


深度学习笔记(概念向)
一.什么是深度学习
本质是找一个极其复杂的F(X)=Y的函数映射,主要过程是定义一个函数以及损失函数,根据损失函数对模型进行优化
1.衡量差距:用一个损失函数LOSS衡量当前f的预测值与真实值的差距
2.计算梯度:用微积分中的链式法则计算每个参数对误差的影响大小也就是梯度
3.更新映射:首先将loss计算的误差从最后一层向前传递到每一个神经元(backward)再更新参数(优化器 例如SGD adam)
二.常见的神经网络输入
1.向量 2.矩阵 3.序列
由于计算机底层只认识数字,因此所有的输入都必须转化为张量也就是多维数组。
三.激活函数
为模型引入非线性因素
常见激活函数:
1.relu:f(x) = max(0, x) 最常用 计算很简单
2.sigmoid:S(X)=1/(1+e^-x)将输出压缩到(0,1)容易导致梯度消失
四.深度学习中的过拟合和欠拟合问题
欠拟合(underfitting):模型太简单或者训练得不够。表现为:训练集准确率低,测试集准确率也低。
过拟合(overfitting):模型太复杂,过度拟合了训练数据里的噪声和随机波动,导致丧失了泛化能力。表现为:训练集准确率极高,但测试集准确率很低。

五.优化策略
1.批量梯度下降 Batch Gradient Descent
每次更新参数前,计算整个训练集所有数据的平均 Loss
优点:梯度方向稳定,能准确指向全局或局部最优解。
缺点:算力开销大,一旦掉进局部的“坑”(局部最小值),就很难跳出来
2.随机梯度下降 Stochastic Gradient Descent, SGD
每看一个数据,就立刻计算一次 Loss 并更新一次参数。
优点:快且省内存.随机性带来的“活力”: 因为只看一个点,梯度的方向非常“抖动”。这种抖动反而可能帮模型跳出局部最优解。
缺点:方向太乱,很难收敛到最低点且没办法利用GPU的并行计算能力
3.小批量梯度下降 Mini-batch Gradient Descent
数据分成一个个小包(Batch,比如 32、64 或 128 个数据),每算完一个 Batch 更新一次。是目前最通用的做法
优点:充分利用 GPU 的矩阵运算能力,比一个一个算快得多。适度的随机性能帮助模型跨过一些小的局部最优解。
六.改进模型性能方法
1.L2正则化:loss=LOSS+W*W 在LOSS中加上所有权重的平方和,可以限制权重变得很大
作用:让模型变得平滑不会对输入数据中的微小噪声产生剧烈反应
2.selectkbest:Scikit-learn中的一个筛选器:对每一个特征用相关系数算出一个得分筛选出得分最高的K个特征
作用:降噪扔掉那些跟目标没关系的“废话”特征。 防过拟合。提高计算速度
3.主成分分析PCA:经典的数据降维算法
PCA 就像是“压缩”——它通过数学变换,将原本杂乱的高维特征组合成全新的、互不相关的几个“核心特征”。
4.早停机制:在模型开始走偏之前提前结束训练
训练过程通常有三个阶段:
A.欠拟合阶段:此时训练集LOSS和验证集LOSS都在下降
B.最佳点:验证集LOSS达到最低点,此时模型学到了数据的核心规律且具有良好的泛化能力
C.过拟合:练集 Loss 继续下降,但验证集 Loss 开始回升。
早停机制的目标就是在进入C阶段的瞬间停止训练。当连续X个epoch验证集的loss都没有下降 ,就提前停止训练
七.卷积神经网络 Convolutional Neural Networks, CNN
主要由:1.卷积层 2.激活层 3.池化层组成
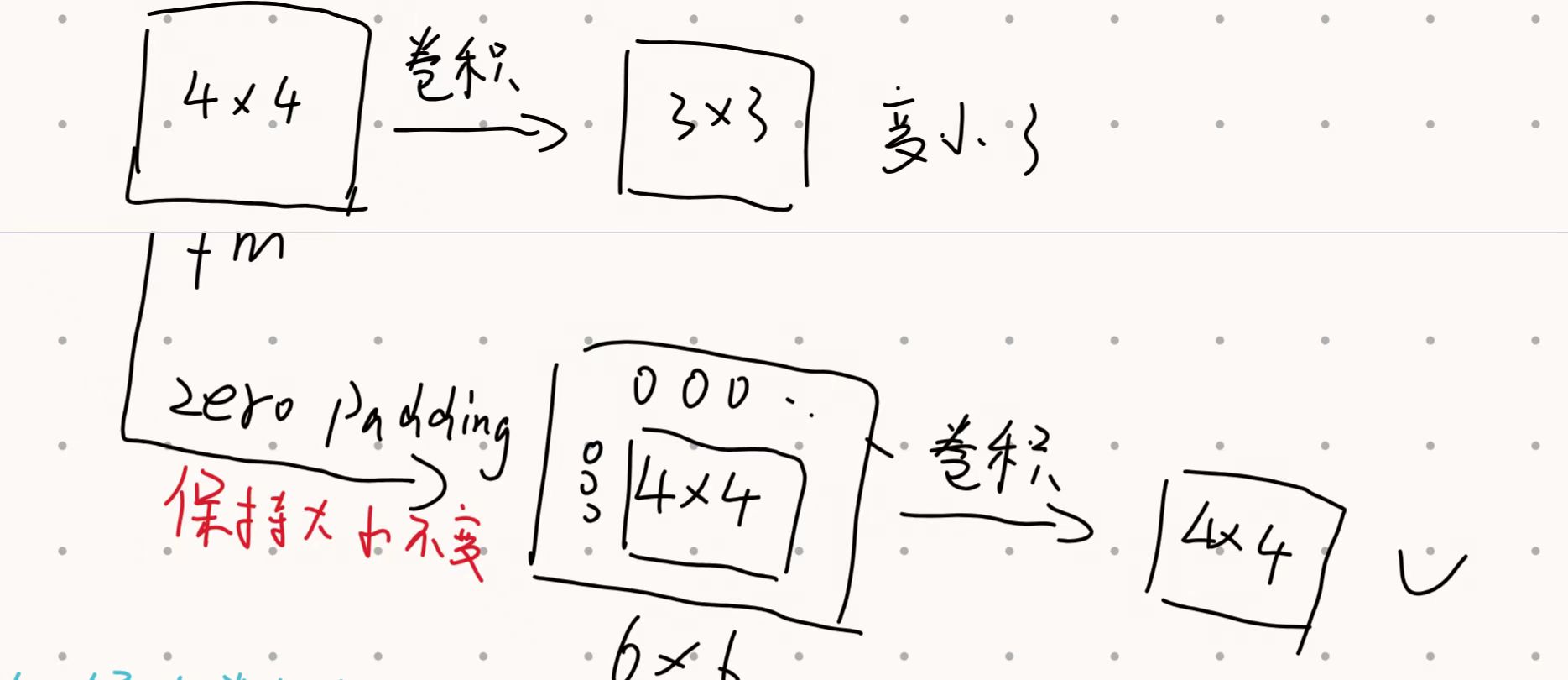
subsampling降采样:将输入映射到一个尺寸更小、但保留了关键特征的输出上。
方法:1.池化(最大池化)
2.扩大步长
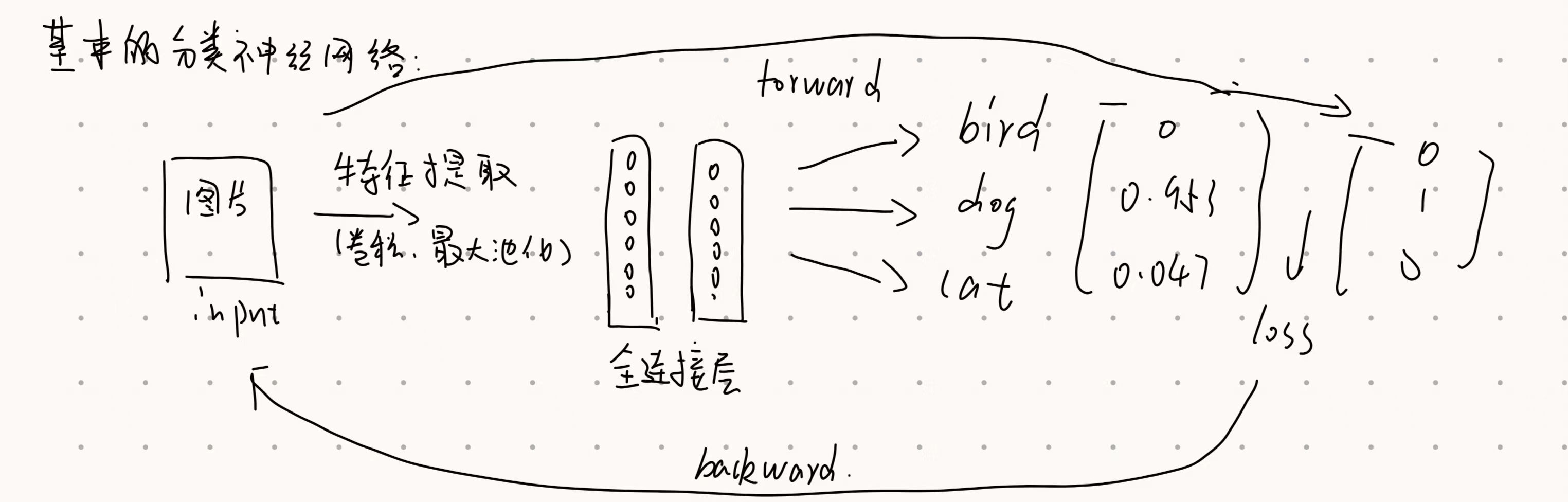
softmax():一种关键的激活函数通常应用在分类模型的最后一层
作用:将杂乱的原始输出(Logits)转化为人类可理解的概率分布。
分类任务的loss:交叉熵损失 crossentropy loss
分类模型的运作逻辑:
经典网络:
1.ALEXNET:五层卷积层和三层全连接层
输入层:接收3×224×224的彩色图像
卷积层:第一层 (Conv1)使用了巨大的 11×11 卷积核,步长 (Stride) 为 4
使用PADDING技术控制尺寸并用最大池化(max pooling)控制计算量
全连接层:最后三层将提取的特征映射到 1000 个类别上。
输出层:使用 Softmax 函数输出 1000 类的概率分布
四大创新:1.率先使用了 ReLU,极大地加快了训练速度,并缓解了深层网络中的梯度消失问题。2.使用 Dropout 正则化,为了解决过拟合问题,AlexNet 在全连接层中引入了 Dropout(随机让 50% 的神经元罢工)。这强迫模型学习更健壮的特征,正如你之前提到的,这是改进模型性能的重要方法。3.数据增广,认为扩充了数据集
2.resnet残差网络
残差连接:把输入加到输出上y=F(X)+X
作用:保护梯度,在反向传播时,梯度可以通过这条“支路”直接流向更浅的层,不会因为中间的复杂卷积而消失。如果某一层是多余的,模型只需要把 F(X) 设为 0(这很容易做到),那么这一层就变成了恒等变换(Identity Mapping),至少不会让性能变差。
八.优化器的比较
1.sgd
学习率固定,容易陷入局部最优解
2.adam
不怎么需要调参就可以跑出较好的效果,支持参数自适应,每个参数都有自己专有的学习率
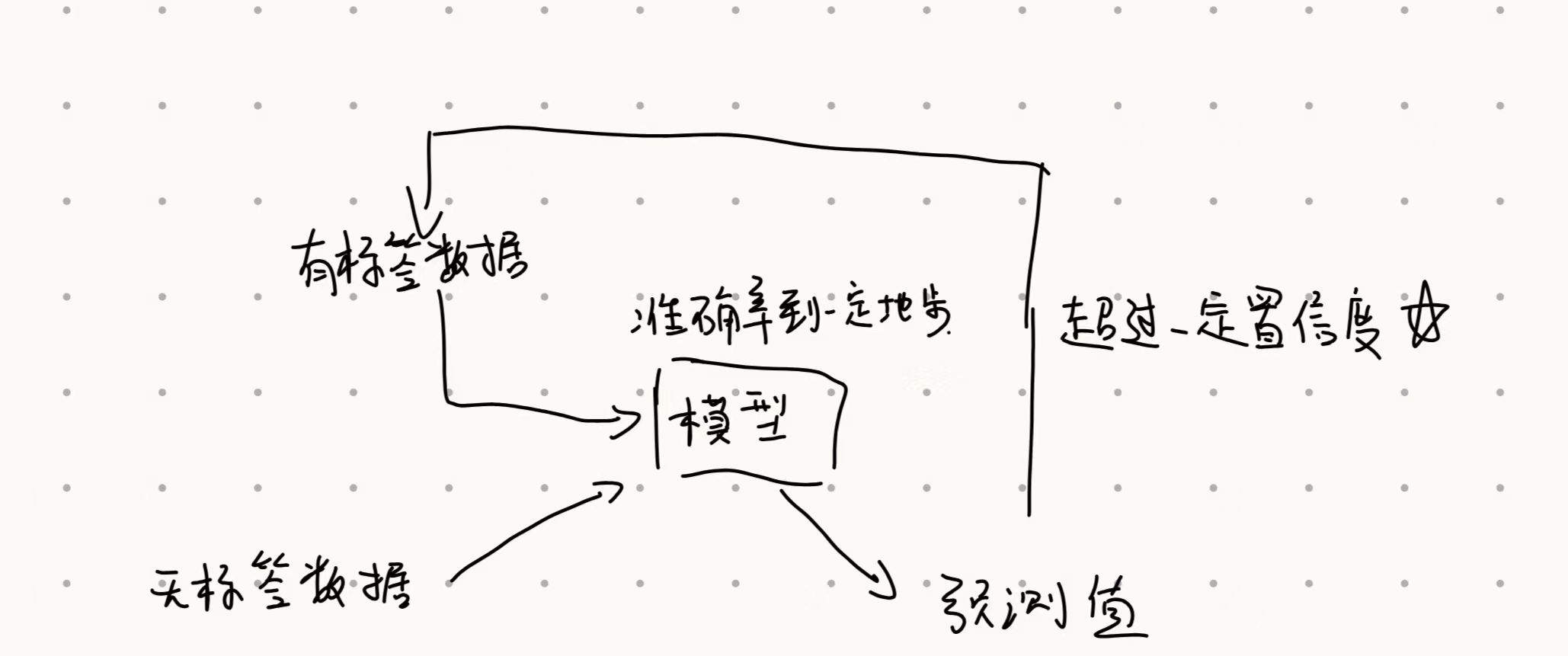
九.图像分类半监督
十.无监督学习
所有数据都只有特征X没有标签Y
1.生成对抗网络GAN
由两个互相博弈的模型生成器和判别器组成
生成器接收一个随机噪声,试图生成足以乱真的数据(如人脸图像)。它的目标是骗过判别器。判别器接收真实数据和生成器造出的假数据,并判断谁真谁假。它的目标是识破生成器的伪装。
原理:在对抗中进化 ,给判别器看真实照片和生成器造的劣质假图。判别器学会识别其中的差异。生成器根据判别器的反馈进行调整。如果判别器识破了它,它就会改进映射函数,让输出更接近真实分布。
2.生成式自监督
原始数据 X 的一部分作为输入,另一部分作为目标 Y。
好处:互联网上有无穷无尽的文本和图片,不需要昂贵的人工标注。这种方式训练出来的模型(预训练模型)对世界的理解非常深刻。只需要用极少量的标注数据进行“微调”,它就能在分类、检测等任务上达到极高精度。为了“重建”数据,模型必须理解 X的内在结构,这比简单的分类更能抓住数据的本质。
十一.对序列问题的处理
1.RNN循环神经网络:读当下的内容同时处理上一刻的印象,引入隐藏状态H,Ht=Ht-1+Xt。存在长程依赖丢失问题,序列一长,对前面的记忆就模糊了。
2.LSTM长短期记忆网络:引入了复杂的门控机制:遗忘门决定哪些信息该丢掉,输入门决定哪些新信息该留下来,输出门决定此时此刻该输出什么
3.TRANSFOEMER:
自注意力机制:一次性看全句计算每个词与其他词的相关性,每个字的特征提取可以同时进行。由于是并行处理,模型并不知道字的顺序,因此需要加上位置编码







