


声源定位算法2----MUSIC(1)
在前几篇文章中,我们介绍了 CBF(Conventional Beamforming) 的基本原理,并实现了宽频信号条件下的频域 CBF 算法。
CBF 思想直观、实现简单,但其空间分辨率和抗干扰能力受到阵列孔径和旁瓣的限制。
为了进一步提升声源定位的分辨率,学术界和工程中广泛采用了一类基于子空间分解的高分辨率算法,其中最经典的就是 MUSIC(Multiple Signal Classification)算法。
MUSIC 的核心思想并不是“对齐并叠加”,而是:
利用信号子空间与噪声子空间的正交性来进行声源定位。
1. MUSIC 的基本思想
CBF 的出发点是:
-
假设一个方向
-
把信号对齐
-
看能量是否最大
而 MUSIC 的出发点完全不同:
-
阵列接收信号可以分解为
信号子空间 + 噪声子空间 -
真正的声源方向,其导向向量:
-
位于信号子空间
-
与噪声子空间正交
-
因此,MUSIC 并不直接形成波束,而是通过“正交性检验”来判断方向是否为真实声源。
2. 阵列信号模型(频域)
在 MUSIC 中,通常采用窄带频域模型(宽带情形后文讨论)。
假设在频率 f 处,阵列接收信号为:
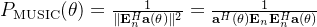
其中:
-
x(f):阵列观测向量
-
A(f)=[a(f,θ1),…,a(f,θK)]:导向矩阵
-
s(f):声源信号
-
n(f):噪声
3. 导向向量(Steering Vector)
对于假设方向 θ,其导向向量定义为:
这里的时延与 CBF 中的定义完全一致。
4. 协方差矩阵与特征分解
4.1 协方差矩阵
MUSIC 的核心在于协方差矩阵的结构分析:
4.2 特征值分解
对协方差矩阵进行特征值分解:
其中:
-
Λ:特征值对角矩阵
-
E=[e1,e2,…,eM]:特征向量
5. 信号子空间与噪声子空间
假设存在 K 个不相关声源:
-
前 K 个大特征值 → 信号子空间
-
剩余 M − K 个小特征值 → 噪声子空间
噪声子空间矩阵定义为:
6. MUSIC 的正交性原理
对于真实声源方向 θk,其导向向量满足:
这意味着:
真实声源方向的导向向量,与噪声子空间正交。(下文附录详细解释)
7. MUSIC 空间谱函数
基于上述正交性,定义 MUSIC 空间谱为:
当 θ接近真实声源方向时,分母趋近于 0,空间谱出现尖锐峰值。
8. MUSIC 的定位结果
最终定位通过空间谱峰值搜索获得:
9. 宽带 MUSIC 的工程实现思路
由于 MUSIC 本质是窄带算法,在宽带声源条件下,常见工程处理方式包括:
9.1 频带分解 + 频点平均
9.2 频带聚焦(Focusing Method)
通过构造聚焦矩阵,将不同频率的导向向量映射到参考频率,再统一做子空间分解(工程复杂度较高,本文不展开)。
10. MUSIC 与 CBF 的对比总结
| 方法 | 核心思想 | 分辨率 | 抗干扰 | 计算复杂度 |
|---|---|---|---|---|
| CBF | 延时对齐 + 能量叠加 | 低 | 低 | 低 |
| MUSIC | 子空间正交性 | 高 | 中 | 高 |
一句话总结:
CBF 看的是“能量最大”,MUSIC 看的是“是否正交”。
11. 工程实现上的注意事项
-
MUSIC 对阵列误差、互耦、相位失配较敏感
-
需要较好的协方差矩阵估计
-
需要提前估计声源数 K(后面有时间可以介绍下我之前做的源数估计方法)
-
在低 SNR 或强混响环境下性能下降明显
因此在实际系统中,MUSIC 往往用于:
-
高分辨率离线分析
-
上位机或 ARM 平台实现
-
与 CBF / MVDR 形成互补
12. 小结
MUSIC 通过对阵列协方差矩阵的特征分解,将接收信号划分为信号子空间与噪声子空间,并利用导向向量与噪声子空间的正交性构造空间谱,从而实现高分辨率声源定位。
在工程实践中,MUSIC 往往作为 CBF 之后的“精细定位算法”,而非直接替代 CBF。
附录:
在刚开始学习的时候,对于这里的正交性总会不理解。我把我自己的一些想法写下来,便于以后自己翻看。也希望对大家有帮助。
#********************************#
信号只沿着少数几个“固定方向”变化;噪声是“各个方向都均匀”的。
所以协方差矩阵里会出现:一块“信号主导的方向”,一块“只剩噪声的方向”。
MUSIC 就是利用这两块方向互相垂直。
正交性从哪来?
这是一个纯线性代数事实:
Hermitian 矩阵(协方差矩阵)
不同特征值对应的特征向量必然正交
因此:
-
前 K 个特征向量
👉 信号子空间 -
后 M − K 个特征向量
👉 噪声子空间
并且:
-
不是:信号和噪声本身正交
-
而是:“协方差矩阵分解出来的两个特征子空间正交”
Step 1:导向矢量 a(θ)
假设有一个方向 θ的声源。它到每个麦克风的相位/时延不同。把这些“相位差”写成一个向量,就是导向矢量:
a(θ) 就是“如果声源在 θ,每个麦克风应该呈现怎样的相位关系”。这个应该很熟悉了。
Step 2:先只考虑“一个声源 + 无噪声”
如果只有一个声源,阵列观测(频域、窄带)可以写成:
Step 3:加噪声
加入噪声:
“不相关”指的是统计意义的:
噪声和信号不相关,平均意义下它们没有耦合。但这还不能推出“正交”。它只是让协方差展开时,交叉项消失。
Step 4:协方差矩阵
协方差定义:
把 代入并利用“不相关”,得到:
协方差 = 信号造成的一部分 + 噪声造成的一部分。
Step 5:“白噪声”
MUSIC 经典推导还需要噪声是白噪声(空间各向同性):
于是:
其中。
-
这一项,只会在“a 的方向”上把能量抬高(它是 rank-1 的)
-
在任何方向都一样,不偏向任何子空间
Step 6:解释“为什么导向矢量与噪声子空间正交”
先不说“噪声子空间”这个词。
我们先说一个更容易懂的东西:
找一个方向 v,它完全垂直于 导向矢量a。
也就是:
现在看协方差矩阵作用在 v上:
展开第一项:
但因为,所以这一项直接变成 0:
于是:
任何“垂直于导向矢量 a 的方向 v,在协方差矩阵里只看到噪声(特征值就是
也就是说这些方向构成的空间,就是“噪声主导的空间”。
这些所有的 v(它们都满足)张成的空间,就叫噪声子空间。
把噪声子空间的基向量拼成矩阵 En,就等价于:
这就是“导向矢量与噪声子空间正交”的来源。
Step 7:定位步骤
在 MUSIC 真正开始定位之前,你已经做完了这些:
-
用数据算出了协方差矩阵
-
对它做了特征分解
-
拿到了 噪声子空间基矩阵En
扫描一个方向 θ,算这个导向矢量。把导向矢量“扔进噪声子空间看看”。
两种方向,结果完全不同(这是定位的根本)
情况 1:θ 是真实声源方向
根据前面所有推导:
情况 2:θ 是错误方向
这时正交性不成立:
把“是不是 0”变成一个“可排序的数”
工程上,我们不直接判断“等不等于 0”,而是算一个大小:
这个量的含义只有一句话:方向 θ 在“噪声子空间里”的能量有多大
-
真声源方向 → 这个值 ≈ 0
-
假方向 → 这个值 > 0
为了“让真方向更显眼”,定义 MUSIC 空间谱:
总结:
1、MUSIC 中噪声子空间与导向矢量的正交性,并非由特征分解“制造”,而是源于信号协方差项仅在导向矢量张成的低维空间内起作用。在白噪声假设下,所有与该空间正交的方向在协方差矩阵中仅体现为统一的噪声特征值,这些方向构成噪声子空间,因此真实声源方向的导向矢量必然与噪声子空间正交。
2、MUSIC 算法通过构造噪声子空间,并扫描所有候选方向,计算各方向导向矢量在噪声子空间中的投影能量。当导向矢量与噪声子空间正交时,该方向与真实声源方向一致,空间谱出现峰值,从而实现声源定位。
下篇文章我将继续讲解MUSIC算法实现的一些问题以及可能困惑的点,同时仿真实现宽频信号的MUSIC算法。






