Ubuntu系统下服务器nvidia-smi缺失GPU问题修复与异常系统日志清理
Ubuntu系统下nvidia-smi缺失GPU问题修复与异常系统日志清理
- 前言
- 1.GPU缺失问题
- (1) 运行nvidia-smi -L,查看GPU的具体识别情况
- (2) 运行lspci | grep -i -E 'nvidia|3d controller|vga'
- (3) 运行dmesg -T | grep -iE 'nvrm|nvidia|xid|pcie|aer|fatal|gpu|fallen off' | tail -n 100,查看有无GPU内核报错
- (4) 依次执行如下命令,看GPU是否恢复
- 2.系统日志异常(/var/log/syslog和/var/log/kern.log)
- (1) 编辑轮转系统日志文件
- (2) 执行日志轮转
- 小结
前言
前两天服务器遇到nvidia-smi命令中GPU显示不全的问题,该问题也直接导致系统日志异常写入。经过一番折腾,成功修复问题,现将这一经验分享给各位朋友。当然,真心希望大家都不会遇到这样的问题!
1.GPU缺失问题
其实这个问题之前没太在意,主要是由于系统日志异常写入导致系统盘容量不足才发现的。终端执行nvidia-smi命令时,出现如下界面:
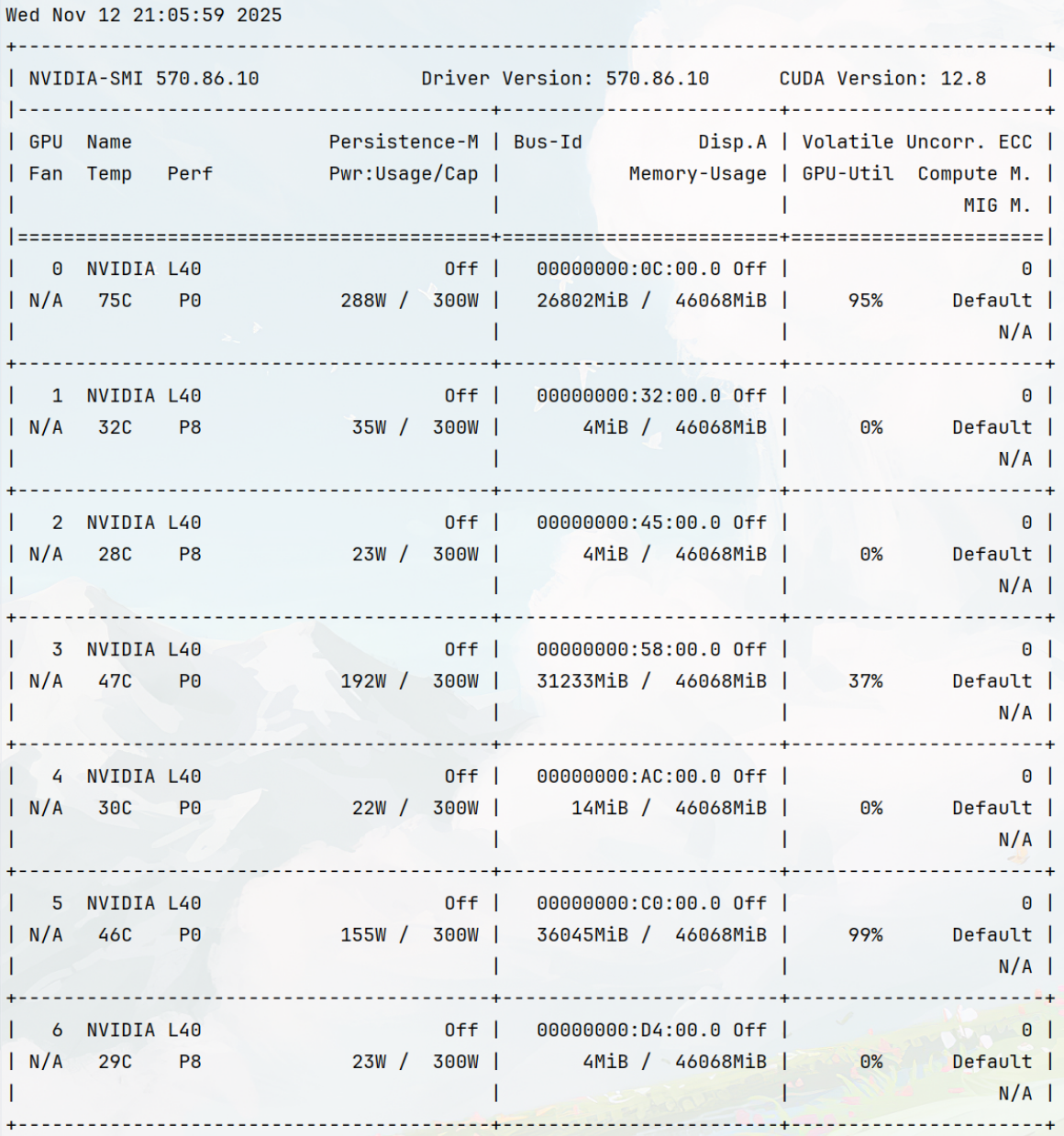
可以看到,只显示了0-6号GPU,第8块卡即7号GPU消失不见。
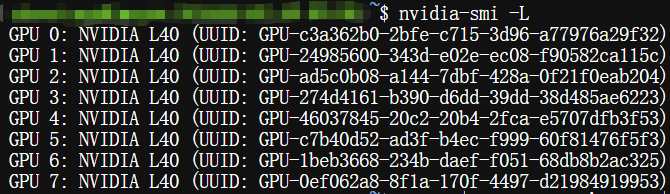
(1) 运行nvidia-smi -L,查看GPU的具体识别情况
$ nvidia-smi -L
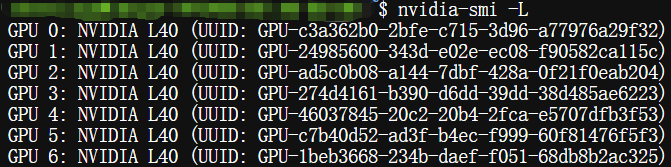
依然是找不到7号卡,尝试使用下一条命令,看看PCIe 层面能否定位到所有GPU。
(2) 运行lspci | grep -i -E ‘nvidia|3d controller|vga’
$ lspci | grep -i -E 'nvidia|3d controller|vga'
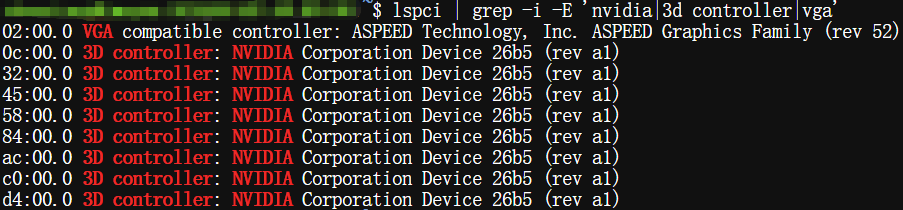
可以看到,8块卡都还是在的,这就比较好办,通常就是驱动没bind到GPU,多半就是驱动异常的问题,下面就可以针对性地进行解决。
如果这一步命令也没有识别到对应GPU的话,那么就可能是硬件层面的问题了。
(3) 运行dmesg -T | grep -iE ‘nvrm|nvidia|xid|pcie|aer|fatal|gpu|fallen off’ | tail -n 100,查看有无GPU内核报错
$ dmesg -T | grep -iE 'nvrm|nvidia|xid|pcie|aer|fatal|gpu|fallen off' | tail -n 100
输出的信息中包含如下关键部分:
[三 11月 12 21:40:48 2025] NVRM: kgspWaitForGfwBootOk_TU102: (the GPU may be in a bad state and may need to be reset)
[三 11月 12 21:40:48 2025] NVRM: nvCheckOkFailedNoLog: Check failed: Call timed out [NV_ERR_TIMEOUT] (0x00000065) returned from kgspWaitForGfwBootOk_HAL(pGpu, pKernelGsp) @ kernel_gsp.c:3669
[三 11月 12 21:40:48 2025] NVRM: RmInitAdapter: Cannot initialize GSP firmware RM
[三 11月 12 21:40:48 2025] NVRM: GPU 0000:84:00.0: RmInitAdapter failed! (0x62:0x65:1860)
[三 11月 12 21:40:48 2025] NVRM: GPU 0000:84:00.0: rm_init_adapter failed, device minor number 4
其中,**“0000:84:00.0”**即为缺失的GPU,需要对其进行恢复。可以注意到,其对应GPU编号为4,即掉了驱动的其实是4号GPU,而nvidia-smi命令是顺延显示了后面几块没问题的显卡。
(4) 依次执行如下命令,看GPU是否恢复
ls -l /sys/bus/pci/devices/0000:84:00.0/reset
echo 1 | sudo tee /sys/bus/pci/devices/0000:84:00.0/reset
查看GPU识别结果
nvidia-smi -L
上述命令也可以打包一块执行:
[ -f /sys/bus/pci/devices/0000:84:00.0/reset ]
&& echo 1 | sudo tee /sys/bus/pci/devices/0000:84:00.0/reset
&& dmesg -T | tail -n 80
&& nvidia-smi -L
成功识别到4号GPU,再运行一次nvidia-smi。
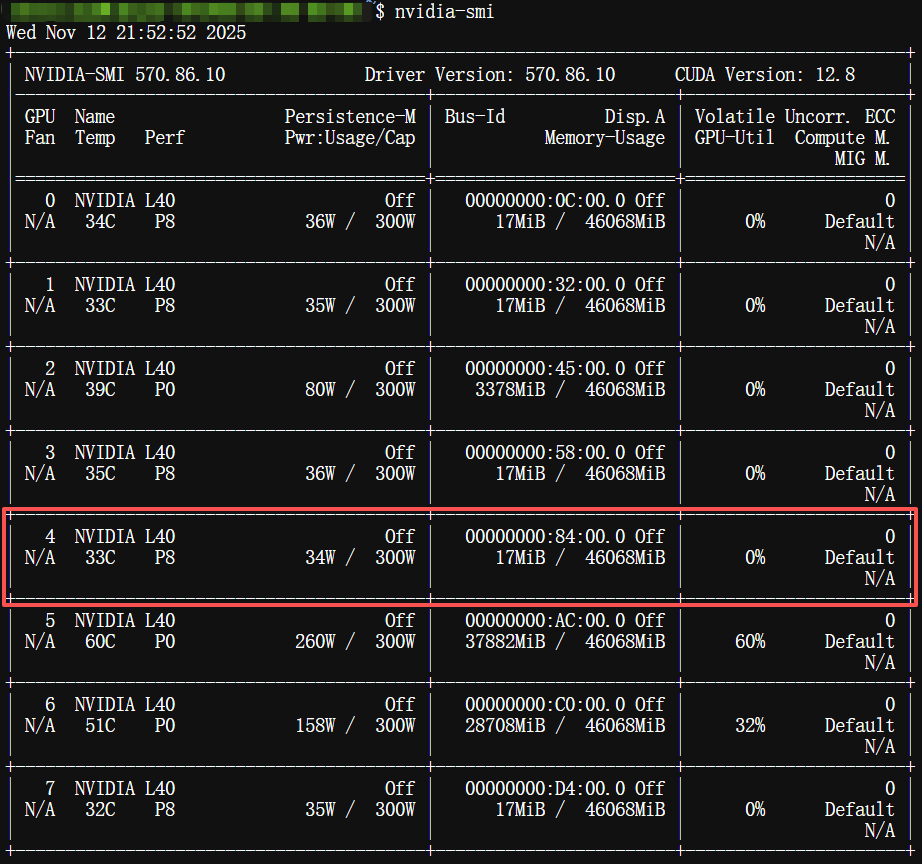
全部GPU显示正常!至此,GPU无法识别的问题得以解决。
2.系统日志异常(/var/log/syslog和/var/log/kern.log)
这是连锁反应,由于GPU突然掉了一个驱动,导致内核日志异常写入,同时导致syslog的异常写入。在发现日志异常写入后,首先对日志进行了即时轮转,而后才对GPU问题进行了修复。
(1) 编辑轮转系统日志文件
sudo vim /etc/logrotate.d/rsyslog
修改/var/log/syslog和/var/log/kern.log的相关内容:
/var/log/syslog
{
daily
rotate 7 # 保留日志7天
size 50M # ≥50MB 就轮转
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
/usr/lib/rsyslog/rsyslog-rotate
endscript
}
/var/log/kern.log
{
daily
rotate 7
size 50M
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
/usr/lib/rsyslog/rsyslog-rotate
endscript
}
(2) 执行日志轮转
sudo logrotate -f /etc/logrotate.conf,logrotate.conf
至此,原先/var/log/下的syslog和kern.log分别变为syslog.1和kern.log.1,可以手动进行清理,释放空间。
小结
本次问题主要是由于服务器中一块GPU突然掉驱动引起的错误,同时也导致系统日志的问题,按顺序进行解决即可。若异常写入的日志文件较大,可先进行轮转清理,将空间释放出来,再对GPU进行修复,修复完成后再执行一次日志轮转即可。