


函数的详细解释
一.函数的概念与实现
1.概念
我们在数学中经常可以看见函数,所以C语⾔也引⼊函数(function)的概念,有些翻译为:⼦程序,C语言中的函数就是⼀个完成某项特定的任务的一段代码,在C语⾔中我们⼀般会⻅到两类函数:库函数与自定义函数。
1.1.库函数
概念:C语⾔标准中规定了C语⾔的各种语法规则,C语⾔并不提供库函数;C语⾔的国际标准ANSIC规定了⼀ 些常⽤的函数的标准,被称为标准库,那不同的编译器⼚商根据ANSI提供的C语⾔标准就给出了⼀系列 函数的实现。这些函数就被称为库函数。
在前⾯内容中学习的 printf 、 scanf 都是库函数,库函数也是函数,不过这些函数已经是现成 的,我们只要学会就能直接使⽤了。有了库函数,⼀些常⻅的功能就不需要程序员⾃⼰实现了,⼀定 程度提升了效率;同时库函数的质量和执⾏效率上都更有保证。 各种编译器的标准库中提供了⼀系列的库函数,这些库函数根据功能的划分,都在不同的头⽂件中进行了声明。
库函数的学习和查看⼯具很多,⽐如:
C/C++官⽅的链接:https://zh.cppreference.com/w/c/header
cplusplus.com:https://legacy.cplusplus.com/reference/clibrary/
但是我们在使用库函数时,要包含对应的头⽂件,否则会出现⼀些问题。
1.2.自定义函数
光有库函数,有时是无法满足我们的需求的,所以这时就需要自己定义一个函数,满足我们的需求。
语法形式:
ret_type fun_name(形式参数)
{
//代码
...
}解释:
<1>.ret_type 是⽤来表⽰函数计算结果的类型,有时候返回类型可以是 void ,表⽰什么都不返回.
<2>.fu n_name是函数名,建议函数名尽量要根据函数的功能起的有意义。
<3>.括号中放的是形式参数,,函数的参数也可以是 void ,明确表⽰函数没有参数,如果有参数,要交代清楚参数的类型和名字,以及参数个数。
<4>.{}括起来的部分被称为函数体,函数体就是完成计算的过程。
以上是函数的定义。
例如下面的一个相加的函数:
int Add(int a,int b)
{
return a+b;
}2.函数的实现
2.1.函数的调用
int result = Add(10, 20);结合上面的加法函数,我们要明白,result(变量)的类型要与Add函数的类型相匹配,调用Add函数时,参数个数的类型与个数也要与函数一样,那么一个完整的函数就出来了。
#include
int Add(int x,int y)
{
return x+y;
}
int main()
{
int a=10;
int b=20;
int sum=Add(a,b);
printf("sum=%d
",sum);
return 0;
} 2.2.形参和实参
在函数使⽤的过程中,把函数的参数分为,实参和形参。
例如:在上⾯代码中,第2~5⾏是 Add 函数的定义,有了函数后,再第10⾏调⽤Add函数的。 我们把第10⾏调⽤Add函数时,传递给函数的参数a和b,称为实际参数,简称实参。 实际参数就是真实传递给函数的参数。
在上⾯代码中,第2⾏定义函数的时候,在函数名称形参。 为什么叫形式参数呢?实际上,如果只是定义了 Add 后的括号中写的 x 和 y ,称为形式参数,简 Add 函数,⽽不去调⽤的话, Add 函数的参数 x 和 y 只是形式上存在的,不会向内存申请空间,不会真实存在的,所以叫形式参数。形式参数只有在 函数被调⽤的过程中为了存放实参传递过来的值,才向内存申请空间,这个过程就是形参的实例化。
两者的关系:虽然我们提到了实参是传递给形参的,他们之间是有联系的,但是形参和实参各⾃是独⽴的内存空间。 这个现象是可以通过调试来观察的。请看调试结果:

我们可以看出x和y确实得到了a和b的值,但是x和y的地址和a和b的地址是不⼀样的,因此我们可以理解为:形参是实参的⼀份临时拷贝,所以形参的改变,无法影响实参。
例如下面的交换函数:
#include
void swap(int x, int y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 10;
int b = 20;
swap(a, b);
printf("交换后的值a=%d,b=%d
", a, b);
return 0;
} 输出结果:
如果我们想要改变实参的值,就需要用到后面的指针。
二.有关函数的其他知识
1.return语句
特点:
<1>.return后边可以是⼀个数值,也可以是⼀个表达式,如果是表达式则先执⾏表达式,再返回表达式 的结果。
例如:
int add(int a, int b)
{
return a + b; // 先计算 a+b 的值,再将结果返回
}
int get_val()
{
int x = 10;
return (x > 5 ? 100 : 0); // 先执行三目运算表达式,再返回 100
}<2>.return后边也可以什么都没有,直接写 return; 这种写法适合函数返回类型是void的情况。
例如:
void print_n(int n)
{
printf("%d
", n);
}<3>.return返回的值和函数返回类型不⼀致,系统会⾃动将返回的值隐式转换为函数的返回类型。
例如:
int get_pi()
{
return 3.1415; // 3.1415 是 double 类型,但函数返回 int,会自动截断为3
}
double get_num() {
return 10; // 10 是 int,会自动转换为 10.0
}<4>.return语句执⾏后,函数就彻底返回,后边的代码不再执⾏。
例如:
int test_exit()
{
return 1;
printf("这句话永远不会被打印出来
"); //编译器可能会警告
return 2;
}<5>.如果函数中存在if等分⽀的语句,则要保证每种情况下都有return返回,否则会出现编译错误
例如:
int compare(int n)
{
if (n > 0) return 1;
// 报错!如果 n <= 0,函数没有返回值,编译器会发出警告或错误
}注意:千万不要返回局部变量的地址!
例如:
2.数组做函数参数
在使使函数解决问题的时候,可以将数组作为参数传递给函数,在函数内部对数组进⾏操作。
比如:写⼀个函数将⼀个整型数组的内容,全部置为10,再写⼀个函数打印数组的内容。
那么就可以定以两个函数,分别为set_arr()(设置数组内容)h和print_arr()(打印数组内容),
那么此时可能就有人问:形参的改变不是无法影响实参吗?所以set_arr()应改无法影响数组的内容吧?
其实我们要注意的是:传值传参确实不会影响实参,但是如果是传址传参就可以影响实参,这个内容留到指针处讲解
分析:这⾥的set_arr函数要能够对数组内容进⾏设置,就得把数组作为参数传递给函数,同时函数内部在设 置数组每个元素的时候,也得遍历数组,需要知道数组的元素个数。所以我们需要给set_arr传递2个参 数,一个是数组,另外⼀个是数组的元素个数。其实print_arr也是⼀样的,只有拿到了数组和元素个数,才能遍历打印数组的每个元素。
这里我们需要知道数组传参的的几个重点知识:
<1>.函数的实参是数组,形参也是可以写成数组形式的。
<2>.形参如果是⼀维数组,数组大小可以省略不写。
例如:
// 数组大小 10 会被编译器视而不见
void print_arr(int arr[10], int size)
{
...
}
// 最推荐的写法:直接省略大小
void modify_arr(int arr[], int size)
{
...
}<3>.形参如果是⼆维数组,⾏可以省略,但是列不能省略。
例如:
// 数组大小 10 会被编译器视而不见
void print_arr(int arr[10], int size)
{
...
}
// 最推荐的写法:直接省略大小
void modify_arr(int arr[], int size)
{
...
}<4>.数组传参,形参是不会创建新的数组的。
<5>.形参操作的数组和实参的数组是同⼀个数组。
<4>和<5>的例子:
#include
void change(int arr[])
{
printf("形参地址: %p
", (void*)arr); // 打印地址
}
int main() {
int data[3] = {1, 2, 3};
printf("实参地址: %p
", (void*)data);
change(data);
return 0;
} 输出结果:
备工作作好了,接下来就是代码的演示:
#include
// 将数组内容全部设为 10
void set_arr(int arr[], int size)
{
for (int i = 0; i < size; i++)
{
arr[i] = 10;
}
}
// 2. 打印函数:输出数组内容
void print_arr(int arr[], int size)
{
for (int i = 0; i < size; i++)
{
printf("%d ", arr[i]);
}
printf("
");
}
int main()
{
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int n = sizeof(arr) / sizeof(arr[0]);
set_arr(arr, n);
print_array(arr, n);
return 0;
} 3.函数的嵌套使用
嵌套调⽤就是函数之间的互相调用或者函数的自己嵌套,本次以函数的自己嵌套为例。
例如我们要求三个数中的最大值,就可以先将两个数中的最大值作为参数,与另一个数进行比较
代码演示:
#include
// 定义一个比较两个数并返回最大值的函数
int get_max(int x, int y) {
return (x > y) ? x : y;
}
int main() {
int a = 10, b = 25, c = 18;
// 函数嵌套调用:
// get_max(a, b) 的返回值直接作为外层 get_max 的第一个实参
int max_val = get_max(get_max(a, b), c);
printf("三个数中的最大值是: %d
", max_val);
return 0;
} 三.函数的声明和定义
1.单个文件
⼀般我们在使⽤函数的时候,直接将函数写出来就使⽤了。
⽐如:我们要写⼀个函数判断⼀年是否是闰年。
#define _CRT_SECURE_NO_WARNINGS
#include
int is_leap_year(int year)
{
// 逻辑:(能被4整除 且 不能被100整除) 或者 (能被400整除)
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)) {
return 1;
}
return 0;
}
int main() {
int year = 0;
printf("请输入年份: ");
scanf("%d", &year);
int ret = is_leap_year(year);
// 函数调用
if (ret == 1)
{
printf("%d 年是闰年。
", year);
}
else
{
printf("%d 年不是闰年。
", year);
}
return 0;
} 上面中的bool is_leap_year(int year);是函数的定义,而int ret = is_leap_year(year);是函数的调用,这种场景下是函数的定义在函数调⽤之前,没有问题。
那如果我们将函数的定义放在函数的调⽤后边,如下:
#define _CRT_SECURE_NO_WARNINGS
#include
int main() {
int year = 0;
printf("请输入年份: ");
scanf("%d", &year);
int ret = is_leap_year(year);
// 函数调用
if (ret == 1)
{
printf("%d 年是闰年。
", year);
}
else
{
printf("%d 年不是闰年。
", year);
}
return 0;
}
int is_leap_year(int year)
{
// 逻辑:(能被4整除 且 不能被100整除) 或者 (能被400整除)
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)) {
return 1;
}
return 0;
} 就可能会出现下⾯的警告信息:
原因:C语⾔编译器对源代码进⾏编译的时候,从第⼀⾏往下扫描的,当遇到第7⾏的 函数调⽤的时候,并没有发现前⾯有 is_leap_year的定义,就报出了上述的警告。
那么要怎么解决这个问题呢?就是函数调⽤之前先声明⼀下 is_leap_year is_leap_year这个函数,声明函数只要交代清楚函数名,函数的返回类型和函数的参数。 如: int is_leap_year(int year);这就是函数声明,函数声明中参数只保留类型,省略掉名字也是可以 的。
例如:
#define _CRT_SECURE_NO_WARNINGS
#include
int is_leap_year(int year);
int main() {
int year = 0;
printf("请输入年份: ");
scanf("%d", &year);
int ret = is_leap_year(year);
// 函数调用
if (ret == 1)
{
printf("%d 年是闰年。
", year);
}
else
{
printf("%d 年不是闰年。
", year);
}
return 0;
}
int is_leap_year(int year)
{
// 逻辑:(能被4整除 且 不能被100整除) 或者 (能被400整除)
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)) {
return 1;
}
return 0;
} 函数的调用⼀定要满足,先声明后使用; 函数的定义也是⼀种特殊的声明,所以如果函数定义放在调用之前也是可以的。
2.多个文件
⼀般我们写代码时候,代码有时⽐较多,不会将所有的代码都放在⼀个⽂件中;我们往往根据程序的功能,将代码拆分放在多个⽂件中,⼀般情况下,函数的声明、类型的声明放在头⽂件(.h)中,函数的实现是放在源文件(.c)文件中
例如:
add.c文件中
//函数的定义
int Add(int x, int y)
{
return x+y;
}add.h文件中
//函数的声明
int Add(int x, int y);test.c文件中
#include
#include "add.h"
int main()
{
int a = 10;
int b = 20;
//函数调⽤
int c = Add(a, b);
printf("%d
", c);
return 0;
} 四.函数的递归
概念:函数自己调用自己。
思想:把一个大型复杂问题层层转化为一个与原问题相似,但规模较小的子问题来求解;直到子问题不能再被拆分,递归就结束了。所以递归的思考方式就是把大事化小的过程。
限制条件:递归存在限制条件,当满⾜这个限制条件时,递归将不再继续。
例如::计算n的阶乘,n的阶乘就是1~n的数字累积相乘。
我们已知道n的阶乘的公式: n ! = n∗(n−1)!,那么当 n==0 的时候,n的阶乘是1,其余n的阶乘是可以通过公式计算,那我们就可以写出函数Fact求n的阶乘,假设Fact(n)就是求n的阶乘,那么Fact(n-1)就是求n-1的阶乘,n的阶乘的递归公式如下:
代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include
int Fact(int n)
{
if(n==0)
return 1;
else
return n*Fact(n-1);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fact(n);
printf("%d
", ret);
return 0;
} 输出结果:
画图推演:
然而递归过深的话,也会出现有递归过深,导致计算所花费的时间过长。
例如::求第n个斐波那契数
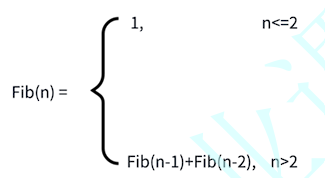
代码:
#define _CRT_SECURE_NO_WARNINGS
#include
int Fib(int n)
{
if(n<=2)
return 1;
else
return Fib(n-1)+Fib(n-2);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("%d
", ret);
return 0;
} 当我们n输⼊为50的时候,需要很⻓时间才能算出结果
画图推演:
从中可以看出递归程序会不断的展开,在展开的过程中,我们很容易就能发现,在递归的过程中会有重复计算,⽽且递归层次越深,冗余计算就会越多,所以这个用递归的思想就不太合适。





