2025_NIPS_Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
文章核心总结与翻译
一、主要内容
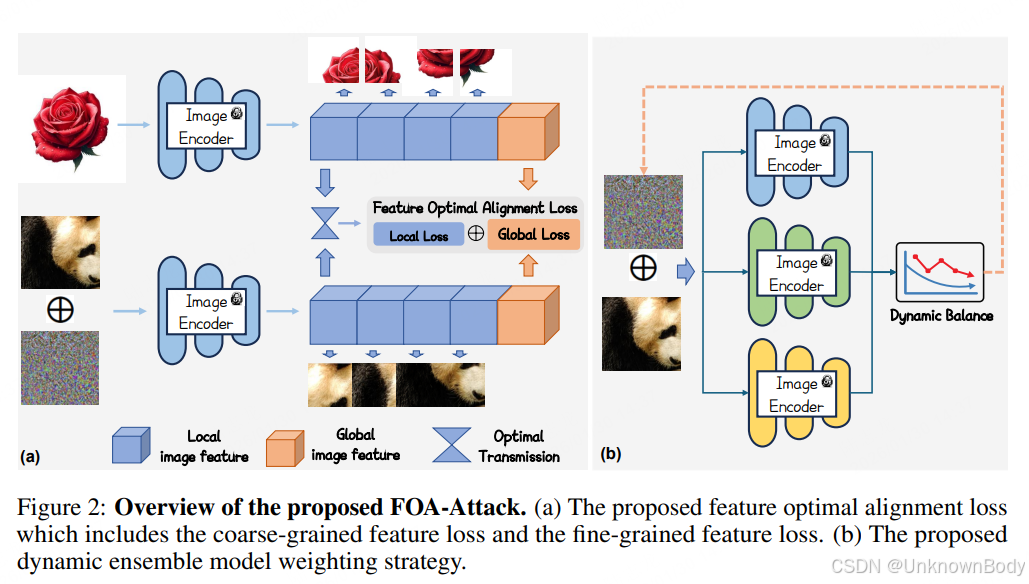
本文针对多模态大语言模型(MLLMs)的对抗样本迁移性不足问题,提出了基于特征最优对齐的靶向迁移对抗攻击方法FOA-Attack。该方法通过联合对齐全局与局部特征、动态平衡多模型权重,提升对抗样本在开源及闭源MLLMs上的迁移攻击效果。实验验证了其在Qwen、LLaVa、GPT-4o、Claude-3.7等14种模型上的优越性,尤其在闭源和推理增强型模型上表现突出。
二、创新点
- 提出全局-局部联合对齐框架:全局层面采用余弦相似度损失对齐粗粒度特征,局部层面通过K-Means聚类提取紧凑特征,并将对齐问题转化为最优传输(OT)问题,设计局部聚类OT损失实现细粒度对齐。
- 动态集成模型加权策略:根据不同模型的损失收敛速率自适应调整权重,避免优化偏向易训练任务,提升对抗迁移性。
- 兼顾有效性与泛化性:在严格阈值(0.5)下仍保持高攻击成功率(ASR),且对防御机制(如JPEG压缩、Comdefend)具有强抗性。
三、核心章节翻译(Markdown格式)
Abstract
多模态大语言模型(MLLMs)仍然容易受到可迁移对抗样本的攻击。现有方法通