


高频量化:个人投资者如何实现低成本券商服务器托管(下篇)
接着上文讲解,上文我了解了交易网关的具体概念,大家对这个有一个初步认识。那么关键技术搭建是如何做的?
第三:以下是关键技术
(一)、算法开发:核心是数学模型和机器学习算法。
常用方法包括:
1、预测模型:如时间序列分析(ARIMA(p,d,q)ARIMA(p,d,q))或支持向量机(SVM),用于生成交易信号。
2、风险管理算法:监控仓位风险(如VaR模型),确保在极端市场条件下自动止损。“高频交易策略依赖于复杂的数学模型和算法来预测市场动向”,这些算法通常使用Python或C++实现。
(二)、速度和低延迟优化:交易速度是成败关键:
技术包括:
1、硬件加速:使用FPGA(Field-Programmable Gate Array)或ASIC芯片减少计算延迟,确保交易在微秒级完成。
2、网络优化:部署专用光纤或微波网络,缩短数据传输时间(如从交易所到服务器)。
3、数据实时处理:利用大数据技术(如Apache Kafka或Spark Streaming)处理实时市场数据流,每分钟处理数百万条报价。
4、数据处理和AI集成:高频量化依赖大量数据!
数据源:整合历史和实时数据(如Level 2市场深度数据),用于训练模型。
AI应用:人工智能(如深度学习模型)用于模式识别,例如预测订单流不平衡。“人工智能在量化投资中的应用包括算法交易和数据建模”,这在高频场景中尤为重要。
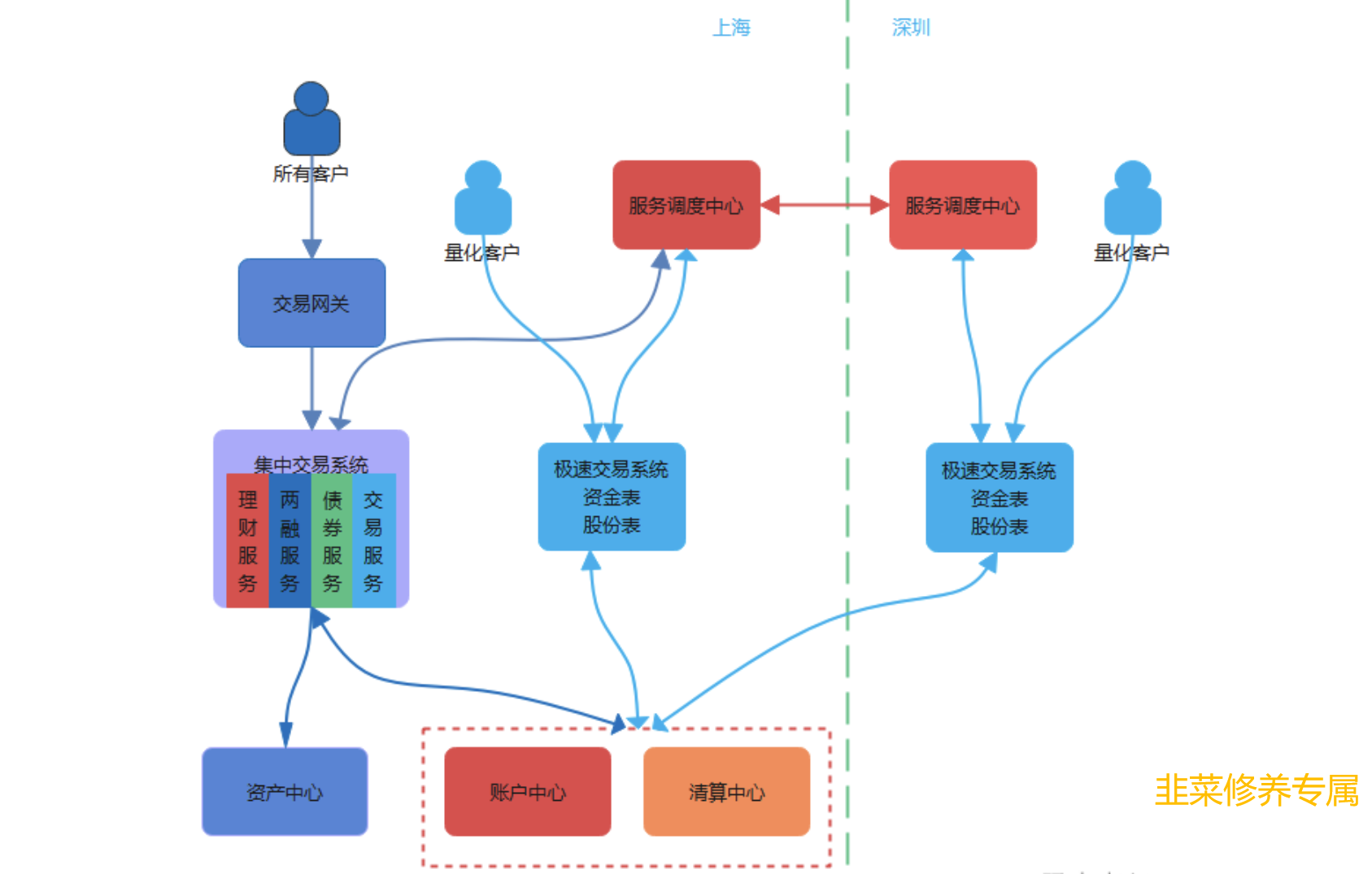
高频量化往往追求极致的交易速度,而公共网络占可优化延迟的80%,所以服务器托管是优先需要解决的事。在这之前,服务器托管基本上只对大型机构开放,但现在个人也能做。
第四、低延迟架构搭建:FPGA与 GPU 的性能博弈
一、高频交易的硬件架构需突破纳秒级延迟瓶颈,FPGA(现场可编程门阵列)与 GPU(图形处理器)是两种主流方案,其性能差异直接决定策略适用场景。
(一)核心性能参数对比
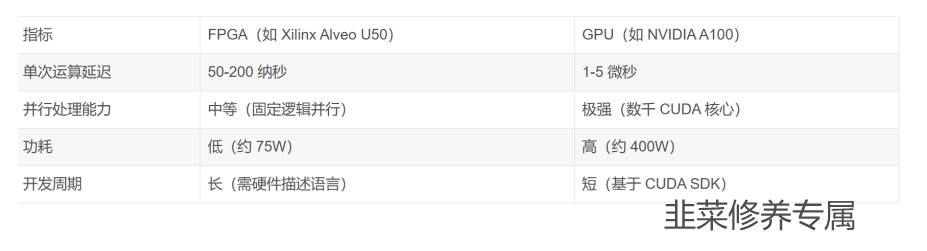
FPGA 凭借硬件级逻辑固化优势,在简单指令执行(如订单校验、报单路由)中延迟显著低于 GPU,适合做市商策略等对响应速度极端敏感的场景。而 GPU 在复杂数据处理(如多维度订单流分析)中更具优势,例如对 10 档订单簿的实时特征提取可实现每秒百万级运算。
(二)架构设计实践
混合部署方案:采用 “FPGA+GPU” 异构架构,FPGA 负责报单指令生成与交易所接口交互,GPU 承担订单流分析与价格预测任务,通过 PCIe 4.0 实现两者纳秒级数据传输。
网络优化:使用 100Gbps 低延迟光模块(如 Arista 7050X3),部署 DPDK(数据平面开发套件)绕过操作系统内核,将网络延迟控制在 1 微秒以内。
二、合规要点:交易所报单速率限制的规避策略
高频交易需严格遵守交易所对报单频率、撤单率的限制,当前上交所、深交所对普通会员的报单速率限制为每秒 800 笔,撤单率不得超过 60%。
(一)速率控制机制
令牌桶算法:通过软件层实现报单速率平滑
优先级队列:将报单请求按紧急程度排序,行情剧烈波动时优先发送交易指令,平缓期减少无效报单。
(二)撤单率优化
智能撤单策略:对未成交订单设置动态超时时间(如 300 毫秒),避免频繁撤单;
隐藏订单使用:在流动性充足的合约中使用冰山订单,减少可见订单数量,降低撤单需求。
三、入门实践建议
硬件起步方案:初期可采用 “CPU+100G 网卡” 架构(延迟约 5-10 微秒),成本控制在 5 万元内,验证策略可行性后再升级 FPGA;
数据获取:通过交易所行情网关接入 Level-2 数据,或使用第三方低延迟行情服务。
合规备案:向券商申请高频交易资格,报备策略类型与预期报单速率,确保符合《证券期货市场程序化交易管理办法》。
高频交易的核心是 “延迟可控、策略简洁、合规优先”。从硬件选型到策略落地,需在性能与成本间平衡,在创新与合规间找到支点。
我们下文继续分享关于高频量化交易个人投资者如何低成本的实现主机托管。
关注韭菜修养,投资伴您成长!







