Puma启动流程详解:从命令行到服务器就绪
Puma启动流程详解:从命令行到服务器就绪
【免费下载链接】puma A Ruby/Rack web server built for parallelism  项目地址: https://gitcode.com/gh_mirrors/pu/puma
项目地址: https://gitcode.com/gh_mirrors/pu/puma
你是否曾好奇,当在终端输入puma命令后,这个Ruby应用服务器是如何从一行命令转变为能够处理并发请求的强大服务的?本文将带你深入Puma的启动流程,从命令解析到端口监听,从配置加载到线程池初始化,一步步揭开Puma服务器就绪背后的奥秘。读完本文,你将能够清晰理解Puma的启动机制,掌握关键配置项的作用,并学会如何优化你的Puma启动流程。
一、命令行解析:用户指令的第一步转化
Puma的启动之旅始于命令行输入。当你执行puma命令时,Puma会首先创建一个CLI对象来解析命令行参数。这个过程主要由lib/puma/cli.rb文件中的CLI类负责。
CLI类的核心任务是解析用户输入的命令行选项,并将其转化为Puma的配置参数。它使用Ruby标准库中的OptionParser来处理各种命令行选项,如-b(绑定地址)、-t(线程数)、-w(工作进程数)等。例如,当你输入puma -p 3000 -t 2:16时,CLI类会解析出端口号3000和线程池大小2-16。
除了直接解析命令行参数,CLI类还会加载配置文件。它会按照特定的优先级顺序查找配置文件:首先是命令行中通过-C或--config选项指定的文件,然后是当前目录下的config/puma.rb,接着是config/puma/,最后是用户主目录下的.pumarc。这种多级配置机制允许你灵活地为不同环境和项目设置特定的参数。
解析完成后,CLI类会创建一个Configuration对象,将解析得到的所有配置参数整合到这个对象中。这个Configuration对象随后会被传递给Launcher类,成为后续启动过程的基础。
二、配置加载:构建Puma的运行蓝图
配置加载是Puma启动过程中的关键环节,它决定了服务器的运行方式。这个过程主要由lib/puma/configuration.rb文件中的Configuration类负责。
Configuration类采用了一种优雅的方式来处理配置:它维护了一个配置块的数组,每个配置块代表一组配置参数。这些配置块可以来自命令行选项、配置文件,甚至是应用程序代码中的动态配置。当需要确定最终的配置值时,Configuration类会按顺序执行这些配置块,后执行的配置块可以覆盖先执行的配置块中的参数,从而实现了配置的优先级机制。
配置加载完成后,Configuration对象会包含Puma运行所需的所有参数,如绑定地址、端口号、线程池大小、工作进程数、超时设置等。这些参数会被用来初始化Launcher对象,启动真正的服务器进程。
三、启动器初始化:Puma的中枢神经系统
Launcher类(定义在lib/puma/launcher.rb)是Puma启动流程的核心协调者,堪称Puma的"中枢神经系统"。它接收Configuration对象作为输入,并负责将配置转化为实际的服务器运行状态。
Launcher的初始化过程主要包括以下几个关键步骤:
-
日志和事件系统设置:
Launcher会初始化日志写入器(LogWriter)和事件系统(Events),用于处理服务器运行过程中的日志输出和事件通知。 -
绑定器(Binder)创建:
Launcher会创建一个Binder对象(定义在lib/puma/binder.rb),负责处理网络端口的绑定和监听。 -
环境变量设置:根据配置,
Launcher会设置必要的环境变量,如RACK_ENV。 -
插件加载:如果配置了插件,
Launcher会在此阶段加载相应的插件。例如,如果检测到系统中存在NOTIFY_SOCKET环境变量(通常在systemd服务中),Launcher会自动加载systemd插件。 -
运行模式确定:根据配置中的工作进程数(
workers),Launcher会决定Puma是以单进程模式(Single)还是集群模式(Cluster)运行。如果workers大于0,则使用集群模式,否则使用单进程模式。
# 代码片段来自lib/puma/launcher.rb,展示了运行模式的选择
if clustered?
@runner = Cluster.new(self)
else
@runner = Single.new(self)
end
四、端口绑定:Puma与外部世界的连接点
在确定了运行模式后,Launcher会通过Binder对象来完成网络端口的绑定工作。Binder类(lib/puma/binder.rb)是Puma处理网络连接的关键组件,它负责创建和管理服务器的监听套接字。
Binder支持多种类型的绑定,包括TCP端口、UNIX域套接字和SSL加密连接。对于TCP绑定,Binder会创建一个TCPServer对象,并设置适当的套接字选项,如SO_REUSEADDR(允许端口重用)和TCP_NODELAY(禁用Nagle算法,减少延迟)。
# 代码片段来自lib/puma/binder.rb,展示了TCP监听的创建
def add_tcp_listener(host, port, optimize_for_latency=true, backlog=1024)
if host == "localhost"
loopback_addresses.each do |addr|
add_tcp_listener addr, port, optimize_for_latency, backlog
end
return
end
host = host[1..-2] if host&.start_with? '['
tcp_server = TCPServer.new(host, port)
if optimize_for_latency
tcp_server.setsockopt(Socket::IPPROTO_TCP, Socket::TCP_NODELAY, 1)
end
tcp_server.setsockopt(Socket::SOL_SOCKET,Socket::SO_REUSEADDR, true)
tcp_server.listen backlog
@ios << tcp_server
tcp_server
end
Binder还支持系统d的套接字激活机制,这在某些Linux发行版中非常有用。通过套接字激活,Puma可以继承由系统d预先创建的套接字,实现更高效的服务管理。
绑定完成后,Binder会记录所有成功绑定的地址和端口,并在日志中输出,让用户知道服务器正在哪些地址上监听连接。
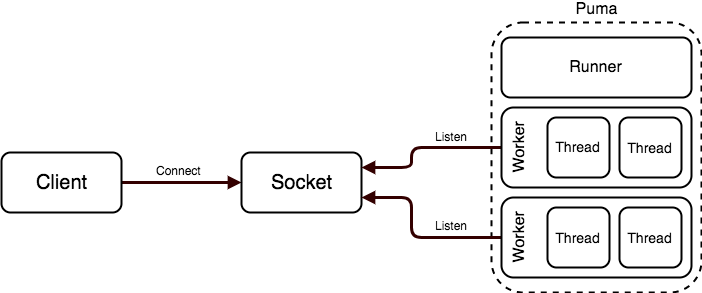
五、服务器初始化:构建请求处理核心
完成端口绑定后,Puma进入服务器初始化阶段。根据之前确定的运行模式(单进程或集群),Launcher会创建相应的Runner对象(Single或Cluster),并调用其run方法启动服务器。
在单进程模式下,Single类会直接创建一个Server对象(定义在lib/puma/server.rb)。Server是Puma处理HTTP请求的核心组件,它包含一个线程池(ThreadPool)和一个反应器(Reactor)。
线程池负责处理实际的请求,其大小由配置中的min_threads和max_threads参数决定。线程池会根据请求负载动态调整活跃线程的数量,以平衡资源利用率和响应速度。
反应器则负责管理网络连接,它使用IO多路复用技术(如select或epoll)来高效地处理多个并发连接。反应器会监听所有已绑定的套接字,当有新连接到来时,会接受连接并将其分配给线程池中的工作线程处理。
# 代码片段来自lib/puma/server.rb,展示了服务器的启动过程
def run(background=true, thread_name: 'srv')
BasicSocket.do_not_reverse_lookup = true
@events.fire :state, :booting
@status = :run
@thread_pool = ThreadPool.new(thread_name, options, server: self) { |client| process_client client }
if @queue_requests
@reactor = Reactor.new(@io_selector_backend) { |c|
self.reactor_wakeup(c)
}
@reactor.run
end
# ... 省略部分代码 ...
@events.fire :state, :running
if background
@thread = Thread.new do
Puma.set_thread_name thread_name
handle_servers
end
return @thread
else
handle_servers
end
end
在集群模式下,Cluster类会创建多个工作进程,每个工作进程都会初始化一个Server实例。主进程会监控所有工作进程的状态,并在需要时重启崩溃的进程,从而提高系统的可靠性。
六、就绪通知:服务器准备就绪的信号
当服务器完成所有初始化工作,准备好处理请求时,会发送就绪通知。这个通知机制因运行环境而异。
在普通终端环境中,Puma会在日志中输出"* Listening on ..."消息,告知用户服务器已经成功启动并开始监听指定的地址和端口。
如果Puma运行在systemd服务中,并且加载了systemd插件,那么Puma会通过sd_notify机制向systemd发送就绪信号。这使得systemd能够准确地知道服务何时真正准备好接收请求,从而实现更精确的服务管理和依赖控制。
对于Kubernetes环境,Puma可以配置健康检查端点,让Kubernetes能够通过HTTP请求来探测服务的就绪状态。
无论使用哪种通知方式,就绪通知都标志着Puma启动流程的完成,服务器从此进入正常的请求处理循环。
七、启动流程优化:让Puma更快、更稳地就绪
了解了Puma的启动流程后,我们可以采取一些优化措施来让Puma更快、更稳定地完成启动并进入就绪状态。
-
合理配置线程池和工作进程:根据服务器的CPU核心数和内存大小,调整
-t(线程数)和-w(工作进程数)参数。一般来说,工作进程数不应超过CPU核心数,而每个工作进程的线程数则应根据应用的线程安全性和IO密集程度来调整。 -
预加载应用代码:在集群模式下,可以使用
--preload选项来预加载应用代码。这样,应用代码会在主进程中加载一次,然后通过fork机制复制到各个工作进程中,减少了重复加载的开销,加快了启动速度。 -
优化绑定地址:尽量使用具体的IP地址而非
localhost进行绑定。因为绑定到localhost会导致Puma同时监听IPv4和IPv6地址,可能会增加不必要的启动时间和资源消耗。 -
精简配置文件:只保留必要的配置项,避免在配置文件中执行耗时的操作或复杂的计算。
-
使用合适的日志级别:在生产环境中,可以适当降低日志级别,减少日志输出对启动性能的影响。
-
定期更新Puma版本:Puma团队持续改进启动性能和稳定性,使用最新版本通常能获得更好的启动体验。
通过这些优化措施,你可以显著改善Puma的启动性能,特别是对于大型Rails应用,这些优化可能会将启动时间从数十秒减少到几秒。
总结:Puma启动流程的关键点回顾
Puma的启动流程是一个从命令行解析到服务器就绪的复杂过程,涉及多个组件的协同工作。通过本文的讲解,我们可以看到:
- 命令行解析阶段,
CLI类将用户输入转化为配置参数,并加载适当的配置文件。 - 配置加载阶段,
Configuration类整合所有配置来源,形成最终的运行参数。 - 启动器初始化阶段,
Launcher类根据配置决定运行模式,并准备必要的运行环境。 - 端口绑定阶段,
Binder类创建网络监听套接字,建立服务器与外部世界的连接。 - 服务器初始化阶段,
Server类创建线程池和反应器,构建请求处理核心。 - 就绪通知阶段,服务器通过日志或系统信号告知外部已准备就绪。
理解这个流程不仅有助于你更好地配置和使用Puma,也为你排查启动问题提供了清晰的思路。当Puma启动出现问题时,你可以按照这个流程逐步检查:首先确认命令行参数和配置文件是否正确,然后检查端口是否被占用,接着查看日志文件中的错误信息,最后根据具体情况调整配置或修复代码。
Puma作为一款高性能的Ruby应用服务器,其启动流程的设计体现了对性能、灵活性和可靠性的追求。通过深入理解和优化这个流程,你可以让你的Ruby应用以最佳状态运行,为用户提供更快、更稳定的服务体验。
希望本文能帮助你更好地理解Puma的启动过程。如果你有任何问题或建议,欢迎在评论区留言讨论。感谢阅读!
【免费下载链接】puma A Ruby/Rack web server built for parallelism 项目地址: https://gitcode.com/gh_mirrors/pu/puma