数据流向与 Nginx:从命令行到服务器的资源调度逻辑
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、数据流向
- 1. 数据流向(Data Flow)的核心概念
- 2. 三个核心概念(所有数据流向的基础)
- 3. 命令行中的数据流向 ⭐⭐
- 3.1 三个默认 “数据通道”(系统自带的 “水管”)
- 3.2 默认数据流向(不用任何参数时的默认规则)
- 3.3 用 “重定向” 改变数据流向(> >> < 符号)
- 3.4 用 “管道” 连接多个命令(| 符号):数据 “流式处理”
- 4. 通用数据流向的 3 种常见模式(不止命令行能用)
- 4.1 单向流向(最基础)
- 4.2 分支流向(一个数据源→多个目的地)
- 4.3 串联流向(多处理环节→链式传递)
- 5. 数据流向实例讲解
- 6. 静态资源及动态资源
- 6.1 核心定义
- 6.2 关键区别
- 6.3 部署与优化小技巧
- 6.3.1 静态资源优化(核心:缓存 + CDN)
- 6.3.2 动态资源优化(核心:减少计算 + 数据库优化)
- 小结
- 二、Nginx
- 1. Nginx概念
- 2. 安装服务方式
- 3. Nginx安装教程(属于源码包安装形式)
- 补充说明:
- 总结
前言
在 Linux 运维与 Web 服务领域,“数据流向” 和 “Nginx” 是两个贯穿始终的核心逻辑。数据流向决定了信息在系统中的传输路径,从键盘输入到文件存储,从命令行筛选到服务端响应,每一步都离不开对 “来源 - 处理 - 目的地” 的把控;而 Nginx 作为高性能服务器,是数据流向的 “智能调度器”,通过静态资源管理、反向代理、负载均衡,让数据在用户与服务间高效流转。理解二者的联动,是掌握 Linux 服务部署与 Web 架构的关键。
一、数据流向
1. 数据流向(Data Flow)的核心概念
数据在 “来源” 和 “目的地” 之间的传输路径与方向—— 就像水从水龙头(来源)流到杯子(目的地),中间可能经过水管、过滤器(数据处理环节),数据也会从 “产生源头” 出发,经过处理 / 转换,最终到达 “存储 / 使用的地方”。
之前学的 Shell 脚本、命令行操作中,数据流向是最常用的场景,重点聚焦能直接用到的 “命令行数据流向” 和 “通用数据流向逻辑”。
2. 三个核心概念(所有数据流向的基础)
不管是命令行、程序开发还是系统架构,数据流向都离不开这 3 个要素:
| 要素 | 通俗解释 | 类比(水流) | 命令行中对应的载体 |
|---|---|---|---|
| 数据源(Input) | 数据的 “产生地”,数据从这出发 | 水龙头、河流源头 | 键盘输入、文件、命令输出 |
| 数据处理(Process) | 对数据做 “筛选、转换、计算” 的环节 | 净水器、水管阀门 | grep、sed、awk 等命令 |
| 数据目的地(Output) | 数据最终 “存放 / 使用” 的地方 | 杯子、水桶、下水道 | 屏幕、文件、另一个命令 |
简单说:
- 数据源 → 数据处理 → 数据目的地,这就是最基础的 “单向数据流向”。
- 复杂场景可能多环节处理、多目的地,但核心逻辑不变。
3. 命令行中的数据流向 ⭐⭐
在 Shell 命令行中,数据流向的核心是 “标准输入(stdin)、标准输出(stdout)、标准错误(stderr)” 这 3 个 “默认通道”,再加上**重定向(> >> <)和管道(|)**来控制流向,逐个拆解如下:
3.1 三个默认 “数据通道”(系统自带的 “水管”)
系统给每个命令都默认分配了 3 个 “隐形水管”,数据通过这 3 个管道传输,不用手动创建:
| 通道名称 | 作用(数据流向) | 符号标识 | 类比(生活场景) |
|---|---|---|---|
| 标准输入(stdin) | 数据 “流入” 命令(命令从这拿数据) | 0 | 你往咖啡机里加咖啡豆(命令的 “原料”) |
| 标准输出(stdout) | 命令执行成功后,数据 “流出” 到这 | 1 | 咖啡机制好的咖啡(命令的 “正常结果”) |
| 标准错误(stderr) | 命令执行失败后,错误信息 “流出” 到这 | 2 | 咖啡机故障提示(命令的 “异常结果”) |
3.2 默认数据流向(不用任何参数时的默认规则)
当你直接在命令行敲命令(比如 ls、grep “test” file.txt),数据会按默认规则流动:
标准输入(stdin):默认来自 键盘(比如你敲 read name 命令时,输入的内容就是从键盘流入);
标准输出(stdout):默认流向 屏幕(比如 ls 命令的结果、echo “hello” 的输出,都显示在屏幕上);
标准错误(stderr):默认也流向 屏幕(比如 ls /不存在的目录 报错,错误信息直接显示在屏幕)。
示例:
# 1. echo "hello":数据从 echo 命令(数据源)流出到 stdout(屏幕)
echo "hello" # 屏幕输出 hello(stdout 流向屏幕)
# 2. ls /tmp:命令读取 /tmp 目录信息(数据源是目录),stdout 流向屏幕
ls /tmp # 屏幕输出 /tmp 下的文件(正常结果)
# 3. ls /not_exist:命令执行失败,stderr 流向屏幕
ls /not_exist # 屏幕输出错误信息(ls: 无法访问 '/not_exist': 没有那个文件或目录)
3.3 用 “重定向” 改变数据流向(> >> < 符号)
默认流向是 “屏幕 / 键盘”,用重定向符号可以把数据 “改道” 到文件,或从文件读取数据(不用手动输入),这是脚本中最常用的技巧:
| 符号 | 作用(数据流向) | 示例命令 | 效果说明 |
|---|---|---|---|
> | 标准输出(stdout)重定向到文件(覆盖文件) | ls /tmp > file_list.txt | 把 ls /tmp 的结果(原本显示在屏幕)写入 file_list.txt,如果文件已存在,覆盖原有内容 |
>> | 标准输出(stdout)重定向到文件(追加内容) | echo “新内容” >> file_list.txt | 把 “新内容” 追加到 file_list.txt 末尾,不覆盖原有内容 |
< | 标准输入(stdin)重定向到文件(从文件读数据) | grep “ERROR” < error.log | 原本 grep 从键盘读数据,现在改成从 error.log 读,相当于 grep “ERROR” error.log |
2> | 标准错误(stderr)重定向到文件(单独存错误) | ls /not_exist 2> error_msg.txt | 把错误信息写入 error_msg.txt,屏幕不显示错误 |
&> | 标准输出 + 标准错误一起重定向到文件 | ./script.sh &> script.log | 脚本的正常输出和错误信息都写入 script.log,屏幕干净 |
示例拆解(用sed 修改文件,本质也是数据流向):
# 场景:把 grep 筛选的结果,追加到日志文件
grep "ONBOOT" ifcfg-ens33 >> result.log
数据流向:ifcfg-ens33 文件(数据源)→ grep 命令(处理:筛选含 ONBOOT 的行)→ result.log 文件(目的地,追加内容)
3.4 用 “管道” 连接多个命令(| 符号):数据 “流式处理”
管道的作用是 “把前一个命令的标准输出(stdout),直接作为后一个命令的标准输入(stdin)”—— 相当于把两个命令的 “水管” 连起来,数据不用落地到文件,直接 “流式传递”,效率极高。
类比:就像 “先用水龙头放水→净水器过滤→直接流入杯子”,水不经过中间的桶,直接从过滤环节到杯子。
示例(“筛选合法 IP” 命令):
grep -E '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' error.log | awk -F '.' '$1<=255 && $2<=255 && $3<=255 && $4<=255'
数据流向拆解:
- 数据源:error.log 文件;
- 第一个处理命令:grep …(筛选出 “疑似 IP 格式” 的行,stdout 输出这些行);
- 管道(|):把 grep 的 stdout 直接传给 awk 的 stdin;
- 第二个处理命令:awk …(校验 IP 数值是否在 0-255,stdout 输出合法 IP);
- 数据目的地:默认是屏幕(也可以用 > valid_ip.txt 重定向到文件)。
4. 通用数据流向的 3 种常见模式(不止命令行能用)
除了命令行,不管是写脚本、做数据处理还是理解系统架构,数据流向都逃不开这 3 种模式,用命令行例子对应:
4.1 单向流向(最基础)
- 逻辑:数据源 → 单个处理 → 单个目的地
- 例子:
sed -i 's/no/yes/' ifcfg-ens33
(数据源:ifcfg-ens33 文件 → 处理:sed 替换 → 目的地:原文件) - 类比:水龙头→水管→杯子(直接流,无其他环节)
4.2 分支流向(一个数据源→多个目的地)
- 逻辑:数据源 → 处理 → 多个目的地(数据复制后分别流向不同地方)
- 例子:
ls /tmp | tee tmp_list.txt | grep "log"
(数据源:/tmp 目录 → 处理:ls 列出 → 目的地 1:tmp_list.txt 文件;目的地 2:grep 命令(进一步筛选)→ 最终目的地:屏幕)
这里 tee 命令是 “分支器”,相当于 “水管分叉,一路水流到文件,一路流到下一个命令”
*类比:水龙头→分叉水管→一个杯子 + 一个水桶
4.3 串联流向(多处理环节→链式传递)
- 逻辑:数据源 → 处理1 → 处理2 → 处理3 → 目的地(数据经过多步加工,每一步的输出是下一步的输入)
- 例子:
cat big_log.txt | grep "ERROR" | sed 's/ERROR/错误/' | sort > error_sorted.txt
流向:大日志文件 → 筛选 ERROR 行 → 替换为 “错误” → 排序 → 写入文件 - 类比:水龙头→净水器→过滤器→加热器→杯子(水经过多步处理,最终到杯子)
5. 数据流向实例讲解
如图:

上图是一个虚拟机访问百度页面的整个过程,接下来剖析各个过程:
① 用户开启浏览器进程
② 输入需要访问的域名
③ 通过DNS将域名解析为IP地址(访问完成之后会建立缓存)
④ 建立连接:浏览器与Web服务器建立TCP连接(三次握手)
⑤ 发送请求:浏览器发起HTTP请求(80端口)/如果是HTTPS请求,则为(443端口)
⑥ 服务器处理:
处理虚拟机静态资源请求,建立新进程,匹配专用端口(80端口),为用户提供Web网页动态资源,查询数据库,匹配符合用户要求的服务
⑦ 返回响应:Web服务器将结果打包成HTTP响应报文返回浏览器
⑧ 渲染页面:浏览器解析HTML,加载CSS/JS、渲染最终页面
6. 静态资源及动态资源
静态资源和动态资源是 Web 开发 / 服务器部署中最基础的概念,核心区别是 “资源内容是否在请求时动态生成”。
6.1 核心定义
| 类型 | 核心特点(本质) | 通俗类比 | 常见例子 |
|---|---|---|---|
| 静态资源 | 内容固定不变,服务器收到请求后 “直接返回”(无需计算 / 生成) | 超市货架上的瓶装水(生产好后,谁买都一样) | HTML、CSS、JS 文件、图片(jpg/png)、视频、音频、字体文件、静态网页(.html) |
| 动态资源 | 内容按需生成,服务器收到请求后 “实时计算 / 查询” 再返回 | 奶茶店的现做奶茶(根据顾客需求:少糖、加珍珠,现场制作) | 动态网页(PHP/JSP/Java/Python 脚本)、API 接口(返回实时数据)、数据库查询结果(比如查询商品库存、用户信息) |
简单说:静态资源是 “现成的”,动态资源是 “现做的”。
6.2 关键区别
| 对比维度 | 静态资源 | 动态资源 |
|---|---|---|
| 内容生成时机 | 开发 / 部署时就已固定(比如写好的 .html 文件) | 用户请求时才生成(比如请求 /user/123 时,从数据库查用户 123 的信息) |
| 服务器处理方式 | 直接读取文件,返回给客户端(无额外计算) | 调用脚本 / 程序→查询数据库 / 计算→生成内容→返回 |
| 内容重复性 | 所有用户请求同一资源,返回内容完全一致 | 不同用户 / 不同时间请求,返回内容可能不同(比如登录后显示用户名) |
| 性能消耗 | 低(仅文件 IO 操作,服务器压力小) | 高(需 CPU 计算、数据库查询,服务器压力大) |
| 缓存友好度 | 非常友好(可缓存到浏览器、CDN,下次直接用) | 缓存复杂(需考虑数据实时性,比如库存不能缓存太久) |
6.3 部署与优化小技巧
6.3.1 静态资源优化(核心:缓存 + CDN)
缓存:让浏览器缓存静态资源(比如图片、CSS),下次访问不用重新下载,用 Nginx 配置即可(Shell 脚本修改 Nginx 配置):
# 编辑 Nginx 配置,给静态资源设置缓存时间(7天)
sed -i '/http {/a expires 7d;' /etc/nginx/nginx.conf
systemctl restart nginx
CDN:把静态资源(图片、视频)放到 CDN 上(比如阿里云 CDN),用户从就近的 CDN 节点下载,速度更快。
6.3.2 动态资源优化(核心:减少计算 + 数据库优化)
减少计算:把频繁访问的动态结果缓存起来(比如用 Redis 缓存商品列表),避免每次请求都查数据库;
数据库优化:给数据库加索引(比如用户 ID 索引),加快查询速度(减少动态资源生成时间);
用 Shell 脚本监控动态资源性能:比如监控 PHP 脚本的执行时间,发现缓慢及时排查:
# 记录脚本执行时间(模拟监控动态资源)
start_time=$(date +%s)
./dynamic_script.sh # 动态资源脚本
end_time=$(date +%s)
echo "动态资源执行时间:$((end_time - start_time)) 秒"
小结
数据流向记住三句话:
数据流向的本质:“数据从哪来、经过什么处理、到哪去”;
命令行中控制流向的工具:重定向(> >> <2>)改 “目的地”,管道(|)连 “处理环节”;
所有复杂流向,都是 “单向流向” 的叠加(多环节、多目的地),核心逻辑不变。
静态资源与动态资源速记:
静态资源:现成的、固定的,服务器直接返回,性能高、缓存友好(比如 HTML、图片);
动态资源:现做的、按需生成的,服务器需计算 / 查数据库,性能消耗高(比如订单页面、API);
实操关联:用 Shell 写的脚本如果 “实时生成数据”(比如查日志、查系统信息),就是动态资源;部署的 HTML、图片,就是静态资源;
核心优化思路:静态资源 “多缓存、用 CDN”,动态资源 “少计算、多缓存”。
二、Nginx
1. Nginx概念
Nginx(发音 “engine x”)是一款高性能的 HTTP 服务器、反向代理服务器、负载均衡器—— 核心作用是 “接收用户请求、处理请求、返回资源”,就像一个 “智能网关”,一边连接用户(客户端),一边连接后端服务 / 资源,高效调度数据流向。
2. 安装服务方式
安装一个服务,通常有以下几种方式:
1、yum install -y server name || rpm -ivh/-evh server name(rpm包安装)
2、源码包安装 || 手工编译安装(类似于Windows安装逻辑)
3、容器技术安装 (docker run image:name)
4、jave -jar xxx.jar (jar包安装)
5、工具安装 (Linux宝塔运维工具)
3. Nginx安装教程(属于源码包安装形式)
① 关闭防火墙、核心防护(需先配置DNS解析)
[root@localhost selinux]# systemctl stop firewalld
[root@localhost selinux]# systemctl disable firewalld
[root@localhost selinux]# setenforce 0 # 临时关闭核心防护,重启之后会返回初始值
[root@localhost selinux]# sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' config
# 永久关闭核心防护,类似于永久挂载
② 安装依赖环境
#nginx的配置及运行需要pcre、zlib等软件包的支持,因此需要安装这些软件的开发包,以便提供相应的库和头文件。
yum install -y pcc pcc++ make zlib zlib-devel pcre pcre-devel openssl openssl-devel
⭐易错点:yum安装rpm包时须先确认是否正确配置DNS,已经是否已清理完成缓存,否则容易读取原有残留导致报错。
这一步是为了解决Nginx所依赖的安装包。
③ 创建运动用户、组
useradd -M -s /sbin/nologin nginx
Nginx服务程序默认以nobody身份运行,建议为其创建专门的用户账户,以便更准确地控制其访问权限。
④ 上传并解压缩源码包tar.gz
[root@localhost opt]# ls
nginx-1.20.2.tar.gz rh
[root@localhost opt]# tar zxvf nginx-1.20.2.tar.gz -C /opt/ # 解压
# …… # 中间很多信息,不在这边列出
[root@localhost opt]# ls
nginx-1.20.2 nginx-1.20.2.tar.gz rh
⑤ 进入解压后的目录,执行编译与编译安装(configure)的配置动作
[root@localhost opt]# cd nginx-1.20.2/
[root@localhost nginx-1.20.2]# ls
auto CHANGES CHANGES.ru conf configure contrib html LICENSE man README src
[root@localhost nginx-1.20.2]# ./configure
> --prefix=/usr/local/nginx # 指定nginx的安装路径
> --user=nginx # 指定用户名
> --group=nginx # 指定组名
> --with-http_stub_status_module
> --with-http_ssl_module # 启用http stub status module模块以支持操作
[root@localhost opt]# make && make install
# make 负责将源码编译为可执行程序
# make install 负责将编译后的程序、配置文件等复制到指定目录(即 ./configure 时通过 --prefix 指定的路径,默认 /usr/local/nginx)
[root@localhost ~]# ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin
# 让系统识别nginx的操作命令
⑥ 检查是否安装成功(到/usr/local/nginx的工作目录中查看)
[root@localhost ~]# nginx -t #检查配置文件是否配置正确
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
⭐易错点:未创建nginx用户名,导致开启nginx不成功。
⑦ 添加给systemd工具识别
vim /lib/systemd/system/nginx.service
[Unit] # 服务说明
Description=nginx
After=network.target
[Service] # 服务运行参数的设置
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install] # 服务安装的相关设置,可设置为多用户
WantedBy=multi-user.target
补充说明:
Description:描述服务
After:依赖,当依赖的服务启动之后再启动自定义的服务
[Service]服务运行参数的设置
Type=forking是后台运行的形式,使用此启动类型应同时指定
PIDFile以便systemd能够跟踪服务的主进程。
ExecStart为服务的具体运行命令
ExecReload为重启命令
ExecStop为停止命令
PrivateTmp=True表示给服务分配独立的临时空间
注意:启动、重启、停止命令全部要求使用绝对路径
[Install]服务安装的相关设置,可设置为多用户
chmod 754 /lib/systemd/system/nginx.service
# 修改nginx.service服务文件的权限
systemctl start nginx.service # 启动Nginx服务
systemctl enable nginx.service # 设置Nginx服务开机自启动
⑧ 验证是否成功
使用浏览器访问页面,验证是否成功。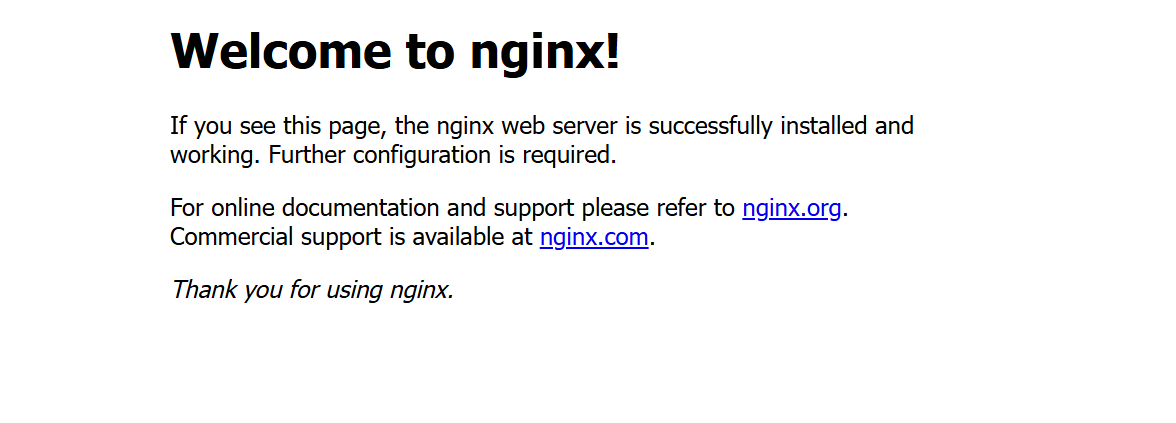
如图,连接成功,表示nginx已安装完成。
总结
数据流向是 “信息传输的路径逻辑”,从命令行的重定向、管道,到 Web 场景的请求响应,核心是 “数据源 - 处理 - 目的地” 的串联;Nginx 则是 “数据流向的高效载体”,通过静态资源直返、动态请求转发、多服务负载均衡,成为连接用户与后端的核心枢纽。从 Shell 脚本的数据流控,到 Nginx 的服务化部署,二者共同构建了 Linux 系统中 “数据高效流转、服务稳定交付” 的底层逻辑。掌握数据流向的控制技巧,熟练 Nginx 的安装与配置,就能在 Linux 运维与 Web 开发中实现资源的精准调度与服务的高效交付。