Day16 不平衡数据集的处理@浙大疏锦行
在机器学习任务中(不包含深度学习),数据不平衡指的是分类问题中,不同类别数目
不同导致模型会侧重于学习多数类的信息,而忽略少数类信息的学习。标准算法的优化
目标(如最小化整体误差)会使其优先拟合多数类,因为这样做能更快地降低总误差。
对少数类样本的识别能力不足(低召回率),即使整体准确率看起来很高。
处理不平衡数据的方法主要分为三大类:数据层面、算法层面和评估指标层面。
1.数据层面:通过调整训练集的类别分布来缓解不平衡问题。
●过采样:增加少数类的样本数目-smote插值、随机过采样
●欠采样:删除多数类的样本-ENN数据清洗、随机欠采样
●组合采样策略:结合过采样和欠采样策略-SMOTE+ENN
2.算法层面:不改变数据,而是调整模型训练过程或使用对不平衡数据鲁棒的算法。
●类别权重调整:在损失函数中为少数类样本赋予更高权重,也称为代价敏感学习。
●选择对不平衡数据鲁棒的方法,比如集成学习方法,尤其是Adaboost,为了不平衡
数据而诞生。
3.评估指标层面:固定算法,修改评估指标
●选择F1分数让模型学习更加均衡
●移动阀值改变混淆矩阵的值:算法得到概率,概率+阀值=混淆矩阵
对心脏病数据集利用今天学到的方法,并且结合交叉验证+超参数调优
1.数据预处理
2.建立基模型,采用随机森林模型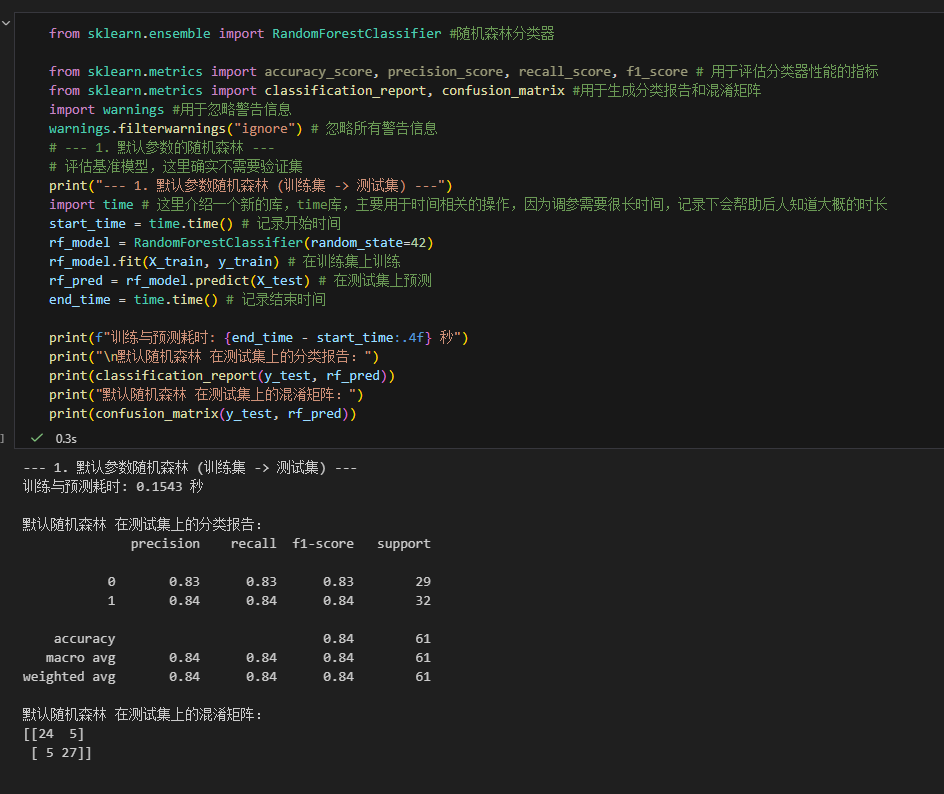
添加采样后的代码
# 以下是添加的过采样代码
# 1. 随机过采样
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=42) # 创建随机过采样对象
X_train_ros, y_train_ros = ros.fit_resample(X_train, y_train) # 对训练集进行随机过采样
print("随机过采样后训练集的形状:", X_train_ros.shape, y_train_ros.shape)
# 训练随机森林模型(使用随机过采样后的训练集)
rf_model_ros = RandomForestClassifier(random_state=42)
start_time_ros = time.time()
rf_model_ros.fit(X_train_ros, y_train_ros)
end_time_ros = time.time()
print(f"随机过采样后训练与预测耗时: {end_time_ros - start_time_ros:.4f} 秒")
# 在测试集上预测
rf_pred_ros = rf_model_ros.predict(X_test)
print("
随机过采样后随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_ros))
print("随机过采样后随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_ros))
# 2. SMOTE过采样
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
print("SMOTE过采样后训练集的形状:", X_train_smote.shape, y_train_smote.shape)
# 训练随机森林模型(使用SMOTE过采样后的训练集)
rf_model_smote = RandomForestClassifier(random_state=42)
start_time_smote = time.time()
rf_model_smote.fit(X_train_smote, y_train_smote)
end_time_smote = time.time()
print(f"SMOTE过采样后训练与预测耗时: {end_time_smote - start_time_smote:.4f} 秒")
# 在测试集上预测
rf_pred_smote = rf_model_smote.predict(X_test)
print("
SMOTE过采样后随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_smote))
print("SMOTE过采样后随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_smote))
# 3. ENN欠采样
from imblearn.under_sampling import EditedNearestNeighbours
print("
--- 3. ENN欠采样 ---")
enn = EditedNearestNeighbours()
X_train_enn, y_train_enn = enn.fit_resample(X_train, y_train)
print("ENN欠采样后训练集的形状:", X_train_enn.shape, y_train_enn.shape)
print("ENN欠采样后各类别样本数量:")
print(pd.Series(y_train_enn).value_counts().sort_index())
# 训练随机森林模型(使用ENN欠采样后的训练集)
rf_model_enn = RandomForestClassifier(random_state=42)
start_time_enn = time.time()
rf_model_enn.fit(X_train_enn, y_train_enn)
end_time_enn = time.time()
print(f"ENN欠采样后训练与预测耗时: {end_time_enn - start_time_enn:.4f} 秒")
# 在测试集上预测
rf_pred_enn = rf_model_enn.predict(X_test)
print("
ENN欠采样后随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_enn))
print("ENN欠采样后随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_enn))
# 4. SMOTE + ENN 组合采样
from imblearn.combine import SMOTEENN
print("
--- 4. SMOTE + ENN 组合采样 ---")
smote_enn = SMOTEENN()
X_train_smote_enn, y_train_smote_enn = smote_enn.fit_resample(X_train, y_train)
print("SMOTE+ENN组合采样后训练集的形状:", X_train_smote_enn.shape, y_train_smote_enn.shape)
print("SMOTE+ENN组合采样后各类别样本数量:")
print(pd.Series(y_train_smote_enn).value_counts().sort_index())
# 训练随机森林模型(使用SMOTE+ENN组合采样后的训练集)
rf_model_smote_enn = RandomForestClassifier(random_state=42)
start_time_smote_enn = time.time()
rf_model_smote_enn.fit(X_train_smote_enn, y_train_smote_enn)
end_time_smote_enn = time.time()
print(f"SMOTE+ENN组合采样后训练与预测耗时: {end_time_smote_enn - start_time_smote_enn:.4f} 秒")
# 在测试集上预测
rf_pred_smote_enn = rf_model_smote_enn.predict(X_test)
print("
SMOTE+ENN组合采样后随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_smote_enn))
print("SMOTE+ENN组合采样后随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_smote_enn))
# 汇总比较所有方法
print("
=== 所有方法性能汇总比较 ===")
methods = ['默认', '随机过采样', 'SMOTE', 'ENN', 'SMOTE+ENN']
predictions = [rf_pred, rf_pred_ros, rf_pred_smote, rf_pred_enn, rf_pred_smote_enn]
results = []
for i, (method, pred) in enumerate(zip(methods, predictions)):
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
results.append([method, accuracy, precision, recall, f1])
results_df = pd.DataFrame(results, columns=['方法', '准确率', '精确率', '召回率', 'F1分数'])
print(results_df.round(4))