【瑞萨AI挑战赛】从 0 到 1 跑通 RA8P1 NPU:YOLO-Fastest 训练、转换与端侧部署全链路实战
RA8P1 模型转换与部署教程(手势识别)
适用范围:RA8P1 (Ethos‑U55)
工具链:e2 studio 集成 RUHMI
说明:本工程是基于官方示例人脸识别工程基础上进行教学,本教程仅新增 手势识别 模型的获取、转换与部署。
0. 基础知识与技术栈简介
为了更好地理解本教程,建议先了解以下核心技术概念,这将有助于你理解为什么需要进行“模型转换”和“量化”操作。
核心硬件:RA8P1 与 Ethos-U55
- Renesas RA8P1: 业界首款基于 Arm Cortex-M85 内核的微控制器。M85 搭载了 Helium™ 矢量处理单元,DSP/ML 性能及其强悍。
- Arm Ethos-U55: RA8P1 内部集成的微型神经网络处理器 (microNPU)。它的作用是专门处理繁重的卷积和矩阵运算。
- 优势:相比仅用 CPU,使用 NPU 推理速度通常提升数倍甚至数十倍,且功耗极大降低。
- 工作原理:NPU 并不运行普通 C 代码,而是执行专门的“命令流”。我们在转换步骤生成的
sub_xxxx_command_stream.c就是 NPU 的指令集。
核心算法:YOLO-Fastest
- YOLO-Fastest: YOLO (You Only Look Once) 系列中最轻量级的版本之一。
- 为什么选它:标准 YOLOv5/v8 对于 MCU 来说过于庞大。YOLO-Fastest 优化了网络结构(如使用深度可分离卷积),在保持检测速度(FPS)的同时,模型体积通常能控制在 1MB 以内,非常适合部署在 MCU 的片内 Flash 中。
核心流程:RUHMI 与 量化 (Quantization)
- RUHMI / AI Navigator: Renesas 的 AI 部署工具链。它的核心任务是将通用的 AI 模型(如 .pt/.onnx)“翻译”成嵌入式工程可用的 C 代码。
- INT8 量化 (关键):Ethos-U55 是一个定点加速器,它只能通过整数(INT8)进行计算,不支持浮点数(Float32)。
- 转换:工具会将模型中的权重(如 0.1234)映射为整数(如 12)。
- 校准 (Calibration):为了让整数运算的结果尽可能接近原始浮点结果,我们需要提供“校准集”图片,让工具统计数据的分布范围(动态范围)。如果校准没做好(如 Mean/Std 设置错误),模型在板子上跑出来的结果就会完全不可用。
1. 环境搭建与 RUHMI 安装
RUHMI (Renesas AI) 有两种安装方式:一种是图形化界面,一种是命令行。本教程讲解通过图形化界面进行安装与配置。
1.1 安装 e2 studio
首先下载并安装 Pyron e2 studio。安装完成后打开模型转换工具(RUHMI Dashboard)。

(图示路径)

1.2 安装配置 Python 3.10 (关键步骤)
如果在选择路径后提示环境缺失(如提示找不到 Python),请按照以下步骤安装。
第一步:下载 Python 3.10
e² studio 通过 Windows 的 py 启动器检测版本,必须安装官方纯净版。
下载地址 或前往 Python 官网下载 Python 3.10.x(建议 3.10.11 或更新版本)。
第二步:安装设置(非常重要)
运行安装包时,在第一个界面:
- 不要勾选
Add Python 3.10 to PATH—— 保护现有环境,避免冲突。 - 务必勾选
Install launcher for all users (Recommended)—— 让 e² studio 能通过py -3.10命令找到它。 - 点击
Install Now完成安装。
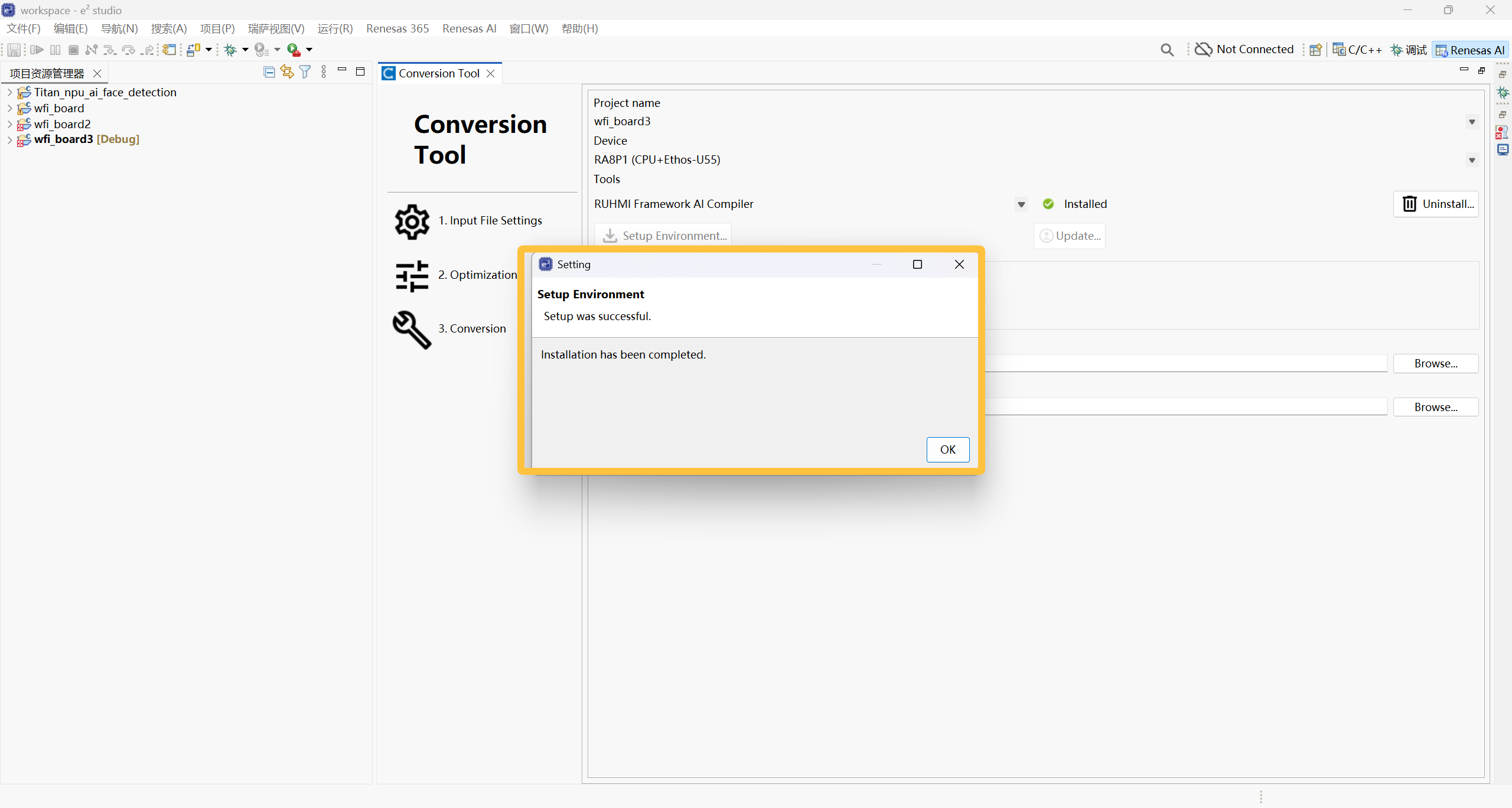
安装完成后,重启 e2 studio,按照之前的步骤再次点击 Setup Environment。
当出现如下图示时,代表环境配置成功:
2. 模型训练:手势检测 (YOLO-Fastest)
本节介绍从数据集准备到训练出 .pt 文件的全流程。
- 任务:2 类目标检测:
ok、palm(张开手掌) - 模型:YOLO-Fastest (2路输出 head)
- 输入:
192x192,RGB 3通道 - 预处理:
x/255(0…1),无 mean/std 减法
2.1 准备数据集 (HaGRID 子集)
我们使用 HaGRID 的 YOLO 格式数据,仅保留两类(0=ok, 1=palm)。
下载与解压
在 Windows PowerShell 执行以下命令:
mkdir D:gesture_ai
cd D:gesture_ai
# 下载示例数据集 (约10GB)
curl.exe -L -o yolo_format.zip "https://huggingface.co/datasets/testdummyvt/hagRIDv2_512px_10GB/resolve/main/yolo_format.zip?download=true"
# 解压
mkdir hagrid_yolo_sample
tar -xf .yolo_format.zip -C .hagrid_yolo_sample
目录结构示例:
D:gesture_aihagrid_ok_palm_1images rain|val|testD:gesture_aihagrid_ok_palm_1labels rain|val|testD:gesture_aihagrid_ok_palm_1data_ok_palm.yaml

2.2 训练环境配置
1. 拉取代码库
cd D:gesture_ai
git clone https://github.com/Nota-NetsPresso/ModelZoo-YOLOFastest-for-ARM-U55-M85.git
cd .ModelZoo-YOLOFastest-for-ARM-U55-M85
pip install -r requirements.txt
2. 解决版本兼容性问题
- 该仓库建议
torch >= 1.11, < 2.0。 - 如果使用 torch 1.x,需降级 NumPy 防止报错:
pip install "numpy<2" - RTX 4060 显卡建议安装 CUDA 11.7 对应的 torch 版本:
pip uninstall -y torch torchvision pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --index-url https://download.pytorch.org/whl/cu117
2.3 执行训练
D:gesture_ai.venvScriptspython.exe train.py
--data D:gesture_aihagrid_ok_palm_1data_ok_palm.yaml
--cfg .modelsyolo-fastest.yaml
--weights ""
--imgsz 192
--batch-size 64
--epochs 200
--device 0
--workers 4
--project D:gesture_ai
uns
--name ok_palm_192
--exist-ok
--noplots

训练完成后得到 best.pt。

常见问题:DataLoader worker exited unexpectedly
解决方法:将 --workers 设为 0 并续训。
D:gesture_ai.venvScriptspython.exe train.py
--resume D:gesture_ai
unsok_palm_192weightslast.pt
--epochs 200
--workers 0
...
3. 模型导出 (ONNX)
RUHMI 支持导入 ONNX,因此我们需要将 PyTorch 模型导出为 ONNX 格式。需要保留两路 head 输出给板端处理。
注意:必须在仓库根目录下运行导出脚本,否则会报 ModuleNotFoundError: No module named 'models'。
3.1 创建导出脚本 export_onnx_heads.py
在仓库根目录新建文件 export_onnx_heads.py,代码如下:
import torch
import torch.nn as nn
CKPT = r"D:gesture_ai
unsok_palm_192weightsest.pt"
OUT = r"D:gesture_aiok_palm_192_heads.onnx"
ck = torch.load(CKPT, map_location="cpu")
model = ck["model"].float().eval()
class HeadWrapper(nn.Module):
def __init__(self, m):
super().__init__()
self.m = m
def forward(self, x):
y, feats = self.m(x)
# feats[0] -> (1,3,12,12,7)
# feats[1] -> (1,3,6,6,7)
return feats[0], feats[1]
w = HeadWrapper(model)
dummy = torch.zeros(1, 3, 192, 192)
torch.onnx.export(
w,
dummy,
OUT,
input_names=["images"],
output_names=["p4_12x12", "p5_6x6"],
opset_version=13,
do_constant_folding=False,
)
print("saved:", OUT)
3.2 运行导出
D:gesture_ai.venvScriptspython.exe .export_onnx_heads.py
正常导出的 ONNX 文件大小约为 1MB 左右。

4. RUHMI 模型转换 (AI Navigator)
参考关于RA生态工作室的视频号回放:

启动 RUHMI AI Navigator 进行转换。
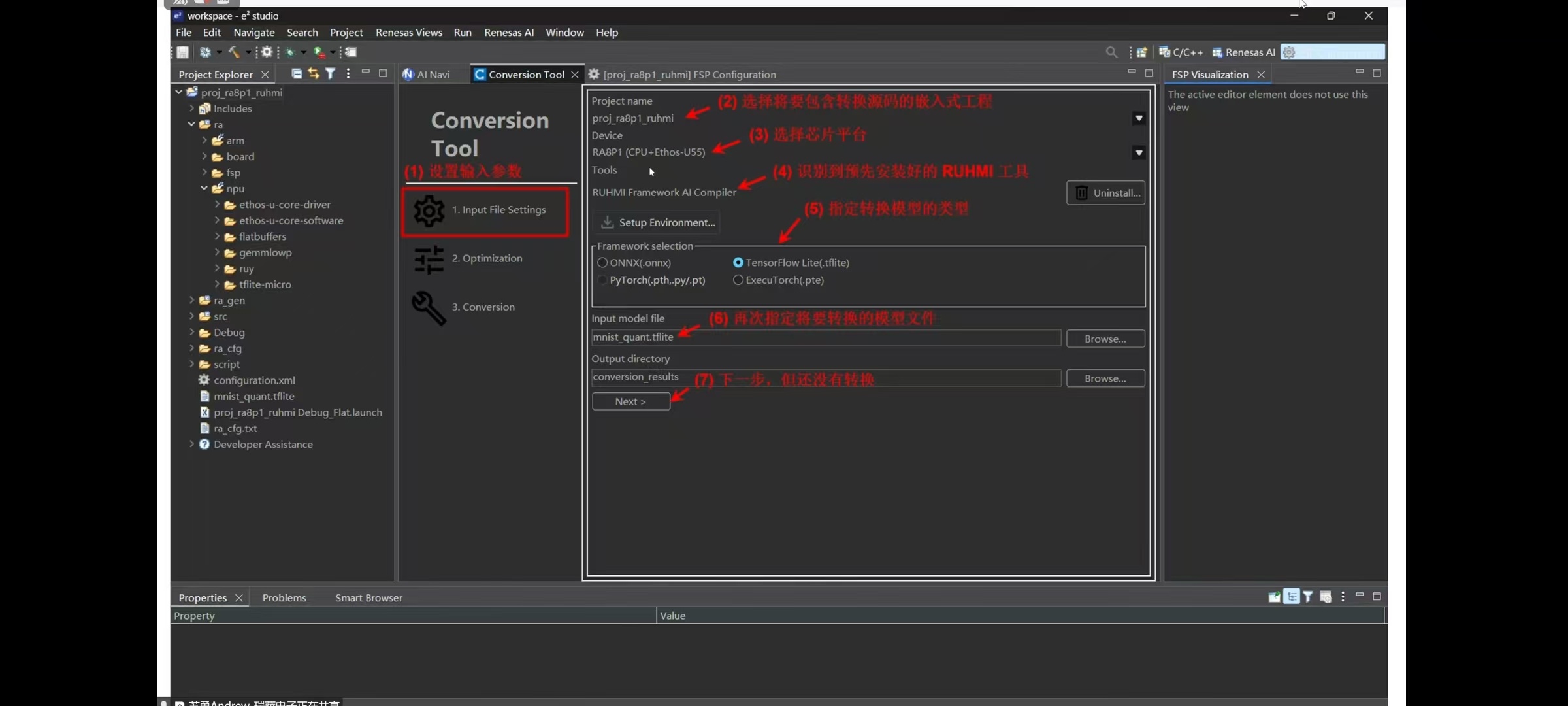
4.1 准备校准数据集 (Calibration Dataset)
用于 INT8 量化校准。建议从训练集中随机抽取 200 张图片。
PowerShell 随机抽取脚本:
$src = "D:gesture_aihagrid_ok_palm_1images rain"
$dst = "D:gesture_aicalib_ok_palm_200"
mkdir $dst -Force | Out-Null
Get-ChildItem $src -File | Get-Random -Count 200 | Copy-Item -Destination $dst
在 AI Navigator 中选择该目录作为 Calibration dataset。

4.2 设置 Mean / Std (重要)
由于训练时只做了 x/255 归一化,板端输入必须匹配。
推荐设置(板端输入 0…1 float):
- Mean:
0, 0, 0 - Std:
1, 1, 1(如果在板端没做 /255,这里要设为 255)
注意:不要使用
mean=127.5, std=127.5,那是 -1…1 的归一化方式。

4.3 检查转换输出
转换成功后,关键生成的源文件位于 buildMCUcompilationsrc:
model.c/.hsub_xxxx_model_data.c/.hsub_xxxx_invoke.c/.h- …

5. 部署到工程:CPU 版本
目标:将 CPU-only 产物集成到 RT-Thread 工程,验证前处理与解码逻辑。
5.1 文件集成
将 RUHMI 生成的 compilationsrc 下的文件复制到工程目录 src/models/:
compute_sub_0000.cmodel.ckernel_library_int.ckernel_library_utils.c

5.2 编译配置 (SConscript)
修改 src/models/SConscript,加入刚复制的源文件:
src = [
os.path.join(cwd, 'model.c'),
os.path.join(cwd, 'compute_sub_0000.c'),
os.path.join(cwd, 'kernel_library_int.c'),
os.path.join(cwd, 'kernel_library_utils.c'),
]

5.3 关键代码修改
1. 输入前处理对齐
修改 src/hal_entry.c,确保输入转为 0…1 (float):
const float inv255 = 1.0f / 255.0f;
dst[0 * plane_size + pixel_idx] = (float)r * inv255;
dst[1 * plane_size + pixel_idx] = (float)g * inv255;
dst[2 * plane_size + pixel_idx] = (float)b * inv255;

2. 后处理解码 (YOLOv5公式)
修改 src/yolo/yolo_rtthread.c,使用 YOLOv5 的解码公式替代传统 Darknet 公式:
float stride_pix = (float)INPUT_W / (float)grid;
float cx = (sigmoid(tx) * 2.0f - 0.5f + j) * stride_pix;
float cy = (sigmoid(ty) * 2.0f - 0.5f + i) * stride_pix;
float ww = (sigmoid(tw) * 2.0f); ww = ww * ww * anchor_w;
float hh = (sigmoid(th) * 2.0f); hh = hh * hh * anchor_h;

3. 调试显示优化
建议在 LCD 显示分类文本、置信度,并用不同颜***分 OK/PALM。

6. 部署到工程:NPU (Ethos-U55) 版本
目标:启用 NPU 加速。RUHMI 针对 NPU 通常生成“三段式”代码:前处理(CPU) -> NPU推理 -> 后处理(CPU)。
6.1 文件集成
RUHMI NPU 版输出包含 sub_0001 (NPU) 等部分。需复制以下文件到 src/models/:
compute_sub_0000.c(CPU 前处理)compute_sub_0002.c(CPU 后处理)sub_0001_*.c(NPU 相关:command strteam, weights, invoke)model.c,ethosu_common.h等

6.2 编译配置
修改 SConscript,加入所有新文件:
src = [
os.path.join(cwd, 'model.c'),
os.path.join(cwd, 'compute_sub_0000.c'),
os.path.join(cwd, 'compute_sub_0002.c'),
os.path.join(cwd, 'sub_0001_command_stream.c'),
os.path.join(cwd, 'sub_0001_invoke.c'),
os.path.join(cwd, 'sub_0001_model_data.c'),
os.path.join(cwd, 'sub_0001_tensors.c'),
# ... 其他依赖库
]
6.3 关键点:NPU 内存配置 (Arena)
1. Arena 放入 OSPI RAM
修改 sub_0001_invoke.c,将 arena 数组放到 OSPI 段,避免占用宝贵的内部 SRAM:
__attribute__((aligned(16), section(".ospi1_cs0_noinit"))) uint8_t sub_0001_arena[...];

2. 输入数据写入 Arena
NPU 的输入通常直接映射到 Arena 的起始位置(offset 0)。
修改 model.c,直接将量化后的数据写入 Arena,而不是临时 buffer:
// 获取 NPU 输入在 Arena 中的地址
int8_t* npu_in = (int8_t*)(sub_0001_arena + sub_0001_address_images_...);
// 执行前处理,直接输出到 npu_in
compute_sub_0000(compute_arena_sub_0000, buf_images, npu_in);
3. Cache 维护 (非常重要)
在调用 NPU 前后必须维护 D-Cache,否则 NPU 读不到最新数据或 CPU 读不到 NPU 的输出。
// Invoke 前:Clean (将 CPU 写的数据刷入 RAM)
SCB_CleanDCache_by_Addr(sub_0001_arena, sizeof(sub_0001_arena));
// Invoke
sub_0001_invoke(...);
// Invoke 后:Invalidate (让 CPU 重新从 RAM 读取)
SCB_InvalidateDCache_by_Addr(sub_0001_arena, sizeof(sub_0001_arena));
6.4 调试建议
- 验证 NPU 是否工作:打印输入和输出的 hash 值或 min/max 值。如果输入变了但输出 hash 不变,说明 NPU 没运行或 invoke 失败。
- 调整阈值:初期将
CONF_THRESH设低(如 0.2),观察max_sig,确认有检测结果后再调高。

本文地址:https://www.yitenyun.com/6636.html