


强化学习——reinforce算法
一、基本概念
REINFORCE 是一种基于策略的强化学习方法,属于无模型的强化学习方法之一。它通过直接优化策略来最大化累积回报,而不是估算值函数。REINFORCE 方法属于蒙特卡洛策略梯度(Monte Carlo Policy Gradient)方法,采用了无偏估计来更新策略参数,通常使用梯度上升法来优化策略。
二、基本思想
REINFORCE 的核心思想是通过采样环境,计算每个时间步的回报,并利用这些回报来更新策略。具体而言,REINFORCE 不像 Q-learning 等基于值的强化学习方法那样,通过估算状态值函数或动作值函数来间接获取策略,而是直接对策略进行优化,通过对策略梯度进行估算来指导策略更新。
REINFORCE 方法的主要目标是通过逐步调整策略,使得最终的策略在长期运行中能够获得最大的回报。
三、公式推导
1.回报估计
设 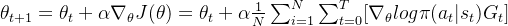 为从时间步 开始到终止时刻的累积回报:
为从时间步 开始到终止时刻的累积回报:
是终止时间步,是时刻时的奖励
2.策略梯度公式
reinforce算法通过计算策略的梯度来更新策略参数,其中设为策略的参数,表示在状态下采取动作的概率。策略的目标是最大化预期回报,即:
由于是与时间步 相关的随机变量,REINFORCE 方法通过采样来估算 的梯度。策略梯度可以通过以下公式来计算:
当一次循环使用多条轨迹时,于直接计算期望通常比较复杂,REINFORCE 通过采样得到无偏估计来估算该期望:
3.梯度更新
其中为学习率
四、算法流程
1.初始化
初始化策略参数(通常随机初始化),设置学习率与折扣因子
2.与环境交互
根据当前策略与环境进行交互,生成N个轨迹。轨迹由一系列状态、动作、奖励组成:
3.计算回报
根据采样的轨迹,计算每一个时间步的回报
4.估算梯度
根据回报与策略梯度公式,计算梯度
5.更新策略参数
使用梯度上升法更新策略参数:
6.重复
重复步骤 2 到步骤 5,直到收敛或满足停止条件。
五、N值的选择
1.小N值(单条轨迹或少量轨迹)
-
优点:
-
计算较快,每次更新的计算量较小。
-
适合于需要快速收敛或者在线更新的情况。
-
-
缺点:
-
方差大:单条轨迹的回报可能具有很大的波动,导致梯度估计的方差较高。这会导致训练过程不稳定,收敛速度较慢。
-
可能无法充分探索状态空间,导致智能体的学习过程受限
-
2. 大N值(大量轨迹)
-
优点:
-
方差小:使用多条轨迹的回报对梯度进行平均,能够减少单条轨迹的随机波动,从而获得更稳定的梯度估计。
-
改善策略:通过更准确的梯度估计,算法可能会更有效地优化策略,收敛速度通常更快。
-
-
缺点:
-
计算开销大:每次迭代需要收集大量的轨迹数据,这会显著增加计算资源的需求。
-
收集大量轨迹的时间成本较高,特别是在环境复杂或者训练周期长的情况下。
-
对于大多数强化学习任务,使用几十条轨迹(例如N=10到N=100)通常是比较合理的选择。这能够在计算负担和训练效果之间取得良好的平衡。
本文地址:https://www.yitenyun.com/6108.html





