


海量数据存储最佳实践:从技术选型到架构设计全解析
一、存储系统技术选型:为业务选择合适的数据存储方案
1.1 技术选型的关键考虑因素
在构建系统时,存储系统的选择直接影响系统性能和稳定性。所有业务开发可归结为两件事:存储和计算。存储系统决定了系统的性能上限,而计算方式决定了能否达到这个上限。
1.1.1 系统类型:OLTP vs OLAP
首先需要明确系统类型:
-
OLTP(在线事务处理系统):实时处理业务交易,如电商交易系统
-
OLAP(离线分析处理系统):数据分析、报表系统
实际场景处理策略:
-
中小规模系统:以主要业务类型为依据
-
创业公司电商系统 → 按OLTP处理
-
-
大规模系统:拆分在线业务和分析系统
-
分别选择合适的存储
-
架构成本较高,适合大型企业
-
1.1.2 数据量评估维度
估算系统数据量需考虑:
-
存量数据:当前已有数据量
-
增量数据:未来新增数据量
-
预估周期:未来2-3年足够,无需过度预留
数据量级分类:
-
GB以下/千万条以内:几乎所有存储产品性能良好
-
1GB-10GB/亿条以内:单机存储系统处理上限
-
超过10GB/亿条以上:必须使用分布式存储,数据分片
1.1.3 总体拥有成本(TCO)评估
存储系统成本不仅包括软件费用,还包括:
-
团队熟悉度成本:不熟悉的产品可能带来系统风险
-
学习成本:产品是否简单易用
-
运维成本:系统上线后的维护难度
1.2 在线业务系统存储选择
在线业务系统对存储产品的要求:
-
良好的写性能:支持频繁的增删改操作
-
毫秒级响应:直接服务前端,需要快速响应
-
高并发支持:满足大量用户同时访问
-
强大的查询能力:适应频繁变化的业务需求
推荐方案:MySQL + Redis经典组合
| 存储产品 | 特点 | 适用场景 |
|---|---|---|
| MySQL | 关系型数据库,功能全面 | 主要业务数据存储 |
| Redis | 内存KV存储,性能优异 | 缓存、会话存储 |
| MongoDB | 文档数据库 | 特定业务场景 |
为什么选择MySQL:
-
关系型数据库中最接近完美解决方案
-
功能全面,查询能力强
-
成本相对较低
-
社区活跃,生态完善
Redis的角色:
-
配合MySQL作为缓存层
-
提供有限的查询功能
-
不保证数据可靠性(需配合持久化策略)
1.3 海量数据存储特殊场景:前端埋点数据
1.3.1 海量数据类型
-
前端埋点数据(点击流):用户行为记录
-
监控数据:系统监控指标
-
日志数据:应用日志
数据量特点:
-
比业务数据(订单、商品)多2-3个数量级
-
头部企业日增量可能超过TB级
-
累积数据可能达到PB级
1.3.2 存储方案演进
早期方案:先计算再存储
-
接收数据时进行过滤和聚合
-
压缩数据后再存储
-
优点:降低存储压力,节省空间
-
缺点:灵活性差,无法重新计算
现代方案:先存储再计算
-
直接保存原始数据
-
实时或批量计算
-
优点:
-
无需二次分发
-
可随时回滚重新计算
-
支持历史数据分析
-
-
缺点:成本较高
1.3.3 技术选型推荐
短期存储(实时计算):
-
Kafka/RocketMQ:高吞吐量,无限消息堆积
-
与大数据生态兼容性好
长期存储(历史数据):
-
HDFS:分布式文件系统
-
适合数月到数年的数据保存
时序数据存储:
-
InfluxDB:专门处理时间序列数据
-
良好的读写性能和聚合能力
二、海量数据查询优化策略
2.1 分析类系统存储选择
分析类系统(报表、统计系统)对存储的需求:
-
海量数据存储能力:数据量通常比在线业务高几个数量级
-
快速聚合分析:在GB/TB/PB级别数据上实现快速分析
-
写入性能要求不高:通常异步写入
-
并发要求低:不直接支撑前端业务
2.1.1 不同数据量级的存储选择
| 数据量级 | 推荐存储 | 说明 |
|---|---|---|
| GB以下 | MySQL | 查询能力强,可与在线系统共用 |
| GB级别 | 列式数据库(HBase、Cassandra、ClickHouse) | 秒级查询性能,查询方式受限 |
| TB以上 | HDFS + 计算引擎(Spark、Hive) | 无法实时查询,需预聚合 |
2.1.2 Elasticsearch的特殊优势
ES在分析系统中的价值:
-
支持结构化数据存储和查询
-
分布式并行查询性能好
-
查询灵活性优于列式数据库
-
缺点:需要大内存服务器,硬件成本高
2.2 多层缓存存储体系构建
2.2.1 核心思想:没有银弹解决方案
-
没有哪种存储在所有场景下都有明显优势
-
不同存储系统只在擅长领域表现优异
2.2.2 组合存储架构
电商秒杀场景示例:
text
传统存储(MySQL) + 缓存(Redis) + 本地存储引擎(RocksDB)
优势:
-
利用不同存储的优势
-
构建多层次数据访问路径
-
提升整体系统性能
三、RocksDB深度解析:新一代存储引擎
3.1 RocksDB概述与应用场景
3.1.1 基本介绍
-
Facebook基于Google LevelDB开发的高性能KV存储引擎
-
持久化存储,保证数据可靠性
-
被众多新生代数据库选为底层存储引擎
3.1.2 应用案例
-
分布式数据库:
-
CockroachDB、YugabyteDB、TiDB
-
-
MySQL存储引擎:
-
MyRocks(替代InnoDB)
-
MariaDB已接纳作为存储引擎
-
-
实时计算引擎:
-
Flink的State存储
-
-
其他数据库:
-
MongoDB、Cassandra、HBase都在开发基于RocksDB的引擎
-
3.1.3 性能表现
根据官方性能测试:
-
随机读:最高19W/S,平均13W/S
-
覆盖操作:9W/S
-
多读单写:10W/S左右
InfluxDB测试对比:
-
批量写入5000万数据:RocksDB仅需1分26.9秒
-
综合表现:在多个对照引擎中表现最佳
3.2 RocksDB vs Redis:本质区别与适用场景
3.2.1 核心差异对比
| 维度 | Redis | RocksDB |
|---|---|---|
| 存储介质 | 内存 | 磁盘 + 内存 |
| 数据可靠性 | 不保证持久化 | 保证持久化 |
| 随机读写性能 | 约50万次/秒 | 约20万次/秒 |
| 本质定位 | 内存数据库/缓存 | 持久化KV存储引擎 |
3.2.2 性能对比分析
-
Redis优势:纯内存操作,性能极高
-
RocksDB优势:磁盘操作但接近内存性能
-
核心价值:RocksDB在保证数据持久化的前提下,达到接近内存数据库的性能
3.3 LSM-Tree:兼顾读写性能的核心数据结构
3.3.1 LSM-Tree基本概念
-
全称:The Log-Structured Merge-Tree
-
设计目标:为KV存储系统设计,牺牲部分读性能换取更高写性能
-
适用场景:写多读少的场景
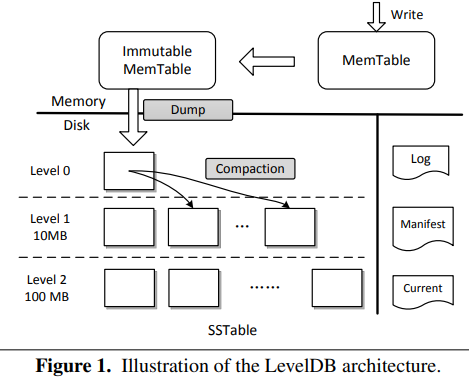
3.3.2 LSM-Tree写入过程详解
步骤1:写入WAL日志
-
操作命令写入磁盘WAL日志
-
顺序写磁盘,性能好
-
目的:故障恢复,保证数据可靠性
步骤2:写入MemTable
-
数据写入内存中的MemTable
-
MemTable采用跳表(SkipList)结构
-
内存操作,速度快
步骤3:MemTable转换
-
MemTable有大小限制(通常32MB)
-
写满后转为Immutable MemTable(只读)
-
创建新的MemTable继续写入
步骤4:写入SSTable
-
后台线程将Immutable MemTable写入磁盘
-
生成有序的SSTable文件
-
顺序写操作,性能高
3.3.3 SSTable分层合并机制
分层结构设计:
-
SSTable分为多层
-
下一层容量通常是上一层的10倍
-
每层写满时触发合并操作
合并过程:
-
数据合并到下一层
-
排序整理过程
-
删除本层已合并的文件
-
保证每层内文件有序
优势:
-
热数据自然上浮到上层
-
减少磁盘查找次数
-
提升整体查询性能
3.3.4 LSM-Tree查询优化
分层查找策略:
-
先在内存中查找(MemTable、Immutable MemTable)
-
按层在磁盘SSTable文件中查找
-
找到即返回,避免不必要的查找
工程优化措施:
-
布隆过滤器:避免无谓的磁盘查找
-
数据分族:逻辑分组优化
-
内存缓存:缓存SSTable文件的Key
-
多MemTable优化:提前进行数据合并
-
块缓存和表缓存:加速数据访问
3.4 RocksDB在实际项目中的应用建议
3.4.1 适用场景判断
适合使用RocksDB的场景:
-
写密集型应用
-
需要持久化保证的数据存储
-
对读取延迟有一定容忍度
-
作为其他存储系统的补充
不适合的场景:
-
纯读取密集型应用
-
需要极低读取延迟的场景
-
数据量很小的情况
3.4.2 配置优化建议
-
内存配置:合理设置MemTable大小
-
合并策略:根据访问模式调整合并算法
-
缓存设置:配置适当的块缓存和表缓存
-
压缩选项:权衡存储空间和CPU消耗
四、总结与最佳实践
4.1 存储系统选型方法论
-
明确业务类型:区分OLTP和OLAP需求
-
评估数据量级:根据数据规模选择单机或分布式存储
-
考虑总体成本:包括学习、开发和运维成本
-
经典组合优先:MySQL + Redis满足大部分在线业务需求
4.2 海量数据处理策略
-
分层存储架构:原始数据 → 聚合数据 → 缓存数据
-
实时与批量结合:根据业务需求选择合适的处理方式
-
多存储引擎组合:发挥不同存储系统的优势
4.3 新技术应用原则
-
评估成熟度:生产环境优先选择成熟稳定的技术
-
渐进式引入:先在非核心业务试点
-
监控与调优:持续监控性能,根据实际使用调优
-
团队能力建设:确保团队具备相应的运维能力
核心观点重申:存储系统没有银弹,最有效的策略是根据具体业务场景,合理组合多种存储技术,构建多层次、多维度的数据存储和处理体系。








