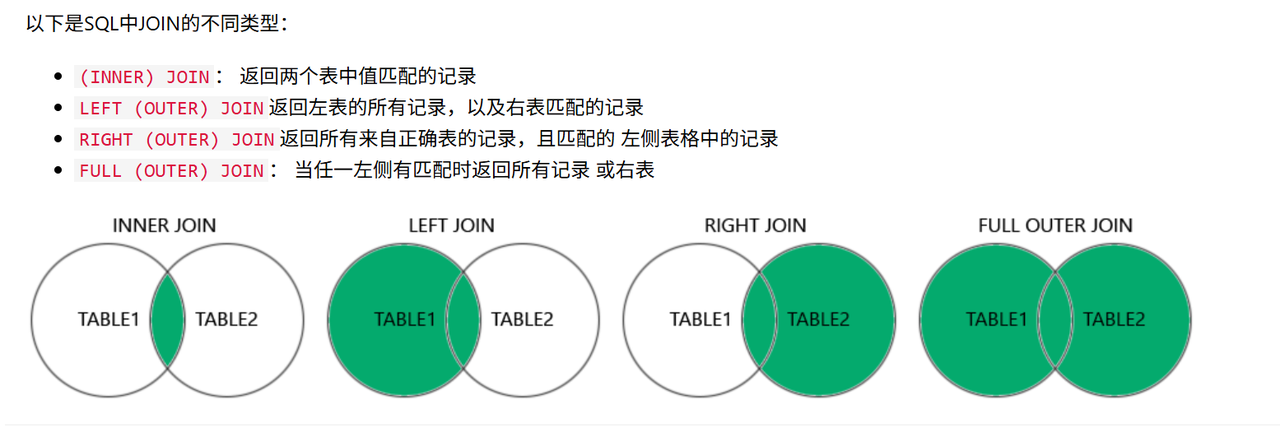
SSH Jump Host跳板机访问内网PyTorch服务器
SSH Jump Host跳板机访问内网PyTorch服务器
在AI研发团队中,一个常见的场景是:你手握最新的深度学习模型设计思路,准备在实验室的GPU集群上跑通实验。然而,这些高性能服务器被牢牢锁在企业内网之中——出于安全策略,它们没有公网IP,防火墙规则也禁止外部直接连接SSH端口。此时,如何既保障网络安全,又能高效地远程调试代码、启动训练任务?
答案正是本文要深入探讨的技术组合:通过SSH跳板机(Jump Host)安全接入部署了PyTorch-CUDA-v2.8镜像的内网GPU服务器。这不仅是一套解决方案,更是一种现代AI工程实践中平衡安全性与开发效率的标准范式。
跳板机不是“绕路”,而是“受控通道”
很多初学者会把SSH跳板机理解为“多走一步”的麻烦流程,但其实它的本质远不止于此。它是一个受控的安全入口点,相当于在网络边界设置了一个带监控的安检门。所有对外服务仍保留在隔离区内,而用户只能通过这个唯一的合法路径进入。
以典型的三层架构为例:
- 外层:你的笔记本电脑位于任意网络环境;
- 中间层:一台配置了公网IP的轻量级Linux服务器作为跳板机(Bastion Host),仅开放22端口;
- 内层:真正的GPU计算节点隐藏在私有子网中,其SSH端口只允许来自跳板机IP的连接请求。
这种结构下,即便攻击者扫描到GPU服务器的存在,也无法直接发起暴力破解或漏洞利用,因为目标根本不响应来自非信任源的连接。
实现方式:从命令行到自动化配置
最简单的单次跳转可以通过 -J 参数完成:
ssh -J user@jump-host-ip ai-developer@192.168.1.100
这条命令的意思是:“先用 user 账号登录跳板机,然后由该机器代为连接内网地址 192.168.1.100”。整个过程对用户透明,无需手动分步操作。
但对于需要频繁访问多个内网节点的研发人员来说,每次都输入冗长的参数显然不现实。更好的做法是利用 ~/.ssh/config 文件进行声明式管理:
Host jump
HostName 203.0.113.45
User devops
IdentityFile ~/.ssh/id_rsa_bastion
Port 22
Host gpu-worker-1
HostName 192.168.1.100
User ai-developer
IdentityFile ~/.ssh/id_rsa_gpu
ProxyCommand ssh -W %h:%p jump
一旦配置完成,只需执行 ssh gpu-worker-1,SSH客户端就会自动建立双跳隧道。这里的 ProxyCommand 是关键机制——它告诉本地SSH进程:“不要直连目标,而是先连上jump主机,并通过 -W 启用标准输入输出转发”。
小贴士:如果你使用的是较老版本的OpenSSH(<7.3),可能不支持
-J选项。此时可结合netcat模拟:
bash ProxyCommand ssh jump nc %h %p
安全加固建议
虽然SSH本身是加密协议,但跳板机作为“钥匙保管员”,必须格外小心:
- 禁用密码登录:强制使用密钥认证,防止弱口令爆破;
- 限制源IP访问:在跳板机的防火墙层面只允许可信办公网络或VPN出口IP连接;
- 启用连接审计:配合
auditd或集中日志系统记录每一次登录行为; - 最小权限原则:跳板机上不应安装额外软件包,避免成为攻击跳板。
PyTorch-CUDA容器镜像:让环境不再“因人而异”
当终于连上了GPU服务器,另一个常见问题浮出水面:为什么同事能跑通的代码,在我这里却报错 CUDA out of memory 或 torch not compiled with CUDA enabled?
这类问题往往源于“环境地狱”——不同操作系统、驱动版本、CUDA工具链之间的微妙差异导致行为不一致。解决之道就是容器化:将完整的运行时环境打包成一个不可变的镜像。
我们提到的 PyTorch-CUDA-v2.8 镜像 正是为了应对这一挑战而生。它通常基于官方镜像构建,例如:
FROM pytorch/pytorch:2.8.1-cuda12.1-cudnn8-runtime
该基础镜像已集成以下组件:
| 组件 | 版本说明 |
|---|---|
| OS | Ubuntu 20.04 LTS |
| Python | 3.10+ |
| PyTorch | 2.8.1 |
| CUDA Toolkit | 12.1 |
| cuDNN | v8 |
| TorchVision / TorchText | 对应兼容版本 |
更重要的是,它已经预装了NVIDIA Container Runtime支持,只要宿主机安装了匹配版本的NVIDIA驱动(如Driver >= 535),就可以通过 --gpus all 参数无缝调用GPU资源。
快速验证环境是否就绪
登录目标服务器后,第一步不是急着拉代码,而是确认环境可用性。下面这段Python脚本可以作为一个“健康检查”工具:
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU count: {torch.cuda.device_count()}")
print(f"Current GPU: {torch.cuda.get_device_name(torch.cuda.current_device())}")
else:
print("⚠️ Warning: CUDA is not enabled!")
预期输出应类似:
PyTorch version: 2.8.1+cu121
CUDA available: True
GPU count: 4
Current GPU: NVIDIA A100-PCIE-40GB
如果返回 False,则需排查以下几个方面:
- 容器是否以
--gpus all启动? - 宿主机是否正确安装NVIDIA驱动并加载
nvidia-smi可见? - Docker是否配置了
nvidia-container-toolkit并重启过守护进程?
多卡训练的最佳实践
对于大规模模型训练,充分利用多张GPU至关重要。PyTorch提供了两种主流模式:
DataParallel:单进程多线程,适合中小规模模型;DistributedDataParallel (DDP):多进程并行,通信效率更高,推荐用于生产环境。
使用 DDP 时建议配合 NCCL 后端,尤其在A100/H100等高端显卡上性能优势明显:
import torch.distributed as dist
dist.init_process_group(backend='nccl')
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
此外,可通过环境变量控制可见设备,避免资源争抢:
CUDA_VISIBLE_DEVICES=0,1 python train_ddp.py
开发体验优化:不只是命令行
尽管终端操作灵活强大,但在实际建模过程中,交互式编程和可视化分析仍是刚需。因此,仅仅能SSH登录还不够,还需打通 Jupyter Notebook 的远程访问链路。
如何安全暴露Jupyter服务?
Jupyter默认监听 localhost:8888,这意味着即使你在容器中启动了服务,外部也无法访问。传统做法是绑定 0.0.0.0 并设置token,但这会带来暴露风险。
更优解是结合 SSH 端口转发实现“反向隧道”:
ssh -N -L 8888:localhost:8888 ai-developer@gpu-worker-1
解释一下这个命令:
-N表示不执行远程命令,仅建立隧道;-L 8888:localhost:8888指定将本地的8888端口映射到远程主机的8888端口;- 当你在浏览器打开
http://localhost:8888时,流量会经由SSH加密通道转发至内网服务器上的Jupyter实例。
这种方式完全不需要开放任何额外端口,且全程通信受SSH保护,即便是公共WiFi环境下也相对安全。
提升协作效率的小技巧
在一个团队共享GPU资源的环境中,还可以进一步优化工作流:
- 统一镜像版本:通过内部Registry托管定制镜像,确保所有人使用相同的PyTorch+CUDA组合;
- 持久化Notebook目录:挂载NFS存储卷保存
.ipynb文件,避免容器重启丢失进度; - 资源调度辅助:结合
tmux或screen运行长时间任务,断开连接不影响后台执行; - 文件同步加速:大体积数据集传输优先使用
rsync替代Jupyter的Web界面拖拽上传:
bash
rsync -avz --progress dataset/ jump:~/workspace/dataset/
架构演进的可能性
当前这套方案虽已满足大多数中小型团队的需求,但仍有扩展空间。随着团队规模扩大或算力需求增长,可以逐步引入更高级的基础设施:
向Kubernetes迁移
当GPU节点数量超过5台时,手动管理容器生命周期变得低效。此时可考虑迁移到 Kubernetes + KubeFlow 架构:
- 使用
Device Plugin管理GPU资源分配; - 借助
JupyterHub实现多用户隔离的Notebook服务; - 通过 Istio 或 Ambassador 实现API网关级别的访问控制;
- 所有SSH跳板逻辑可被替换为 OIDC 认证 + Service Account 的现代身份体系。
自动化运维增强
进一步提升可观测性和稳定性:
- 在跳板机和GPU节点部署 Prometheus + Node Exporter 收集系统指标;
- 配置Grafana仪表盘实时监控GPU利用率、显存占用、温度等关键参数;
- 利用 Ansible 或 Terraform 实现整套环境的声明式部署与版本追踪。
这种融合了经典安全理念与现代容器技术的访问模式,正在成为AI基础设施的标准组成部分。它既尊重了企业对网络安全的刚性要求,又充分照顾了算法工程师对灵活性和响应速度的期待。
最终目标很清晰:让每一位开发者都能像本地运行一样顺畅地使用远程GPU资源,同时让运维团队不必时刻担心安全事件的发生。而这,正是工程艺术的魅力所在。