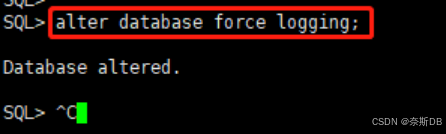
1.1 打开生产库的强日志写
SQL> select FORCE_LOGGING from v$database; SQL> alter database force logging; ---为了使所有表生产日志。因为可能生产上为了开发,而关闭了记录redo日志的功能。
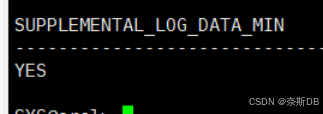
1.2 打开补充日志(打开最小附加日志模式,日志的记录按照最小颗粒记录)
select SUPPLEMENTAL_LOG_DATA_MIN from v$database; alter database add supplemental log data; ---打开附加日志模式 select SUPPLEMENTAL_LOG_DATA_MIN from v$database;
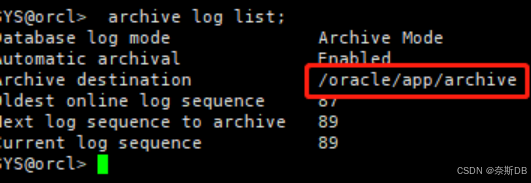
1.3 确保归档打开
SYS@orcl> archive log list;
1.4 启动ogg复制参数
alter system set enable_goldengate_replication=true scope=both; ---解决ggsci配置增加补充日志时的ORA-26947: Oracle GoldenGate replication is not enabled.
1.5 创建专用的ogguser用户用来同步数据(rac库和ogg库要相同,任意实例创建)
create tablespace ogg_tbs datafile '+data'size 200M autoextend on; create user ogguser identified by 123456 default tablespace ogg_tbs; grant connect to ogguser; grant alter any table to ogguser; grant alter session to ogguser; grant create session to ogguser; grant flashback any table to ogguser; grant select any dictionary to ogguser; grant select any table to ogguser; grant resource to ogguser; grant drop any table to ogguser; grant dba to ogguser; ---高权限
二、ogg库
注意:采用的是微服务架构部署OGG,微服务架构可以采用中心枢纽(Hub)部署模式。这是一个重要的改进,可以将OGG微服务部署在独立于源端和目标端数据库的第三方服务器上。因此ogg库上关于经典架构OGG的操作都可以只在专属的OGG微服务服务器上操作。
2.1 启动ogg复制参数
alter system set enable_goldengate_replication=true scope=both; ---解决ggsci配置增加补充日志时的ORA-26947: Oracle GoldenGate replication is not enabled.
2.2 创建专用的ogguser用户用来同步数据(rac库和ogg库要相同,任意实例创建)
create tablespace ogg_tbs datafile '+data'size 200M autoextend on; create user ogguser identified by 123456 default tablespace ogg_tbs; grant connect to ogguser; grant alter any table to ogguser; grant alter session to ogguser; grant create session to ogguser; grant flashback any table to ogguser; grant select any dictionary to ogguser; grant select any table to ogguser; grant resource to ogguser; grant drop any table to ogguser; grant dba to ogguser; ---高权限
2.3 非必要操作
需要注意:如下操作是只在ogg库回同步至源生产库或者同步至其他库时才需要配置的,因为同步来自ogg库上的DML和DDL操作同样是需要打开强日志写、补充日志等一系列操作的。反之如果不需要同步至源生产库或者同步至其他库则不需要配置如下操作。
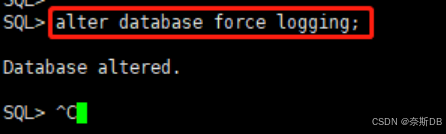
- 打开生产库的强日志写
SQL> select FORCE_LOGGING from v$database; SQL> alter database force logging; ---为了使所有表生产日志。因为可能生产上为了开发,而关闭了记录redo日志的功能。
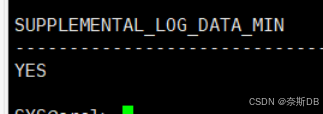
- 打开补充日志(打开最小附加日志模式,日志的记录按照最小颗粒记录)
select SUPPLEMENTAL_LOG_DATA_MIN from v$database; alter database add supplemental log data; ---打开附加日志模式 select SUPPLEMENTAL_LOG_DATA_MIN from v$database;
- 确保归档打开
SYS@orcl> archive log list;

三、在ogg微服务页面配置连接数据库、检查点表、增加补充日志、查看所有的参数文件、以及清理队列
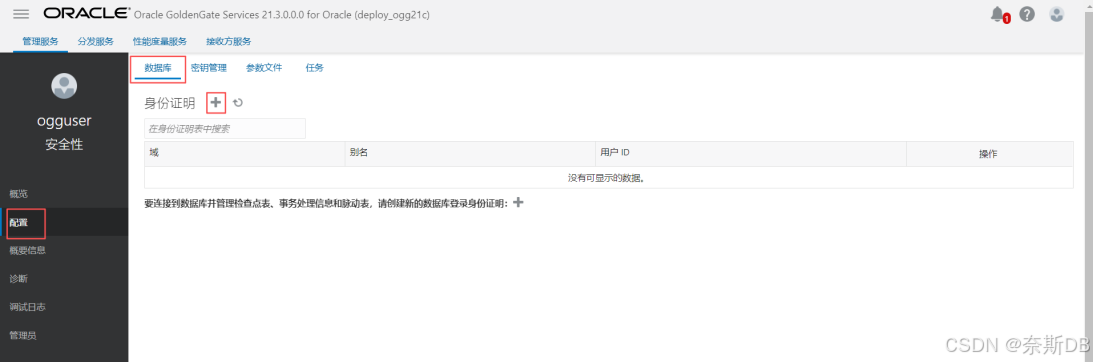
3.1 配置ogg微服务连接数据库
Oracle Goldengate MA微服务架构的组成部分,有五个主要组成部分:
- 服务管理器(Service Manager):7809
- 管理服务器(Administration Service):8001
- 分发服务器(Distribution Service):8002
- 接收器服务器(Receiver Service):8003
- 性能指标服务器(Performance Metrics Service):8004—8005
登录管理服务URL页面:<服务器IP地址>:8001
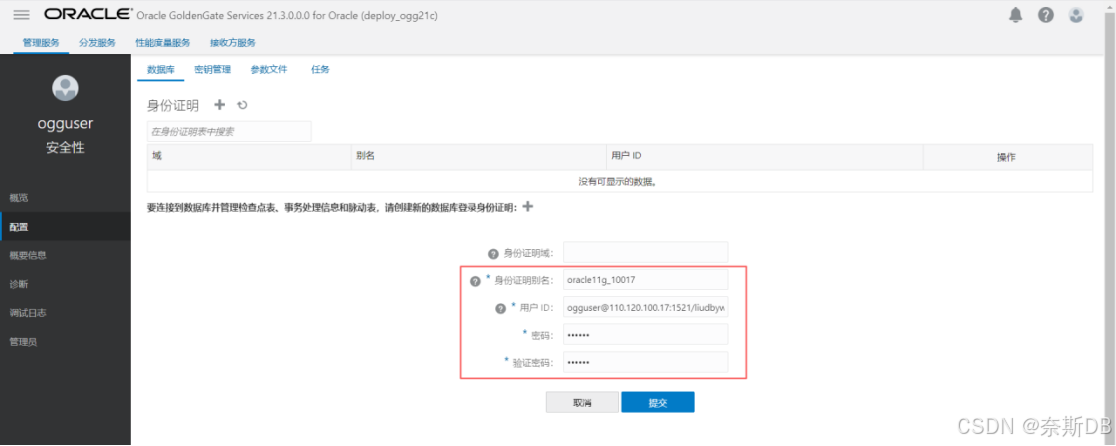
①配置源生产库:
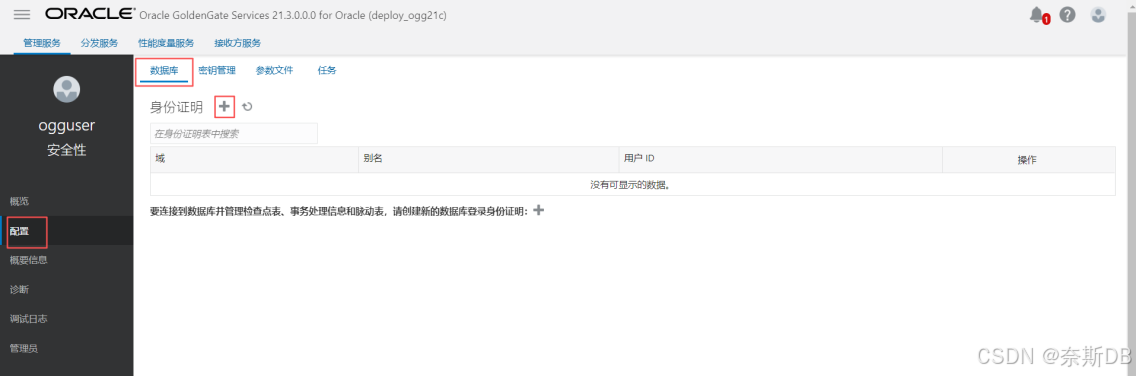
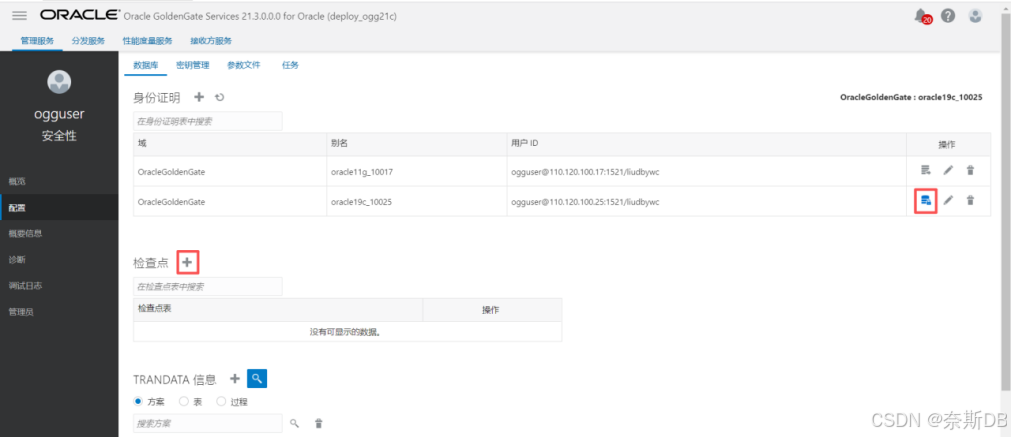
点击左上角菜单按钮,点击左边“配置” 选择“数据库”,点击“身份证明”旁边的 + - 建立数据库信任
用户ID格式为ogg专属数据库用户@<数据库ip地址>/<服务名>,点击“提交”
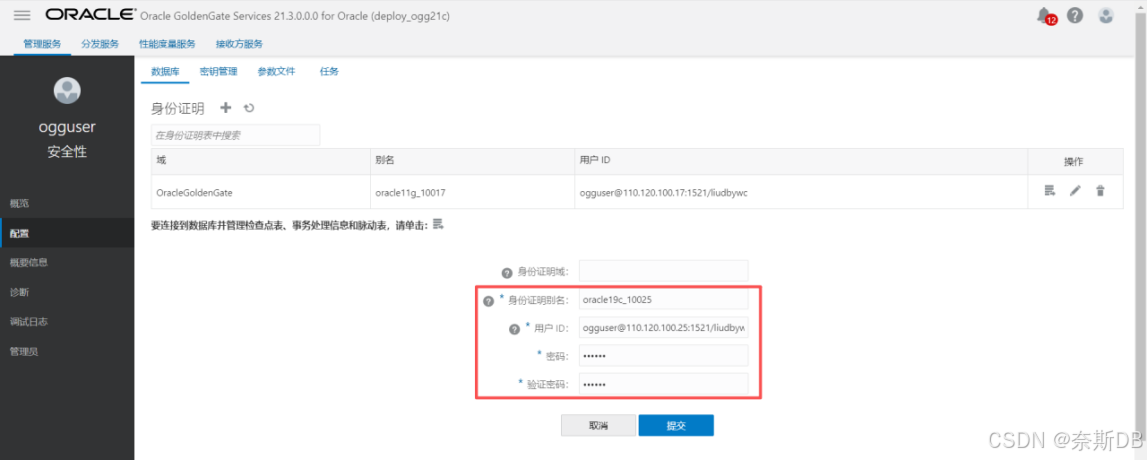
②配置ogg库:
点击左上角菜单按钮,点击左边“配置” 选择“数据库”,点击“身份证明”旁边的 + - 建立数据库信任
用户ID格式为ogg专属数据库用户@<数据库ip地址>/<服务名>,点击“提交”
3.2 配置源和ogg库的检查点表
检查点表是Oracle GoldenGate用于确保Extract(抓取进程)和Replicat(复制进程)在分布式环境下实现高可用和自动故障恢复的核心机制。作用如下:
- 核心作用:持久化进程状态
它的首要作用是持久化地记录进程的读取和写入位置。
- 对于Extract进程:检查点表记录了它已经从源数据库的哪些事务日志中读取了数据。这通常对应着SCN(系统变更号)或日志序列号。
- 对于Replicat进程:检查点表记录了它已经成功地将哪些事务应用到了目标数据库。这同样通过SCN或事务标识来记录。
没有检查点表会怎样?
- 在传统架构或未配置检查点表时,进程的状态信息默认存储在本地的一个文件(dirchk目录下)中。这在单机部署时没问题,但在微服务架构和容器化环境中,如果进程发生故障并在另一个节点上重启,它将无法访问原节点的本地文件,从而不知道从哪里开始继续工作,导致数据同步中断。
- 在微服务架构中的关键价值:实现高可用和弹性伸缩
这是检查点表最重要的意义所在。微服务架构强调服务的无状态化和可迁移性。
- 高可用:当运行Extract或Replicat的Pod(在Kubernetes中)或Docker容器因故崩溃,编排工具(如Kubernetes)会尝试在集群内的另一个健康节点上重新启动这个进程。由于检查点表存储在共享的、集中的数据库表中,新启动的进程可以立即从表中查询到自己上次成功处理到的位置,并从中断点继续工作,实现了无缝的故障转移,对业务几乎无感知。
- 弹性伸缩与滚动升级:在进行系统维护、版本升级或资源伸缩时,需要主动停止进程。检查点表确保了进程可以安全地停止和启动,而不会造成数据丢失或重复。
- 具体工作原理
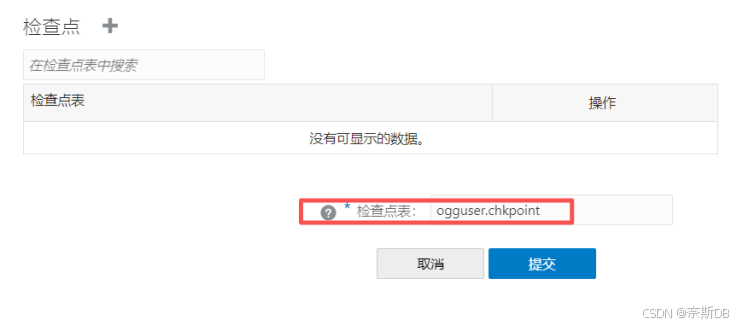
- ①创建表:DBA或运维人员需要在源端和目标端的专属ogg用户上分别创建一个专用的表(例如 chkpoint )。
- ②配置进程:在创建Extract或Replicat进程时,在其参数文件(./GLOBALS)中通过 CHECKPOINTTABLE 参数指定这个表的位置(如 checkpointtable ogguser.chkpoint )。
- ③定期写入:进程在运行期间,会定期(例如在事务边界)向这个表写入当前的读取或提交位置。
- ④故障恢复:当进程重启时,它首先连接到数据库,查询检查点表,获取上一次持久化的位置,然后从这个位置开始继续处理数据。
登录管理服务URL页面:<服务器IP地址>:8001
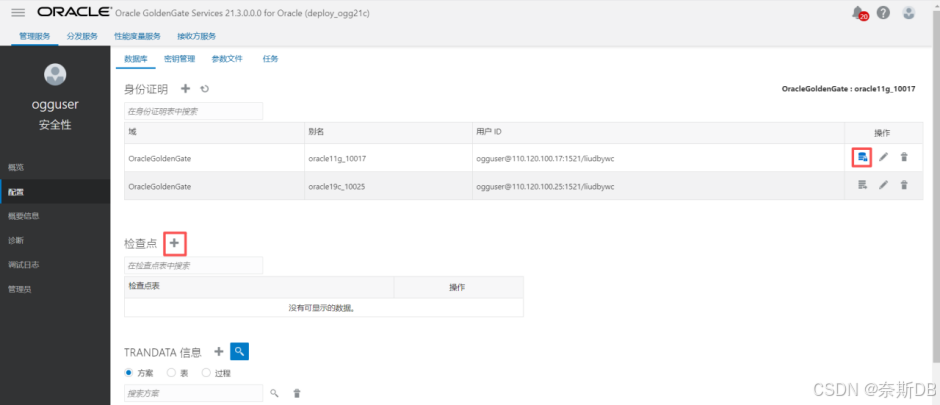
①配置源生产库:
上述配置完成后,点击右侧的“数据库连接”按钮,在出现如下连接数据库成功后,点击“检查点”旁边的+ - 添加检查点
在源生产库的专属ogg用户(ogguser)上创建一个专用的检查点表ogguser.chkpoint
②配置ogg库:
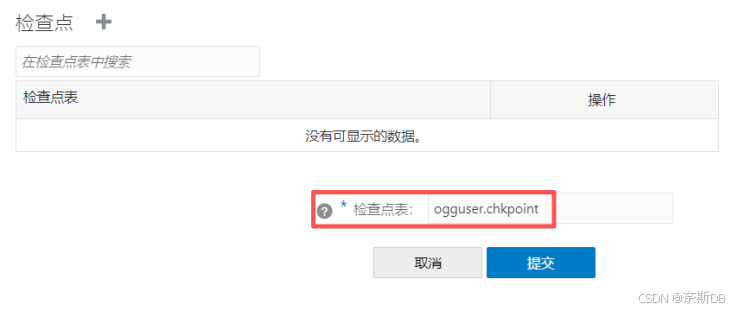
上述配置完成后,点击右侧的“数据库连接”按钮,在出现如下连接数据库成功后,点击“检查点”旁边的+ - 添加检查点
在源生产库的专属ogg用户(ogguser)上创建一个专用的检查点表ogguser.chkpoint
3.3 配置源和ogg库的增加补充日志
增加补充日志的原因:
即使已经执行了alter database force logging;(强日志写)和alter database add supplemental log data;(打开补充日志)这两个数据库级别的命令,仍然需要为每个需要复制的表单独执行ADD TRANDATA,如果是整个用户都需要复制,那么就需要在用户级别下执行ADD SCHEMATRANDATA,这是OGG提供的批量操作命令,用于为整个模式下的所有现有表一次性启用表级补充日志。
原因解析:层级和粒度不同
ALTER DATABASE FORCE LOGGING;
- 作用:确保数据库所有操作(包括直接路径加载等)都被记录到重做日志中。
- 解决的问题:防止因 NOLOGGING 操作导致的数据变更丢失,从而使得备库或OGG无法捕获到这部分数据。
- 层级:数据库级
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
- 作用:在数据库级别启用补充日志功能。这是一个总开关。
- 解决的问题:为后续更细粒度的补充日志设置打开可能性。单靠这个命令本身,并不能为任何表提供足够的补充日志信息。
- 层级:数据库级
ADD SCHEMATRANDATA [schema_name] 或者 ADD TRANDATA
- 作用:为指定的整个用户或者单个表启用足够强度和粒度的补充日志。补充日志不是OGG的功能,而是数据库本身的一项功能。它的作用是确保日志文件不仅记录数据发生了什么变化(INSERT, UPDATE, DELETE),还能记录足够的信息来唯一标识被修改的行的前后映像。
- 为什么需要补充日志:默认的日志不够用,数据库重做日志默认只为保证数据库自身恢复而设计。例如,对于一个UPDATE操作,它可能只记录被修改的字段,而不是整行数据。
- OGG的特殊需求:OGG需要从日志中重建SQL语句在目标端执行。如果没有补充日志,可能会遇到:
①无法识别唯一行:如果表没有主键,OGG无法在目标数据库找到对应的行进行update更新或delete删除。
②数据不一致:在UPDATE操作中,如果只记录了变更字段,目标端将无法完整复制“修改前”和“修改后”的整行数据。
登录管理服务URL页面:<服务器IP地址>:8001
①配置源生产库:
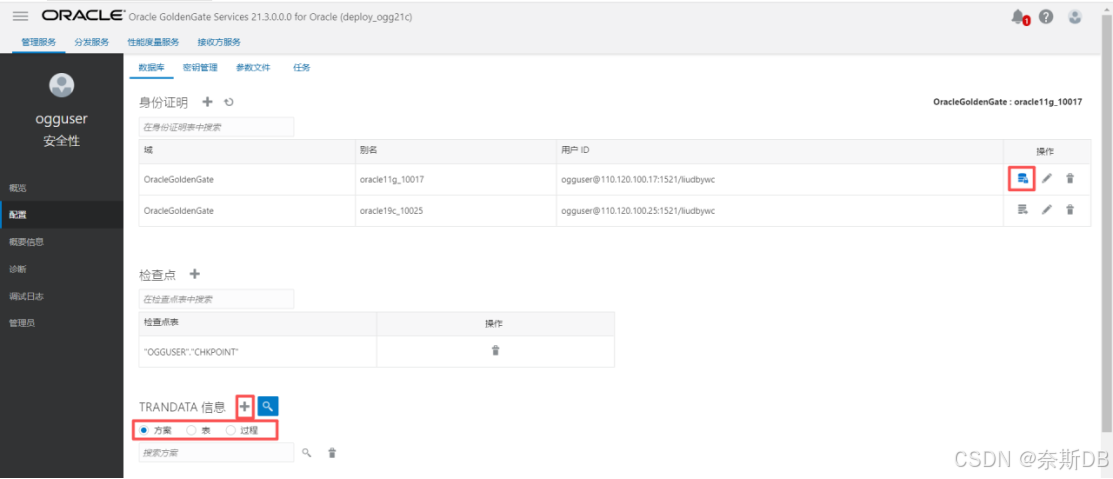
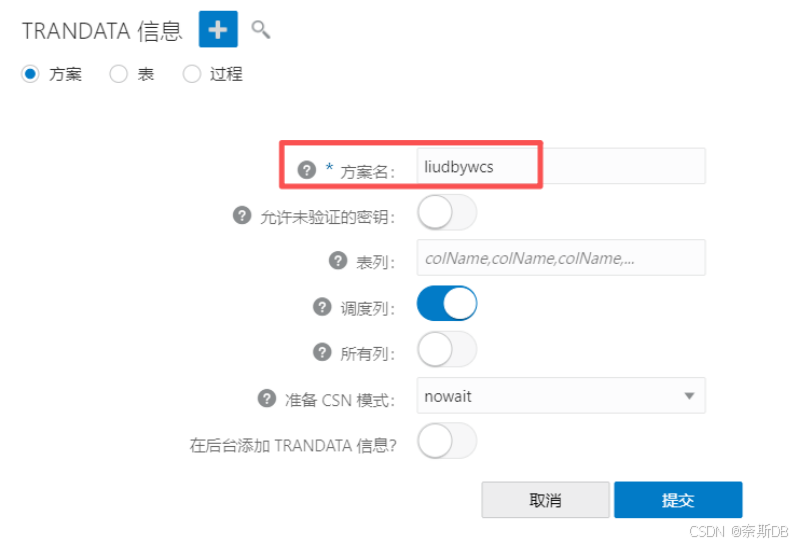
同步的整个liudbywcs用户到ogg库,在“TRANDATA信息”处选择“方案”,然后 + - 添加
点击“搜索”图标,搜索添加的用户liudbywcs
②配置ogg库:
需要注意:增加补充日志操作是只在ogg库回同步至源生产库或者同步至其他库时才需要配置的,因为同步来自ogg库上的DML和DDL操作同样是需要打开强日志写、补充日志等一系列操作的。反之如果不需要同步至源生产库或者同步至其他库则不需要配置增加补充日志操作。
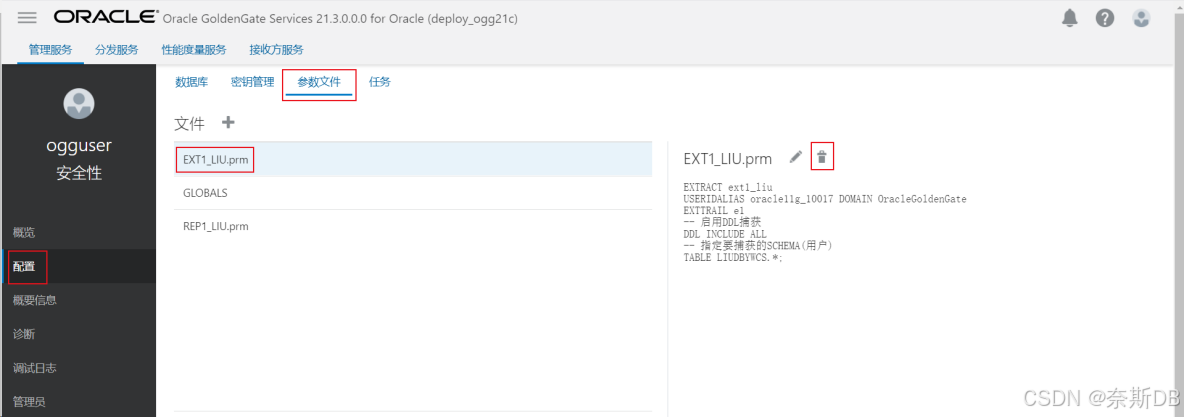
3.4 查看所有的参数文件
这里可以看到所有的全局参数文件GLOBALS、抽取进程文件EXTRACT、复制进程文件REPLICAT等所有的参数文件,这里可以进行删除。
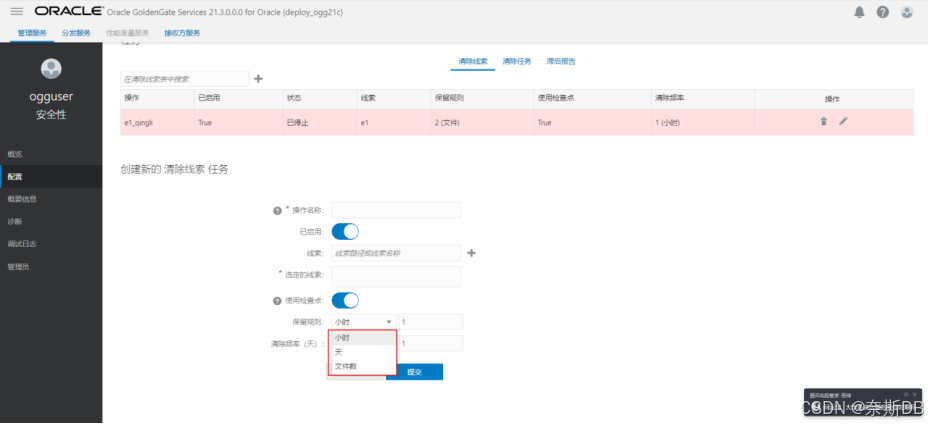
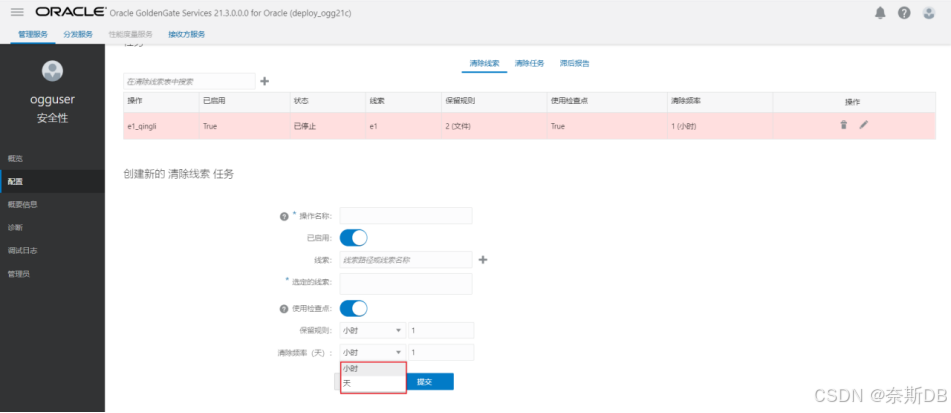
3.5 清理队列(线索)
指定“线索名称”,指定保留规则或者清理频率。
- 保留规则:规则可以为小时、天、文件数。
- 清理频率(天):频率可以为小时、天

四、在ogg微服务页面配置源生产库抽取进程
4,1 源生产库的抽取进程
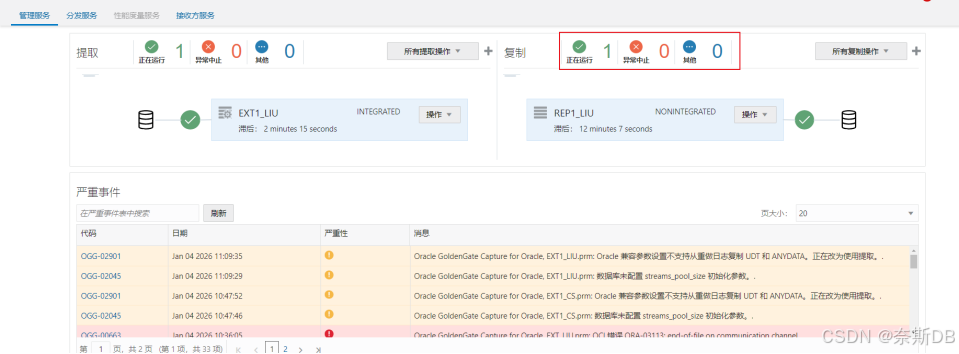
登录管理服务URL页面:<服务器IP地址>:8001
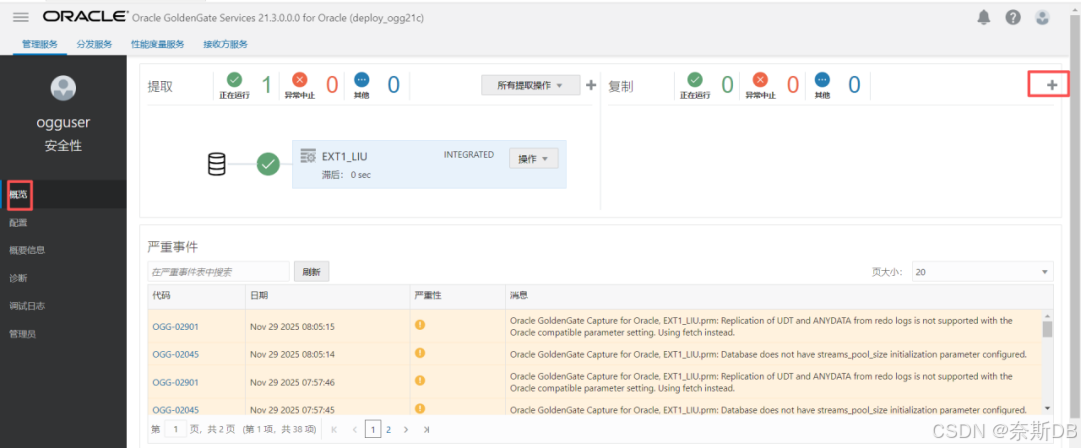
回到“概述”界面,点击“提取”旁边的+ - 添加提取进程
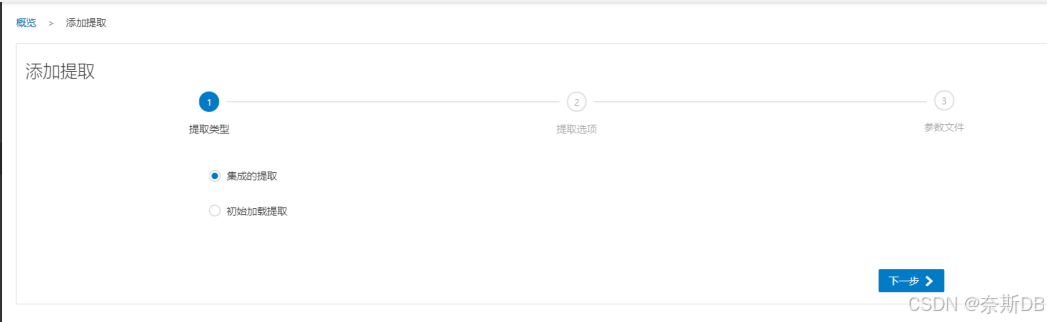
选择提取类型,此处选择默认的“集成的抽取”
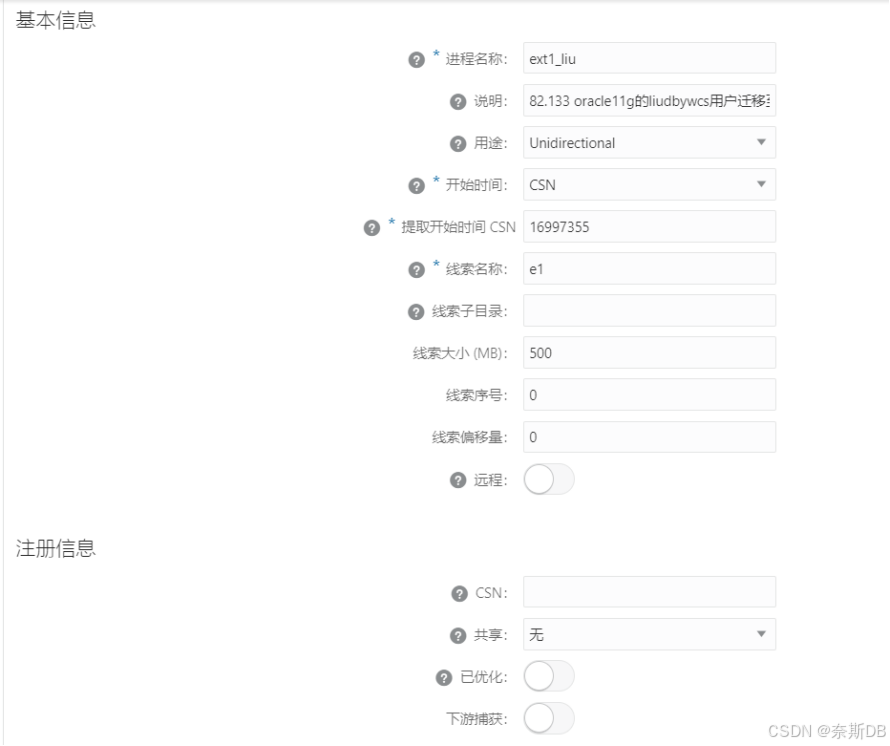
抽取进程的添加内容如下
- ①进程名称 — 抽取进程的名称,一般以ext开头命名,8位字符以内
- ②说明 — 对个抽取进程的补充说明
- ③开始时间 — 选择“SCN”,需要先配置数据初始化,然后配置抽取进程。因为需要先获取导出时的SCN,然后配置抽取进程时指定这个CSN,让抽取进程只复制这个SCN之后的数据,以便可以清楚观察到导出之后操作了多少数据,也就是抽取进程抽取了多少数据,那么复制进程就完全复制,这样就可以在微服务的统计信息界面对复制进程和抽取进程进行核对。如果先配置了抽取进程,这时不清楚需要从那个SCN开始抽取数据,就只能选择从“现在”开始抽取数据,那么抽取中的统计信息就会比导出时的那个点的SCN数据要多,就不能对比抽取进程和复制进程的统计信息了,因为抽取进程比导出时的SCN要小,抽取进程抽取的数据要多。抽取进程支持从现在、定制时间、CSN抽取数据
- ④提取开始时间 CSN — 导出时的CSN 号
- ⑤线索名称 — 它明确指定了哪个源端的 Extract(抓取进程) 产生的数据,应该发送给哪个目标端的 Receiver Service(接收服务) 和 Replicat(复制进程)。详解介绍一下线索名称:
集中管理:
在微服务架构中,您不再需要像经典架构那样在多个配置文件中手动配置Extract的传输参数和Replicat的源定义。所有这些连接信息都通过Web界面在一个统一的“线索”中进行可视化的创建和管理。- ⑥共享 — 选择“无”,解决“0GG-08238|错误: 此数据库缺少必需的补丁程序,不能支持 SHARE 子句。删除 SHARE 子句”报错
- ⑦身份证明域 — 只有一个选项,选择“OracleGoldenGate”
- ⑧身份证明别名 — 配置ogg微服务连接数据库时的别名,这里就是源生产库
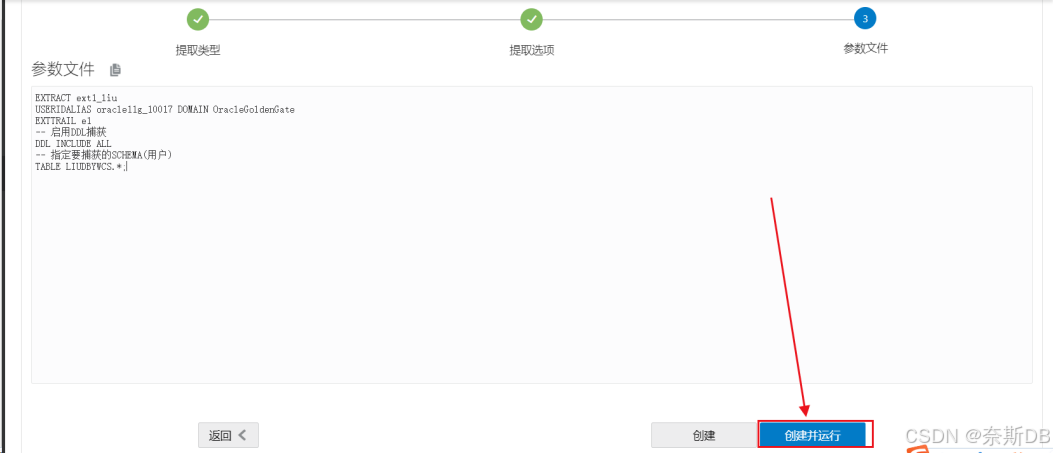
抽取进程的参数配置如下,然后创建并运行
EXTRACT ext1_liu USERIDALIAS oracle11g_10017 DOMAIN OracleGoldenGate EXTTRAIL e1 -- 启用DDL捕获 DDL INCLUDE ALL -- 指定要捕获的SCHEMA(用户) TABLE LIUDBYWCS.*;
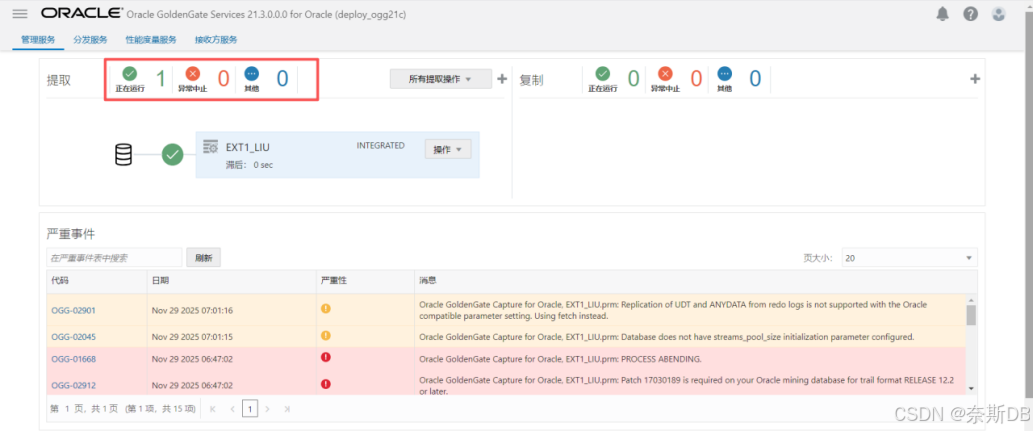
查看到抽取进程正常运行
五、数据初始化(expdp/impdp方式),以及配置DDL过程
5.1 数据初始化:
配置生产数据的初始化。上面的操作只是配置ogg相关参数,并且测试的数据是因为配置了ogg功能之后才同步的,所以生产数据的初始化需要另行配置 【并且ogg库需要有原库表的结构才能同步,不然报ERROR OGG-00199 Table itpux.ITPUX_M5 does not exist in target database(配置了DDL功能除外)】
采用impdp方式初始化ogg数据,适用于TB级的不同操作系统,数据库版本之间的数据初始化。
注意:需要先配置数据初始化,然后配置抽取进程。因为需要先获取导出时的SCN,然后配置抽取进程时指定这个CSN,让抽取进程只复制这个SCN之后的数据,以便可以清楚观察到导出之后操作了多少数据,也就是抽取进程抽取了多少数据,那么复制进程就完全复制,这样就可以在微服务的统计信息界面对复制进程和抽取进程进行核对。如果先配置了抽取进程,这时不清楚需要从那个SCN开始抽取数据,就只能选择从“现在”开始抽取数据,那么抽取中的统计信息就会比导出时的那个点的SCN数据要多,就不能对比抽取进程和复制进程的统计信息了,因为抽取进程比导出时的SCN要小,抽取进程抽取的数据要多。① 源生产库:使用expdp
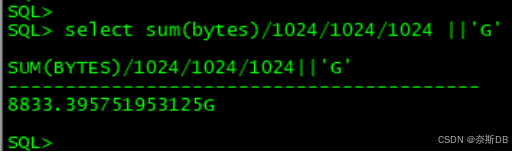
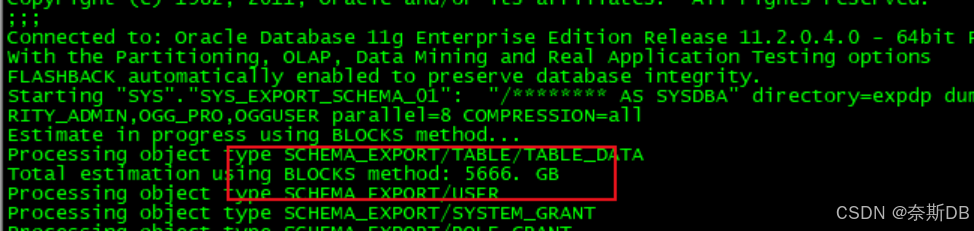
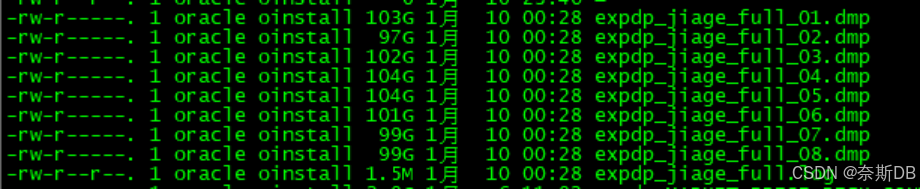
统计10个用户的数据量,总计8.8TB
对10个用户进行数据导出expdp "/ as sysdba" directory=expdp dumpfile=expdp_jiage_full_%U.dmp logfile=expdp_jiage_full.log schemas=PART_CLOUD_PRICE,PRICE_FACTORY,PJ_VIEW,PJBJ_JY,ORACLE_EXPORTER,SYS_ADMIN,AUDIT_ADMIN,SECURITY_ADMIN,OGG_PRO,OGGUSER parallel=8 COMPRESSION=all总计需要导出5.6TB的数据量,上面统计的是8.8TB,因为此库运行了多年,进行了大量的DML操作,因此有非常高的高水位,通过expdp/impdp逻辑导出导入可以解决高水位的问题
5.6TB的数据导出耗时6小时半,因此通过数据泵导出TB级别的实例还是非常快的
3)查看导出文件的大小
5.6TB的数据量,使用压缩参数压缩成了800GB,压缩比较还是非常高的
4)导入异机之前创建表空间
impdp导入之前,需要在目标数据库上创建相应表空间对象即可;而对于imp导入时需要在目标数据库上创建相应的用户、权限、表空间等对象。
5)impdp导入ogg库
小提示:源生产库的数据库版本为oracle11g,ogg库是oracle19c,使用数据泵时可以直接进行导入。
impdp "/ as sysdba" directory=EXPDP dumpfile=expdp_jiage_full_01.dmp,expdp_jiage_full_02.dmp,expdp_jiage_full_03.dmp,expdp_jiage_full_04.dmp,expdp_jiage_full_05.dmp,expdp_jiage_full_06.dmp,expdp_jiage_full_07.dmp,expdp_jiage_full_08.dmp logfile=impdp_jiage_full.log full=y parallel=8 ###导入详情查看impdp_jiage_full.log日志5.6TB的数据量导入总计耗时1天23小时,整体还是很快的
5.2 配置DDL过程,以及模拟DDL操作的同步
ogg默认是不支持同步DDL操作,这也是为什么要在ogg库手动创建表的原因。
但通过ogg 21c同步oracle 11g到oracle 11g中不需要执行多个相关DDL sql脚本,只需要在抽取进程和复制进程中配置同步DDL操作的参数,如下是抽取进程和复制进程配置同步DDL参数的简要介绍:DDL INCLUDE ALL ---包含所有的DDL操作 --DDL INCLUDE OBJNAME "LIUDBYWCS.*" ---包含LIUDBYWCS.*所有的对象(和DDL INCLUDE ALL使用任意一个即可) DDLOPTIONS ADDTRANDATA,REPORT ---DDLOPTIONS ADDTRANDATA: 有新表加入时自动加入附加日志; REPORT: 生成附件日志报告模拟12种DDL操作的同步如下:前提是已经配置了抽取进程、复制进程、并配置DDL功能
① 重启抽取进程和复制进程
因为对进程进行了停止并启动的操作,详细信息中的内容都会被清空,便于通过页面观察DDL操作是否被完全同步
② 生产库模拟12种DDL操作的同步
01.create table、insert、update、delete(DDL配置后可以同步操作)



六、在ogg微服务页面配置ogg库复制进程(微服务的复制进程不支持指定CSN复制数据)
注意:需要等到impdp导入完成之后再进行ogg库复制进程的配置,因为如果impdp没有导入完成就开始进行ogg数据复制,可能会导致数据顺序不一致。
6.1 配置ogg库的复制进程
登录管理服务URL页面:<服务器IP地址>:8001
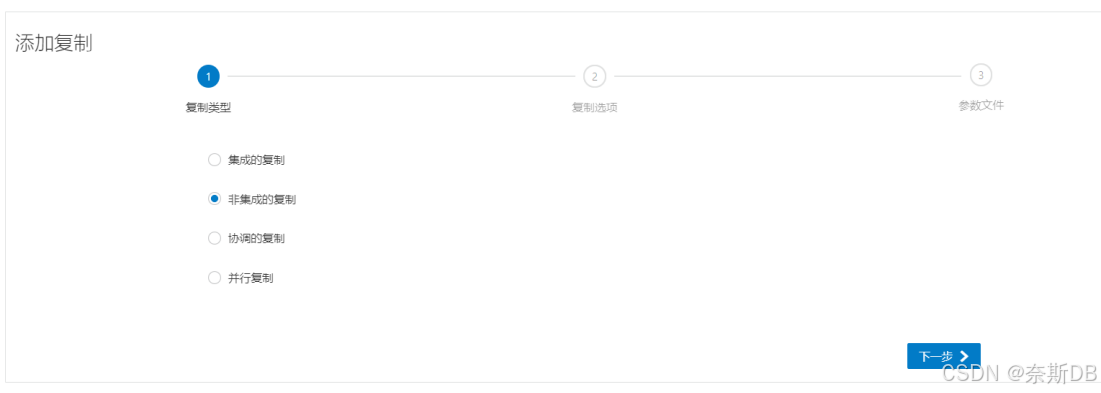
回到“概述”界面,点击“复制”旁边的+ - 添加进程
选择复制类型,此处选择的“非集成的复制”
复制进程的添加内容如下
- ①进程名称 — 抽取进程的名称,一般以rep开头命名,8位字符以内
- ②说明 — 对个复制进程的补充说明
- ③身份证明域 — 只有一个选项,选择“OracleGoldenGate”
- ④身份证明别名 — 配置ogg微服务连接数据库时的别名,这里就是ogg库
- ⑤源 — 选择“线索”
- ⑥线索名称 — 要复制那个线索就填入那个线索,抽取进程到e1,那么这里就从e1复制
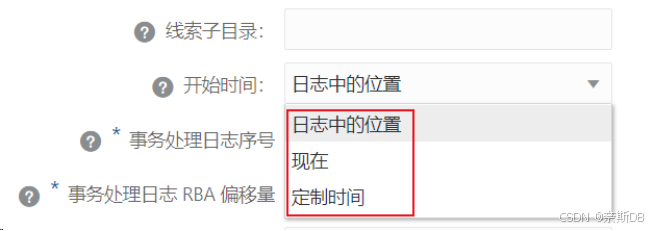
- ⑦开始时间 — 正常要选择scn的,但是没有。只能选择“日志中的位置”,在上面,抽取进程是新创建的,所以“线索文件”也是从零开始进行生成的,因此从默认的事务处理日志序号 0、事务处理日志 RBA 偏移量 0开始复制抽取的数据就可以完全复制抽取的数据了。如果选择了“现在”,也就是从添加好复制进程后立刻开始复制抽取进程中定义的对象数据,这样就会有一个问题,复制是添加好复制进程后开始的,但抽取进程已经运行一段时间了,导致复制的数据比抽取的要少,发生了数据不一致(亲测),因此不要选择“现在”。复制进程支持从日志中的位置、现在、定制时间,不支持指定CSN复制数据
需要注意:参数文件也不支持配置scn相关参数,如果加上参数会报错“OGG-10144 (REP1_LIU.prm) line 4: Parameter [aftercsn] is not valid for this configuration.”- ⑧检查点表 — 选择检查点表
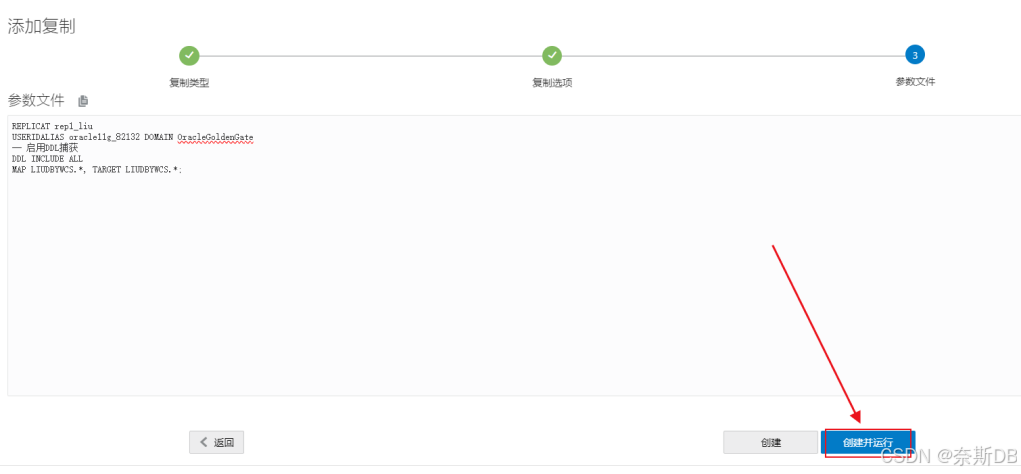
复制进程的参数配置如下,然后创建并运行REPLICAT rep1_liu USERIDALIAS oracle19c_10025 DOMAIN OracleGoldenGate -- 自动过滤重复时间内的数据冲突,用于不能停机执行初始化。这加上参数是因为采用了“先采用配置抽取进程(无法指定scn)然后直接通过expdp/impdp导出数据(无需指定scn相关参数)【配置抽取进程和expdp操作尽可能的近,这样会让多的数据尽可能的少】”的方式,而没有按照标准的第五、六步,采用这样的话不清楚需要从那个SCN开始抽取数据,选择从“现在”开始抽取数据,那么抽取中的统计信息就会比expdp导出时的那个点的SCN数据要多,因此复制进程也会多数据,多的数据通过handlecollisions参数忽略掉。注意:此参数解决的是抽取多了的数据自动过滤而不让报错的问题,因为不配置的话,一启动复制进程就会报错,配置上的话对于重复数据而言会重复执行并不会忽略,然后等数据复制稳定之后就必须将这个参数去掉,因为不能一直让冲突的数据去忽略,而是解决问题【需要注意:在页面可以直接将参数删掉,但是运行中的复制进程并不会生效,因此需要重启一下复制进程才能生效(亲测)】,去掉参数需要重启进程,参考下面的第八步:2、去掉handlecollisions参数 handlecollisions -- 启用DDL捕获 DDL INCLUDE ALL MAP LIUDBYWCS.*, TARGET LIUDBYWCS.*;
查看到复制进程正常运行