一文吃透 Redis 压缩列表、listpack 及哈希表扩容与并发查询
目录
压缩列表是怎么实现的?
介绍一下 Redis 中的 listpack哈希表是怎么扩容的?
哈希表扩容的时候,有读请求怎么查?
压缩列表是怎么实现的?
压缩列表图:

链表的表头有三个字段
zlbytes:用于统计整个压缩列表有多少字节
zltail:用于统计末尾节点距离起始节点相差多少字节的距离
zllen:用于统计整个列表的节点数量
末尾一个字段:
zlend:用于标记列表的结束点,固定值是0xFF十进是255
如果需要查询列表的最后一个节点,只需要依赖头部字段zltail就可以查到了只需要查找一次复杂度是O(1),而其他节点就需要依次查找,时间复杂度是O(n),所以压缩列表不适合存储元素过多的场景
每一个节点有三个属性
prevlen:存放前一个节点占用的内存字节大小,列表倒序就需要依赖prevlen
encoding:存放当前数据的类型,整数型或者字符串
data:存当前数据
当压缩列表插入数据时,压缩列表会根据当前元素的类型和大小来使用不同的空间的prevlen和encoding来存储数据,这一根据元素大小分配空间的方案,提高了内存的使用率
压缩列表的缺点:
一旦遇到连锁更新时,就有可能导致压缩列表分配的内存空间重新分配,而多次的重新分配会影响压缩列表的访问性能
若节点过多或节点过大也有可能引发连锁更新,所以压缩列表适合存储节点比较少的场景
redis为了解决这个缺点redis3.2引入了quicklist和redis5.2引入了listpack,保存了节省空间的优点,同时解决压缩列表连锁更新的问题
介绍一下 Redis 中的 listpack
listpack核心目的就是解决了ziplist(压缩列表)的连锁更新问题
listpack的结构如下:

头部两个属性:记录了总字节数和元素数量
结尾还有结尾标识
每一个元素有三个属性:
encoding:定义该元素的编码类型,会对整数或字符串进行不同的编码
data:数据
len:记录encoding和data的长度
listpack每一个节点会根据内容的大小来进行不同的编码,主要依赖于encoding
没有了prevlen之后依旧可以倒叙,因为如果更改字符串不会导致其他节点的内容变化直接解决了连锁更新的问题
倒序遍历的核心逻辑
- 第一步:通过表头的「总字节数」定位到整个 listpack 的末尾。
- 第二步:减去结尾标识(1 字节),得到最后一个节点的末尾地址。
- 第三步:读取该节点的
len字段,用末尾地址减去len得到上一个节点的末尾地址。- 第四步:重复第三步,直到遍历到表头,完成倒序。
哈希表是怎么扩容的?
哈希扩容需要两个哈希表
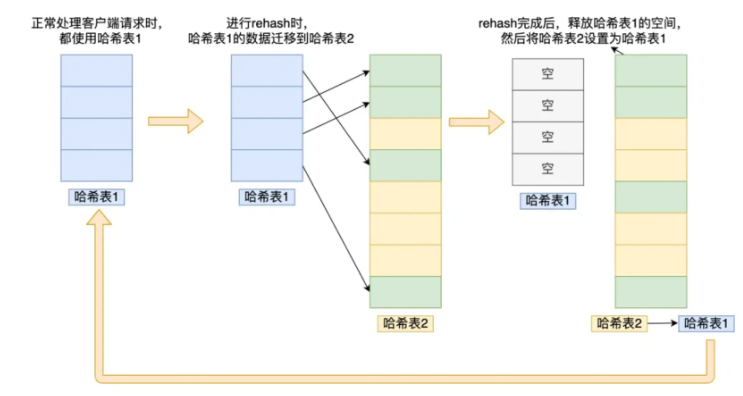
有两种方式:
一次性映射所有值:会导致redis阻塞卡死,所以基本不用
Redis 的核心是单线程处理所有客户端的读写请求(底层操作是单线程的),这是 Redis 高性能的原因,也是不能一次性扩容的根本原因:
- 一次性拷贝的问题:如果哈希表中存储了百万 / 千万级的 key-value,一次性遍历 ht [0] 所有数据、重新计算哈希、迁移到 ht [1],这个过程会消耗几十毫秒甚至几秒的时间;
- 单线程的致命影响:在这几十毫秒 / 几秒内,Redis 的单线程会被完全阻塞,无法处理任何客户端的读、写、查询请求 —— 客户端会看到请求超时、服务无响应,这在生产环境中是不可接受的(比如电商场景的秒杀、缓存查询,一秒的阻塞都会导致大量请求失败);
- 结论:一次性扩容的技术上可以实现,但业务上完全不可用,违背了 Redis 高性能、高可用的设计目标
渐进式映射:分区段的把哈希表1映射到哈希表2,在映射的过程中,如果有读的操作,若在哈希表1没有,就去查询哈希表2。若有写的操作只在哈希表2进行,保证哈希表1的数量只减少。最终把哈希表1的内容全部映射到哈希表2之后把哈希表1的空间释放,然后把哈希表2设置为哈希表1
哈希表的渐进式扩容并非原位置顺序拷贝数据,而是对每个 key 通过哈希取模,把映射key到新表的新位置(即 rehash),这是扩容大幅度减少哈希冲突的核心
哈希取模是哈希表将「哈希函数算出的大数值」转换为「数组合法下标」的核心操作,通过哈希值 % 数组容量实现,保证任意 key 都能映射到哈希表的指定位置;
哈希表扩容的时候,有读请求怎么查?
查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。
本文地址:https://www.yitenyun.com/6010.html