DSP与通用CPU区别
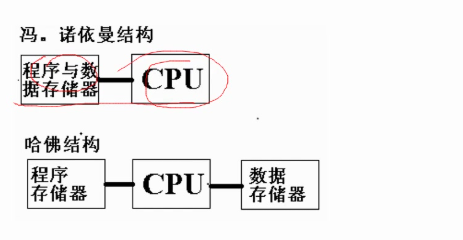
1. 核心架构差异:冯·诺依曼 vs 哈佛结构
-
通用 CPU(如 x86、ARM) 采用 冯·诺依曼结构(Von Neumann Architecture):
- 程序存储器与数据存储器共享同一地址空间和单一总线。
- CPU 在一个时钟周期内只能访问一次存储器(取指令或读/写数据),无法同时进行。
- 导致执行一条乘法指令需 4 个时钟周期(4 cycles),因需多次访问内存(取操作码、取操作数1、取操作数2、存结果)。
-
DSP(Digital Signal Processor) 采用 哈佛结构(Harvard Architecture):
- 程序存储器与数据存储器物理分离,拥有独立的地址总线与数据总线。
- CPU 可在同一时钟周期内并行访问程序存储器与数据存储器。
- 显著提升带宽:理论带宽为冯·诺依曼结构的 2 倍。
- 支持单周期完成乘法等核心信号处理运算(即 1 cycle per MAC)。
2. 存储与总线设计对比
-
冯·诺依曼结构(CPU):
- 单一存储空间通道(single memory space channel)。
- 所有指令与数据通过同一总线传输 → 存在总线争用瓶颈。
- 举例:执行
A = B × C需依次:- 从内存取指令
MUL - 从内存取
B - 从内存取
C - 将结果
A写回内存
⇒ 共 4 次内存访问,耗时长。
- 从内存取指令
-
哈佛结构(DSP):
- 存储空间划分为两个独立区域:
- 程序存储器(Program Memory):存放指令。
- 数据存储器(Data Memory):存放操作数与结果。
- 两组总线(Program Bus + Data Bus)同时连接至 CPU 内核。
- 支持同时取指令 + 读/写数据 → 消除访存瓶颈。
- 存储空间划分为两个独立区域:
3. 指令执行效率与流水线机制
-
CPU 的典型执行流程(无深度流水线):
- 一个指令周期 = 取指(IF)→ 译码(ID)→ 执行(EX)→ 访存(MEM)→ 写回(WB)。
- 若无流水线优化,每条指令需 5 个周期;即使有基础流水线,仍受限于单总线结构。
-
DSP 的深度流水线(Pipelining):
- 利用哈佛结构的双总线优势,实现多级并行流水线。
- 示例(3 级流水线):
- Cycle 1:取指令 1(IF₁)
- Cycle 2:执行指令 1(EX₁) + 取指令 2(IF₂)
- Cycle 3:写回指令 1(WB₁) + 执行指令 2(EX₂) + 取指令 3(IF₃)
- 实际现代 DSP 流水线深度可达 5–6 级甚至 9 级,极大提升吞吐率。
- 效果:每个时钟周期可完成 1 条新指令的输出(steady-state throughput = 1 instruction/cycle)。
4. 专用指令与硬件加速能力
-
DSP 的专用硬件单元:
- 集成 MAC 单元(Multiply-Accumulate Unit):专为数字信号处理中的卷积、滤波等核心运算设计。
- 支持 单周期 MAC 操作(如
A = A + B × C),无需软件循环模拟。 - 例如:FIR 滤波器中 N 阶计算,DSP 可用 N 条单周期 MAC 指令完成;CPU 需 N×4 周期(若无 SIMD)。
-
CPU 的通用性代价:
- 乘法/加法需调用通用 ALU,且通常需多条指令组合(如
MUL,ADD分开)。 - 无专用累加寄存器,中间结果需频繁存回内存 → 增加延迟与功耗。
- 乘法/加法需调用通用 ALU,且通常需多条指令组合(如
5. 浮点运算与协处理器依赖
-
CPU 的浮点处理:
- 早期 CPU 浮点能力弱,依赖 FPU(Floating Point Unit)协处理器(如 Intel 8087)。
- 即使集成 FPU,浮点运算仍较慢,且需额外指令调度。
- 与主 CPU 核通信存在延迟(参数下发 + 结果回传)。
-
DSP 的浮点支持:
- 高端 DSP(如 TI C6000 系列)内置高性能浮点单元(FP Unit)。
- 部分定点 DSP 通过 Q 格式(Fixed-Point Q-format) 高效模拟浮点,避免协处理器开销。
- 关键:无需外部协处理器交互,所有运算在片内完成,延迟极低。
6. 实际性能影响总结
| 特性 | 通用 CPU(冯·诺依曼) | DSP(哈佛结构) |
|---|---|---|
| 存储架构 | 程序/数据共用存储空间 | 程序/数据物理分离 |
| 总线数量 | 1 组总线 | ≥2 组独立总线 |
| 单周期访存能力 | 1 次(指令或数据) | 2 次(指令 + 数据并行) |
| 乘法执行周期 | 4+ cycles | 1 cycle(含 MAC) |
| 循环控制 | 软件分支(有开销) | 硬件零开销循环 |
| 流水线深度 | 中等(通常 3–5 级) | 深度(5–9 级),高吞吐 |
| 适用场景 | 通用计算、操作系统、GUI | 实时信号处理、音频/视频编解码、雷达、通信基带 |