


现代文件上传架构权威指南:从二进制流到分布式对象存储的深度剖析
1. 引言:比特流的宏大旅程
在当今的互联网基础设施中,文件上传不仅是最基础的功能之一,也是系统设计中最为复杂的环节之一。对于终端用户而言,上传一个文件仅仅是一次点击或拖拽的动作;然而,对于系统架构师和后端工程师来说,这却是一场涉及网络协议、内存管理、二进制流解析、分布式存储以及高阶安全防御的精密编排。
从客户端发起请求的那一刻起,数据便开始了它在七层网络模型中的漫长旅程。它首先被封装进 TCP 数据包,穿越不可靠的公网环境,抵达服务器的网络接口卡(NIC)。随后,操作系统内核将其搬运至用户空间,应用层服务器(如 Nginx 或 Node.js)必须在毫秒级的时间内决定如何处理这股汹涌而来的比特流:是将其缓冲在内存中?还是直接流式传输到磁盘?抑或是实时转发至云端的对象存储?
在这个过程中,系统面临着多重挑战:
- 协议复杂性:HTTP 协议最初是为文本传输设计的,如何高效地传输巨大的二进制文件(如 4K 视频或基因测序数据)而不引入过多的编码开销?
- 资源限制:服务器的内存是有限的。如何在数万并发上传的场景下,防止内存溢出(OOM)并保持低延迟?
- 安全威胁:文件上传接口是黑客最青睐的攻击向量。从简单的 Webshell 到复杂的图像多语种(Polyglot)攻击,防御者必须在比特级别上进行审查。
- 分布式一致性:在微服务架构和云原生环境下,如何保证文件在上传、处理(如转码、压缩)和分发过程中的状态一致性?
本报告将以“显微镜”般的精度,详细剖析文件上传的全生命周期。我们将深入探讨 multipart/form-data 的 RFC 标准实现,解析服务器端流式处理的算法细节,揭示伪装文件的内部结构与检测机制,并最终构建一个基于对象存储(S3)和内容分发网络(CDN)的高可用、高安全的企业级上传架构。
2. 传输层协议核心:HTTP Multipart 标准与二进制流
2.1 传统编码的局限性与 Multipart 的诞生
在 Web 发展的早期,表单提交主要依赖于 application/x-www-form-urlencoded 内容类型。这种编码方式对于简单的键值对(如用户名、密码)非常有效。然而,当涉及到二进制文件传输时,其局限性暴露无遗。
2.1.1 URL 编码的效率黑洞
application/x-www-form-urlencoded 要求将非字母数字字符转换为百分号编码(Percent-Encoding)。对于二进制文件,其字节值范围是 0x00 到 0xFF。这意味着大部分字节都需要被编码。例如,一个字节如果不是 ASCII 安全字符,就会被转换为三个字符(例如 0x1F 变为 %1F)。这种机制导致了严重的数据膨胀——文件体积平均增加约 200% 到 300%。对于一个 1GB 的视频文件,这不仅意味着传输 3GB 的数据,更意味着客户端和服务器需要消耗大量的 CPU 周期来进行编码和解码运算。
2.1.2 Base64 的折中与不足
另一种常见的方案是 Base64 编码,常用于 JSON API (application/json) 中传输小文件。Base64 将每 3 个字节的数据映射为 4 个 ASCII 字符。虽然比 URL 编码高效,但它仍然带来了约 33% 的体积膨胀。此外,将大文件作为 JSON 字符串处理要求解析器将整个 JSON 对象加载到内存中,这对于大文件上传来说是不可接受的。
2.2 深入解析 multipart/form-data
为了解决上述问题,RFC 1867 提出了 multipart/form-data 标准,随后在 RFC 2388 和 RFC 7578 中得到了进一步完善。这是一种在单个 HTTP 请求体中封装多个数据部分的机制,它允许文本字段和二进制文件混合传输,且二进制数据可以以“原样”(Raw Binary)发送,无需进行低效的编码。
下面这张图展示了一个 multipart/form-data 请求的详细结构,包括 HTTP 头部、边界(Boundary)以及各部分数据的封装。
2.2.1 边界(Boundary)的微观结构
Multipart 协议的核心在于“边界”(Boundary)。这是一个由客户端生成的唯一字符串,用于分隔请求体中的不同部分。为了防止边界字符串意外出现在文件内容中,浏览器通常会生成一个包含大量随机字符的复杂字符串。
2.2.2 协议层面的解析挑战
这种结构虽然高效,但给服务器端的解析带来了挑战。服务器不能简单地读取整个 Body,因为它可能包含多个文件和字段。解析器必须实现一个状态机(State Machine),逐字节地扫描输入流:
- 寻找边界状态:扫描流,匹配边界字符串。
- 解析头部状态:一旦找到边界,读取后续字节直到遇到双换行符(
- 读取数据状态:从流中读取数据并写入目标(磁盘或内存),同时持续检查流中是否出现了下一个边界的前缀。
这种“流中找界”的机制是所有 Multipart 解析库(如 Node.js 的 busboy、Java 的 Commons FileUpload)的核心逻辑。
2.3 传输层的隐形因素:TCP 窗口与背压
文件上传不仅仅是应用层协议的交互,还深受传输层 TCP/IP 行为的影响。
2.3.1 TCP 流量控制与滑动窗口
当客户端上传文件时,操作系统内核将文件数据复制到 TCP 发送缓冲区。服务器端内核接收数据并放入接收缓冲区,等待应用程序读取。如果服务器端的应用逻辑处理速度(例如写入磁盘的速度)慢于网络接收速度,接收缓冲区就会填满。
此时,TCP 的流量控制机制介入。服务器会向客户端发送一个“零窗口”(Zero Window)通告,指示客户端暂停发送数据。这种机制称为背压(Backpressure)。在文件上传架构中,正确处理背压至关重要。如果应用层不处理背压(例如,在 Node.js 中不监听 drain 事件而盲目写入),会导致内存迅速耗尽。
2.3.2 HTTP/2 与帧(Frames)
在 HTTP/2 和 HTTP/3 中,multipart 的语义保持不变,但底层传输发生了根本变化。数据不再是单一的连续流,而是被分割成多个二进制帧(DATA Frames)。上传的大文件可能被拆分成数千个帧,并与其他并发请求的帧交错传输(多路复用)。
这就要求服务器端的 HTTP/2 解码器先将乱序到达的帧重组为逻辑上的流,然后再交给 Multipart 解析器处理。虽然这增加了 CPU 的开销,但它解决了 HTTP/1.1 中的**队头阻塞(Head-of-Line Blocking)**问题——即一个大文件上传不会再阻塞同一连接上的其他小请求(如心跳检查或 API 调用)。
3. 服务器端解析与流式架构设计
处理文件上传的核心工程挑战在于内存管理。对于现代 Web 服务器而言,“缓冲整个文件”(Buffering)是不可接受的架构模式。
3.1 缓冲模式的致命缺陷
在简单的实现中,服务器可能会等待整个 HTTP 请求体接收完毕,将其存储在 RAM 中的一个大缓冲区(Buffer)里,然后再进行处理。
- 内存溢出风险:如果服务器有 8GB 内存,而 100 个用户同时上传 100MB 的文件,内存将瞬间耗尽,导致进程崩溃或触发 OOM Killer。
- 延迟增加:用户必须等待文件完全上传到服务器内存后,服务器才能开始处理(如验证格式或上传到 S3)。这显著增加了端到端的延迟。
3.2 流式处理(Streaming)架构
企业级架构必须采用流式处理。流(Stream)是一种抽象接口,允许数据被分块处理。
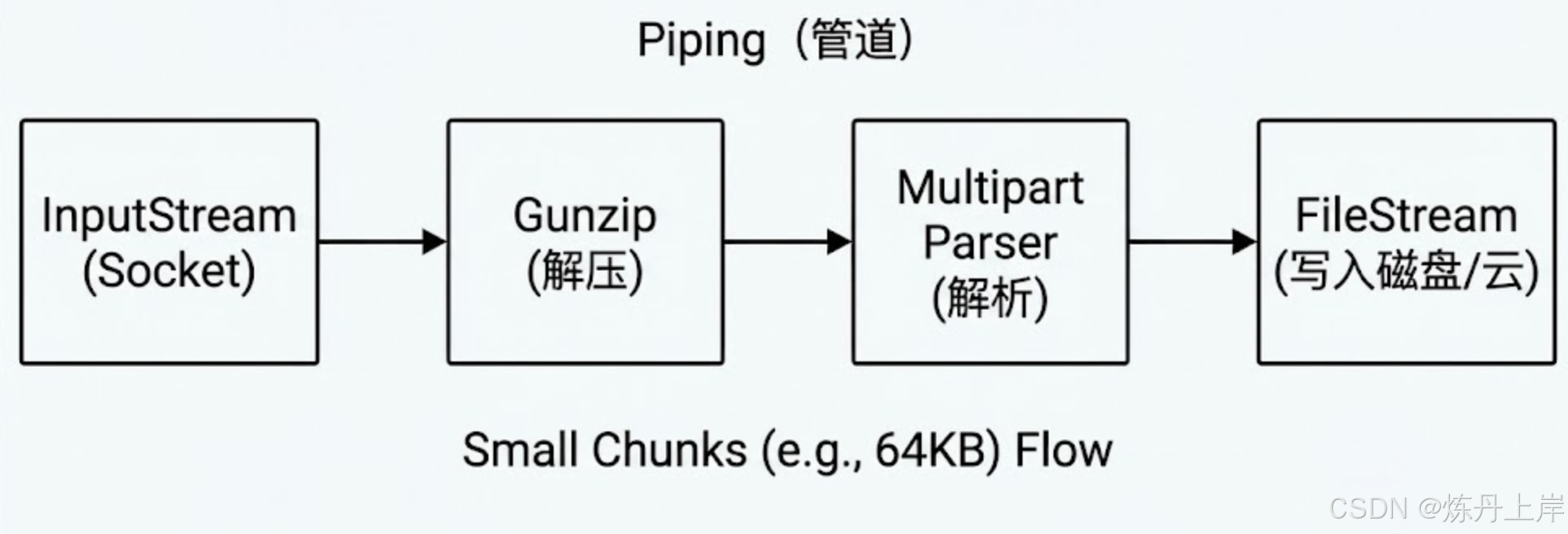
3.2.1 管道(Piping)机制
在 Node.js 或 Go 等语言中,流式处理通过“管道”连接。下面的图表展示了一个典型的流式处理管道,数据以小块的形式从输入流流向最终的存储,全程无需将完整文件加载到内存中。
在这个链条中,数据以小块(Chunk,例如 64KB)的形式流动。任何时刻,内存中只有当前正在处理的那一小块数据。这使得一个 512MB 内存的微服务容器能够轻松处理数 GB 的文件上传。
3.2.2 高级边界检测算法:Boyer-Moore 与滑动窗口
为了在流中高效地定位边界字符串,解析器不能使用简单的字符串查找,因为这在最坏情况下的时间复杂度是 O(N*M)。高效的解析器通常实现 Boyer-Moore 算法或其变体。
滑动窗口技术细节:
- 缓冲区维护:解析器维护一个长度等于边界字符串长度的滑动窗口。
- 字节进入:每当从 Socket 读取一个字节,它进入窗口的右侧,最左侧的字节移出。
- 部分匹配表:算法利用边界字符串的特征(如重复字符的位置),在发现不匹配时,能够安全地跳过多个字节,而不是逐个移动。这大大提高了扫描速度。
- 跨块边界(Boundary Splitting):最复杂的情况是边界字符串被切分在两个数据块之间(例如,前一半在 Chunk A 的末尾,后一半在 Chunk B 的开头)。解析器必须具备状态记忆能力,将 Chunk A 末尾的可疑字节暂存,待 Chunk B 到达后拼接验证。
3.3 无磁盘架构(Diskless Architecture)
在云原生架构(如 Kubernetes + Docker)中,容器通常具有短暂且有限的文件系统。因此,将上传的文件临时写入本地 /tmp 目录再上传到 S3 是一种反模式(Anti-pattern)。
透传模式(Pass-through): 最佳实践是构建一个透传流。Multipart 解析器输出的文件流直接被“管道化”到 S3 客户端的 putObject 方法中。
// Node.js 伪代码示例
busboy.on('file', (fieldname, fileStream, filename) => {
const upload = s3.upload({
Bucket: 'my-bucket',
Key: filename,
Body: fileStream // 直接传入流,而非 Buffer
});
});
这种架构下,Web 服务器仅仅充当了流量的搬运工和校验者,磁盘 I/O 降为零,极大提升了吞吐量。
4. 文件解析与格式路由:从 MIME 到魔法数字
当文件流到达服务器时,系统必须回答两个关键问题:这是什么文件?该把它送到哪里?
4.1 格式路由(Format Routing)的设计模式
现代应用通常需要处理多种类型的文件,且每种文件的处理逻辑截然不同:
- 图片:需要压缩、生成缩略图、去除元数据。
- 视频:需要转码、切片(HLS/DASH)。
- 文档(PDF/Excel):需要提取文本建立索引,或转换为预览图。
- 音频:需要提取波形数据。
为了管理这种复杂性,我们可以采用策略模式(Strategy Pattern)结合内容路由(Content-Based Routing)。
架构组件:
- 分发器(Dispatcher):作为入口,解析请求头和文件前几个字节,决定文件类型。
- 处理器注册表(Processor Registry):维护
FileType -> Handler的映射关系。 - 处理策略(Processing Strategy):具体的业务逻辑类(例如
ImageProcessor,VideoProcessor)。
代码逻辑流:
const processor = ProcessorFactory.getProcessor(detectedMimeType);
await processor.handle(fileStream);
这种设计符合开闭原则(Open/Closed Principle),新增一种文件类型只需增加一个新的策略类,无需修改核心路由逻辑。
4.2 MIME 类型的欺骗性
浏览器在发送文件时,会根据文件的扩展名添加 Content-Type 头部(例如 image/jpeg)。然而,这个头部是完全不可信的。攻击者可以将一个恶意的 exploit.exe 重命名为 holiday.jpg,浏览器就会诚实地将其标记为 image/jpeg 发送给服务器。
如果服务器仅依赖 Content-Type 进行路由或验证,那么它实际上是在邀请攻击者绕过安全检查。
4.3 魔法数字(Magic Numbers)与深度检测
文件类型的真实身份隐藏在其二进制数据的头部,这被称为文件签名或魔法数字(Magic Numbers)。
4.3.1 常见文件签名表
服务器必须读取文件流的前 4 到 32 个字节,并将其转换为十六进制字符串与已知签名进行比对。
| 文件类型 | 扩展名 | 魔法数字 (Hex Signature) | 偏移量 |
|---|---|---|---|
| JPEG | .jpg, .jpeg | FF D8 FF | 0 |
| PNG | .png | 89 50 4E 47 0D 0A 1A 0A | 0 |
| GIF | .gif | 47 49 46 38 37 61 (GIF87a) | 0 |
25 50 44 46 2D (%PDF-) | 0 | ||
| ZIP | .zip | 50 4B 03 04 | 0 |
| Java Class | .class | CA FE BA BE | 0 |
| Bash Script | .sh | 23 21 (#!) | 0 |
4.3.2 检测算法实现
在流式处理中,检测魔法数字需要一种“窥视”(Peeking)机制。解析器需要读取流的头部字节进行验证,但不能“消耗”这些字节,因为后续的图像处理库或存储服务需要完整的文件内容。
通常的做法是使用带缓冲的流(Buffered Stream):
- 读取流的前 26 字节(足以覆盖大多数文件类型)。
- 与签名数据库比对。
- 如果匹配失败,立即中断流并返回 400 错误。
- 如果匹配成功,将这 26 字节重新推回流的头部(unshift),或者使用复合流将头部 Buffer 与剩余流拼接,传给下游处理。
5. 伪装文件与高阶安全防御
仅仅检查魔法数字是不够的。黑客技术已经进化到了**多语种文件(Polyglot Files)**的阶段,这种文件同时满足两种或多种文件格式的规范。
5.1 伪装文件的解剖
5.1.1 GIFAR (GIF + JAR)
GIFAR 攻击利用了 GIF 和 JAR(基于 ZIP)格式的松散性。
- GIF 格式:定义了头部结构,但忽略文件末尾的垃圾数据。
- JAR 格式:通过文件末尾的目录索引读取内容,允许文件头部存在垃圾数据。
攻击者可以将一个恶意的 Java JAR 文件拼接在一个合法的 GIF 图片后面。
cat innocent.gif malicious.jar > attack.gif
- 上传时:服务器检查头部,发现是合法的 GIF 魔法数字
GIF89a,予以通过。 - 攻击时:攻击者在网页中通过
引用该文件。Java 虚拟机从文件末尾开始解析,将其识别为合法的 JAR 包并执行其中的代码。
5.1.2 JPEG 中的 PHP 代码注入
JPEG 格式包含 EXIF 元数据块。攻击者可以使用工具(如 exiftool)将 PHP 代码写入 EXIF 的 Comment 或 Model 字段。
exiftool -Comment="$_GET['cmd']);?>" image.jpg
这个文件是一个完美的 JPEG 图片,可以被渲染。但如果服务器配置错误,或者存在文件包含漏洞(LFI),攻击者引导服务器执行该文件,PHP解释器会忽略乱码的图像数据,找到并执行 标签内的代码。
5.2 防御纵深:文件清洗与重编码
针对伪装文件,最有效的防御手段不是“检测”,而是“清洗”(Sanitization),也称为内容解除武装与重建(CDR - Content Disarmament and Reconstruction)。
5.2.1 图像重编码(Image Re-encoding)
不要直接保存用户上传的图片。而是使用图像处理库(如 Node.js 的 sharp 或 ImageMagick)对图片进行解码和重新编码。
- 解码:将图片流解码为原始的像素位图(Bitmap)。在这个过程中,任何隐藏在非像素区域的数据(如拼接的 JAR 包或 EXIF 中的 PHP 代码)都会被丢弃。
- 处理:可以进行缩放、裁剪或水印处理。
- 重编码:将纯净的像素数据重新编码为新的 JPEG/PNG 文件。
结果:新生成的文件只包含视觉信息,所有的隐写数据和恶意载荷都被彻底清除。
5.2.2 扩展名白名单与随机化文件名
- 白名单:严格限制允许的扩展名,拒绝所有非白名单文件。
- 文件名随机化:永远不要使用用户提供的文件名。
avatar.php.jpg或../../etc/passwd都是常见的攻击尝试。服务器应生成一个 UUID(如f47ac10b-58cc-4372-a567-0e02b2c3d479.png)作为存储文件名。这不仅解决了安全问题,也避免了文件名冲突和字符集编码问题。
5.2.3 响应头安全:X-Content-Type-Options: nosniff
即使文件通过了所有检查,在分发给用户时,也必须防止浏览器自作聪明。即使服务器发送 Content-Type: text/plain,如果文件内容看起来像 HTML(包含