python数据容器
Python数据容器
数据容器在 Python 中起着至关重要的作用,本文将讲解Python的数据容器,其中包括 列表(list)、元组(tuple)、字符串(str)的创建方式,实例,以及常见的操作方法和实例,让你能够在实际编程中高效灵活的运用这些数据容器操作方法
字符串 列表 元组的内置方法
字符串定义与使用
字符串定义
字符串是 Python 中最常用的数据类型,用来表示和处理文本信息.
在Python中,字符串是不可变的序列,用单引号 '、双引号 " 或 三引号 括起来
str1 = 'abcdefg'
str2 = "hello world"
print(type(str1)) # 如果出现了引号嵌套, 可以 [外双内单] 处理, 或转义:
# eg: I'm Tina
str1 = "I'm Tina"
# or
str2 = 'I'm Tina"
# 注:'I'm Tina'会报错
字符串切片
指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
基本语法
顾头不顾尾,包左不包右
序列名称[开始位置下标:结束位子下标:步长]
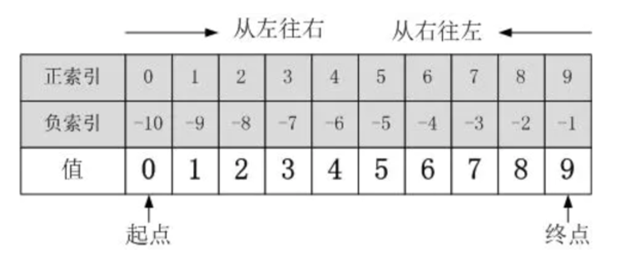
str1 = '0123456789'
str1[0:3:1] # => 012
str1[0:3:2] # => 02 => 每次前进2步
步长可以为负数,正数代表从左向右截取,负数代表从右向左截取
- 不写起始索引, 默认是: 0
- 不写结束索引, 默认是: 字符串的长度
- 不写步长, 默认是: 1
- 不包含结束索引位置对应的数据.正负数均可
# eg:
str1 = '0123456789'
若想对str1进行切片,如下图:
# 1、从2到5开始切片,步长为1
print(str1[2:5:1]) # 234
print(str1[2:5]) # 234
# 2、只有结尾的字符串切片:代表从索引为0开始,截取到索引为5的位置(不包含索引为5的数据)
print(str1[:5]) # 01234
# 3、只有开头的字符串切片:代表从起始位置开始,已知截取到字符串的结尾
print(str1[1:]) # 123456789
# 4、获取或拷贝整个字符串
print(str1[:]) # 0123456789
# 5、调整步阶:类似求偶数
print(str1[::2]) # 02468
# 6、把步阶设置为负整数:类似字符串翻转
print(str1[::-1]) # 9876543210
# 7、起始位置与结束位置都是负数
print(str1[-4:-1]) # 6789
# 8、结束字符为负数,如截取012345678
print(str1[:-1]) # 012345678
案例:
给定一个图片的名称为"report_2026.pdf",代码实现获取这个图片的名称(report_2026)以及这个图片的后缀(.pdf)
filename = 'report_2026.pdf'
# 获取"."的索引
index = 6
name = filename[:index]
print(f'上传文件的名称:{name}')
postfix = filename[index:]
print(f'上传文件的后缀:{postfix}')
字符串的内置方法
字符串变量名.函数名(参数...)
查找方法
查找子串在字符串中的位置或出现的次数
基本语法:
字符串.find(要查找的字符或者子串)
字符串.index(要查找的字符或者子串)
| 函数 | 作用 |
|---|---|
| find() | 检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则返回-1。 |
| index() | 检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则报异常。 |
find()方法
# 定义一个字符串
str1 = 'hello world'
# 查找hello子串是否出现在字符串中
print(str1.find('hello')) # => 0
# 在str1中查找不存在的子串
print(str1.find('and')) # => -1
案例:求文件名与文件类型
str1 = 'music.avi'
# 获取点号的索引下标
ind = str1.find('.')
# 文件名称,文件后缀
print(str1[:ind],str1[ind:])
index()方法
str1 = 'apple, banana, orange'
# 判断apple是否出现在字符串str1中
print(str1.index('apple')) # => 0
print(str1.index('pineapple')) # 报错
修改方法
通过函数(方法)的形式修改字符串中的数据
| 函数 | 作用 |
|---|---|
| replace() | 返回替换后的字符串 |
| split() | 返回切割后的列表序列 |
| count() | 返回字符串中有几个应查找的子字符串 |
replace()方法
基本语法
字符串.replace(要替换的内容, 替换后的内容, 替换的次数-可以省略)
案例:将文章中的所有人工智能换成AI
article = "我认为人工智能必然是未来的方向。人工智能将改变世界。人工智能很重要。你大爷的"
# 把字符串中所有'人工智能'字符替换为'AI'
print(article.replace('人工智能', 'AI'))
# 把字符串中第一个'人工智能'字符替换为'AI'
print(article.replace('人工智能', 'AI', 1))
# 把字符串中'你大爷的'字符替换为'****'
print(article.replace('你大爷的', '****'))
replace主要用于实现关键字替代或过滤功能
split()方法
作用:对字符串进行切割操作,返回一个list()列表类型的数据
str1 = 'apple-banana-orange'
print(str1.split('-')) # [apple, banana, orange]
join()方法
作用:和split()方法正好相反,其主要功能是把序列拼接为字符串
list1 = ['apple', 'banana', 'orange']
print('-'.join(list1)) # 拼接符在前面 => 'apple-banana-orange'
count()方法
作用:查看子字符串在字符串中出现的次数
str1 = 'ok, i say ok! ok?'
print(str1.count('k')) # => 3
列表的定义与使用
列表的定义
Python容器类型的一种, 可以用来同时存储多个元素,可以是不同类型的, 可以是相同类型的, 一般是: 相同类型的
列表序列名称 = [列表中的元素1, 列表中的元素2, 列表中的元素3, ...]
- 可以存储重复元素
- 元素有序
- 元素值可以修改, 且每个元素都有索引, 索引从0开始
列表的取值和长度
取值:
list1 = ['apple', 'banana', 'pineapple']
# 获取列表中的banana
print(list1[1])
切片:
list[开始位置下标:结束位子下标:步长]
获取长度:
len(list)
案例: 利用下标, 把空调取出来
ls1 = ['冰箱', '洗衣机', '空调']
print(ls1[len(ls1)-1]) # => 空调
print(ls1[-1:]) # => ['空调']
print(ls1[len(ls1)-1:]) # => ['空调']
列表的查找方法
| 函数 | 作用 |
|---|---|
| index() | 指定数据所在位置的下标 |
| count() | 统计指定数据在当前列表中出现的次数 |
| in | 判断指定数据在某个列表序列,如果在返回True,否则返回False |
| not in | 判断指定数据不在某个列表序列,如果不在返回True,否则返回False |
案例:
# 定义一个列表
list1 = ['刘备', '关羽', '张飞', '关羽', '赵云']
print(list1.index('刘备')) # 0
# print(list1.index('曹操')) # 报错
print(list1.count('关羽')) # 2
if '刘备' in list1:
print('存在')
else:
print('不存在')
print('曹操' not in list1) # => True
列表的增加方法
| 函数 | 作用 |
|---|---|
| append() | 增加指定数据到列表中 |
| extend() | 列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表 |
| insert() | 指定位置新增数据 |
append()方法
在列表的尾部追加元素
list1 = ['张明', '小丽', '小刘']
# 在列表的尾部追加一个元素"小美"
list1.append('小美')
print(list1) # => ['张明', '小丽', '小刘', '小美']
注意:列表追加数据的时候,直接在原列表里面追加了指定数据,即修改了原列表,故列表为可变类型数据。
extend()方法
列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表
list1 = ['张明', '小丽', '小刘']
list2 = ['关羽', '张飞', '赵云']
list1.extend(list2)
print(list1) # => ['张明', '小丽', '小刘', '关羽', '张飞', '赵云']
# 若extend方法追加元素"曹操"
# list2.extend("曹操")
# print(list2)
# => ['关羽', '张飞', '赵云', '曹', '操'] 所以不适合使用 但可以用list2.extend(["曹操"])
insert()方法
在指定的位置增加元素
list1 = ['董事长', '民工1', '民工2']
# 让董事长的儿子插队到董事长后面
list1.insert(1, '董事长儿子')
print(list1) # => ['董事长', '董事长儿子', '民工1', '民工2']
列表的删除方法
| 函数 | 作用 |
|---|---|
| del列表[索引] | 删除列表中的某个元素 |
| pop() | 删除指定下标的数据(默认为最后一个),并返回该数据 |
| remove() | 移除列表中某个数据的第一个匹配项 |
del删除指定的列表元素
基本语法:
names = ['Tom', 'Rose', 'Jack', 'Jennify']
# 删除Rose
del name[1]
# 打印列表
print(names) # ['Tom', 'Jack', 'Jennify']
pop()方法
基本语法:
names = ['Tom', 'Rose', 'Jack', 'Jennify']
# 删除 Jennify
del_name = names.pop()
# or
# del_name = names.pop(3)
print(del_name) # Jennify
print(names) # ['Tom', 'Rose', 'Jack']
remove()方法
基本语法:
names = ['Tom', 'Rose', 'Jack', 'Jennify']
names.remove('Tom')
print(names) # ['Rose', 'Jack', 'Jennify']
列表的修改方法
| 函数 | 作用 |
|---|---|
| 列表[索引] = 修改后的值 | 修改列表中的某个元素 |
| reverse() | 将数据序列进行倒叙排列 |
| sort() | 对列表序列进行排序 |
基本语法:
list1 = ['貂蝉', '大乔', '小乔', '八戒']
# 修改列表中的元素
list1[3] = '周瑜'
print(list1) # ['貂蝉', '大乔', '小乔', '周瑜']
# 倒叙排序
list2 = [1, 2, 3, 4, 5, 6]
list2.reverse()
print(list2) # [6, 5, 4, 3, 2, 1]
# 升序排序
list3 = [10, 50, 20, 30, 1]
list3.sort() # 升序
# or
# list3.sort(reverse=True) # 降序
print(list3) # [1, 10, 20, 30, 50]
列表的循环遍历
while循环:
list1 = ['貂蝉', '大乔', '小乔']
# 定义计数器
i = 0
# 编写循环条件
while i < len(list1):
print(list1[i])
i += 1
for循环:
list1 = ['貂蝉', '大乔', '小乔']
for i in list1:
print(i)
案例:求相邻元素最大值.编写一个程序,求一个正整数数组中每对相邻元素的最大值。
例如, 输入: [7 8 9 5 6 7 2 3] 输出: [8, 9, 9, 6, 7, 7, 3]
# 1.定义一个正整数数组
numbers = [7, 8, 9, 5, 6, 7, 2, 3]
# 2.初始化一个空列表用于存储相邻元素的最大值
max_values = []
# 3.使用 for 循环遍历数组中的每个相邻元素
for i in range(len(numbers) - 1)
# 4.计算当前元素和下一个元素的最大值
max_value = max(numbers[i], numbers[i + 1])
# 5.将最大值添加到max_values列表中
max_values.append(max_value)
# 7.打印相邻元素的最大值列表
print(f'相邻元素的最大值是:{max_values}')
案例:给定列表original_list其中包含1, 2, 2, 3, 4, 4, 5, 6, 6, 7元素,现在通过编写程序对列表中的数据进行去重
# 1.原始列表
original_list = [1, 2, 2, 3, 4, 4, 5, 6, 6, 7]
# 2.用于存储去重后的列表
unique_list = []
# 3.遍历原始列表
for item in original_list:
if item not in unique_list:
unique_list.append(item)
# 5.输出去重后的列表
print('去重后的列表:', unique_list)
元组的定义与使用
元组可以存储多个数据且元组内的数据不能修改
元组的定义
元组的特点:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型
基本语法:
# 多个数据元组
tuple1 = (10, 20, 30)
# 单个数据元组
tuple2 = (10,)
**注意:**如果定义的元组只有一个数据,那么这个数据后面也要添加都好,否则数据类型为唯一的这个数据的数据类型
元组的相关操作方法
由于元组中的数据不允许修改,所以其操作方法大部分为查询方法
| 函数 | 作用 |
|---|---|
| 元组[索引] | 根据索引下标查找元素 |
| index() | 查找某个数据,如果数据存在返回对应的下标,否则报错,语法和列表、字符串的index方法相同 |
| count() | 统计某个数据在当前元组出现的次数 |
| len() | 统计元组中数据的个数 |
基本语法:
访问元组中的某个元素
nums = (10, 20, 30)
print(nums[2]) # 30
基本语法:
查找某个元素在元组中出现的位置,存在则返回索引下标,不存在则直接报错
nums = (10, 20, 30)
print(nums.index(20)) # 1
基本语法:
统计某个元素在元组中出现的次数
nums = (10, 20, 30, 50, 30)
print(nums.count(30)) # 2
基本语法:
len()方法主要就是求数据序列的长度,字符串、列表、元组等
nums = (10, 20, 30, 50, 30)
print(len(nums)) # 5
案例:
编写一个程序来提取嵌套元组中的唯一元素。
例如: 在嵌套元组((1,2,3),(2,4,6),(2,3,5))中, 2重复出现了3次,3重复出现了2次,但我们的输出列表只会包含2、3一次。
即:[1, 2, 3, 4, 5, 6]
# 1.定义一个嵌套元组
nested_tuple = ((1, 2, 3), (2, 4, 6), (2, 3, 5))
# 2.初始化一个空集合用于存储唯一元素
unique_elements = set()
# 3.使用for循环遍历嵌套元组中的每个子元组
for sub_tuple in nested_tuple:
# 4. 使用 for 循环遍历子元组中的每个元素
for element in sub_tuple:
# 5. 将元素添加到集合中(集合会自动去重)add()方法
unique_elements.add(element)
# 6.将集合转换为列表
unique_list = list(unique_elements)
# 7.打印唯一元素列表
print(f"嵌套元组中的唯一元素是: {unique_list}")
案例:
给定一个元组my_tuple,里面包含1, 2, 3, 4, 5, 6, 7, 8, 9元素,要求统计数字元组中, 奇数的个数
# 1.定义一个数字元组
my_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9)
# 2.初始化奇数计数器
odd_count = 0
# 3.遍历元组中的每个元素
for num in my_tuple:
# 4.检查元素是否为奇数
if num % 2 != 0:
odd_count += 1
# 5.输出奇数的个数
print("元组中奇数的个数:", odd_count)
元组拆包
简单来说就是把一个元组中的数据一个一个拆解出来的过程,就称之为叫做拆包操作。
基本语法:
tuple1 = (10, 20)
# 拆包
num1, num2 = tuple1
以上代码可以简写为
num1, num2 = (10, 20)
还可以进一步简写
num1, num2 = 10, 20
经典案例: 实现两个值的交换
-
引入第三方变量实现数值交换
c1 = '可乐' c2 = '牛奶' # 经过一系列Python操作,把c1和c2中的值进行交换 temp = c1 c1 = c2 c2 = temp print(c1) # 牛奶 print(c2) # 可乐 -
使用元组拆包实现两个变量值交换
c1 = '可乐' c2 = '牛奶' c1, c2 = (c2, c1) print(c1) # 牛奶 print(c2) # 可乐
字典的定义与使用
字典的概念
特点:
-
符号位大括号(花括号) => {}
-
数据为键值对形式出现 => {key:value}
key: 键名, value: 值, 在同一个字典中,key必须是唯一(类似于索引下标)
-
各个键值对之间用逗号隔开
在字典中,键名除了可以使用字符串的形式,还可以使用数值的形式来进行表示
定义:
# 有数据字典
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}
# 空字典
dict2 = {}
dict3 = dict()
在python代码中,字典中的key必须使用引号引起来
字典的增加操作
基本语法:
字典名称[key] = value
注:如果key存在则修改这个key对应的值;如果key不存在则新增此键值对。
案例:定义一个空字典,然后添加name、age以及address这样的3个key
# 1.定义一个空字典
person = {}
# 2.向字典中添加数据
person['name'] = '刘备'
person['age'] = 40
person['address'] = '蜀中'
# 3、使用print方法打印person字典
print(person)
注:列表、字典为可变类型
字典的删除操作
-
del字典名称[key]: 删除指定元素
# 1.定义一个有数据的字典 person = {'name':'王大锤', 'age':28, 'gender':'male', 'address':'北京市海淀区'} # 2.删除字典中的某个元素(如gender) del person['gender'] # 3.打印字典 print(person) # {'name':'王大锤', 'age':28, 'address':'北京市海淀区'} -
clear()方法:清空字典中的所有key
# 1.定义一个有数据的字典 person = {'name':'王大锤', 'age':28, 'gender':'male', 'address':'北京市海淀区'} # 2.使用clear()方法清空字典 person.clear() # 3.打印字典 print(person) # {}
字典的修改操作
基本语法:
字典名称[key] = value
注:如果key存在则修改这个key对应的值;如果key不存在则新增此键值对。
案例:
# 1.定义字典
person = {'name':'孙悟空', 'age': 600, 'address':'花果山'}
# 2.修改字段中的数据(address)
person['address'] = '东土大唐'
# 3.打印字典
print(person)
字典的查找操作
查询方法:使用具体的某个key查询数据,如果未找到,则可直接报错
字典序列[key]
字典的相关查询方法
| 函数 | 作用 |
|---|---|
| keys() | 以列表返回一个字典所有的键 |
| values() | 以列表返回一个字典所有的值 |
| items() | 以列表返回可遍历的(键, 值)元组数据 |
案例:
提取person字典中的所有key
# 1.定义一个字典
person = {'name':'Tina', 'age':18, 'mobile':'13765022249'}
# 2.提取字典中的name,age,mobile属性
print(person.keys()) # dict_keys(['name', 'age', 'mobile'])
案例:
提取person字典中的所有value值
# 1.定义一个字典
person = {'name':'Tina', 'age':18, 'mobile':'13765022249'}
# 2.提取字典中的Tina,18,13765022249属性
print(person.values()) # dict_values(['Tina', 18, '13765022249'])
案例:
使用items()方法提取数据
# 1.定义一个字典
person = {'name':'Tina', 'age':18, 'mobile':'13765022249'}
# 2.调用items方法获取数据
print(person.items()) # dict_items([('name', '貂蝉'), ('age', 18), ('mobile', '13765022249')])
# or
# 3.结合for循环对字典中的数据进行遍历
for key,value in person.items():
print(f'{key}:{value}')
# name:Tina
# age:18
# mobile:13765022249
注:
list1 = [('name', '貂蝉'), ('age', 18), ('mobile', '13765022249')]
# (键, 值)元组数据组成的数组可直接按key,value遍历
for key,value in list1:
print(f'{key}:{value}')
# name:Tina
# age:18
# mobile:13765022249
案例:
统计你输入的字符串中每个字符出现的次数
# 1.定义一个字符串
str1 = input('请随机输入一个字符串: ')
# 2.初始化一个空字典来存储字符及字符出现的次数
char_count = {}
# 3.遍历字符串,获取每个字符
for char in str1:
# 4. 如果字符存在与字典中,则计数加1
if char in char_count:
char_count[char] += 1
# 5. 如果字符不存在与字典中,则初始化计数为1
else:
char_count[char] = 1
# 6.遍历字典,输出每个字符出现的次数
for char, count in char_count.items():
print(f'字符{char}出现的次数为{count}')
案例
将字符串 str1 = “name=Tom;age=18;city=Beijing”
换为字典dict1 = {‘name’:‘Tom’, ‘age’:18, ‘city’:‘Beijing’}
# 1.定义一个字符串
str1 = "name=Tom;age=18;city=Beijing"
# 2.初始化一个空字典用于存储转换后的键值对
dict1 = {}
# 3.使用split()方法,让str1通过";"分割成一个键值对列表
newList = str1.split(";")
# 4.循环遍历newlist得到每个键值对字符串
for item in newList:
# 5.使用split()方法再次分割键值对字符串,得到键和值
key, value = item.split("=")
# 6.将键和值添加到字典中
dict1[key] = value
# 7. 打印转换后的字典
print(f"转换后的字典是: {dict1}")
集合的定义与使用
集合(set)是一个无序的不重复元素序列。
① 天生去重
② 无序
集合的定义
在python中可以使用花括号{}或者set()方法来定义集合,但若定义的集合是一个空集合的话,只能使用set()方法
# 定义一个集合
s1 = {10, 20, 30, 40, 50}
print(s1) # 无序 {50, 20, 40, 10, 30}
print(type(s1)) # 集合的增加操作
add()
向集合中增加一个元素(单一)
students = set()
students.add('李哲')
students.add('刘毅')
print(students) # {'李哲', '刘毅'}
集合的删除操作
remove()
删除集合中的指定数据,如果数据不存在则报错
# 1.定义一个集合
products = {'刘备', '曹操', '孙权', '诸葛亮'}
# 2.使用remove方法删除白菜这个元素
products.remove('曹操')
print(products) # {'刘备', '诸葛亮', '孙权'}
集合中的查操作
in: 判断某个元素是否在集合中,如果在,则返回True,否则返回False
not in: 判断某个元素不在集合中,如果不在,则返回True,否则返回False
# 定义一个set集合
s1 = {'刘备', '曹操', '孙权'}
# 判断刘备是否在s1集合中
if '刘备' in s1:
print('刘备在s1集合中')
else:
print('刘备没有出现在s1集合中')
集合的遍历操作
for i in 集合:
print(i)
案例:
编写一个程序来统计缺失的数字并返回他们的总和.缺失的数字是指给定列表中两个极端(最大和最小数字)之间没有出现的数字.
例如,在列表[2,5,3,7,5,7]中,两个极端(即2和7)之间缺失的数字是4和6.
# 1. 从输入获取一个整数列表
numbers = [2, 5, 3, 7, 5, 7]
# 2. 找到列表中的最小值
min_num = min(numbers)
# 3. 找到列表中的最大值
max_num = max(numbers)
# 4. 初始化一个集合用于存储列表中的所有数字
number_set = set(numbers)
# 5. 初始化一个变量用于存储缺失数字的总和
missing_sum = 0
# 6. 遍历从最小值到最大值之间的每个数字
for num in range(min_num + 1, max_num):
# 7.检查数字是否不在集合中
if num not in number_set:
# 8. 如果不在,将数字添加到缺失数字的总和中
missing_sum += num
# 9. 打印缺失数字的总和
print(f"缺失的数字之和是:{missing_sum}")