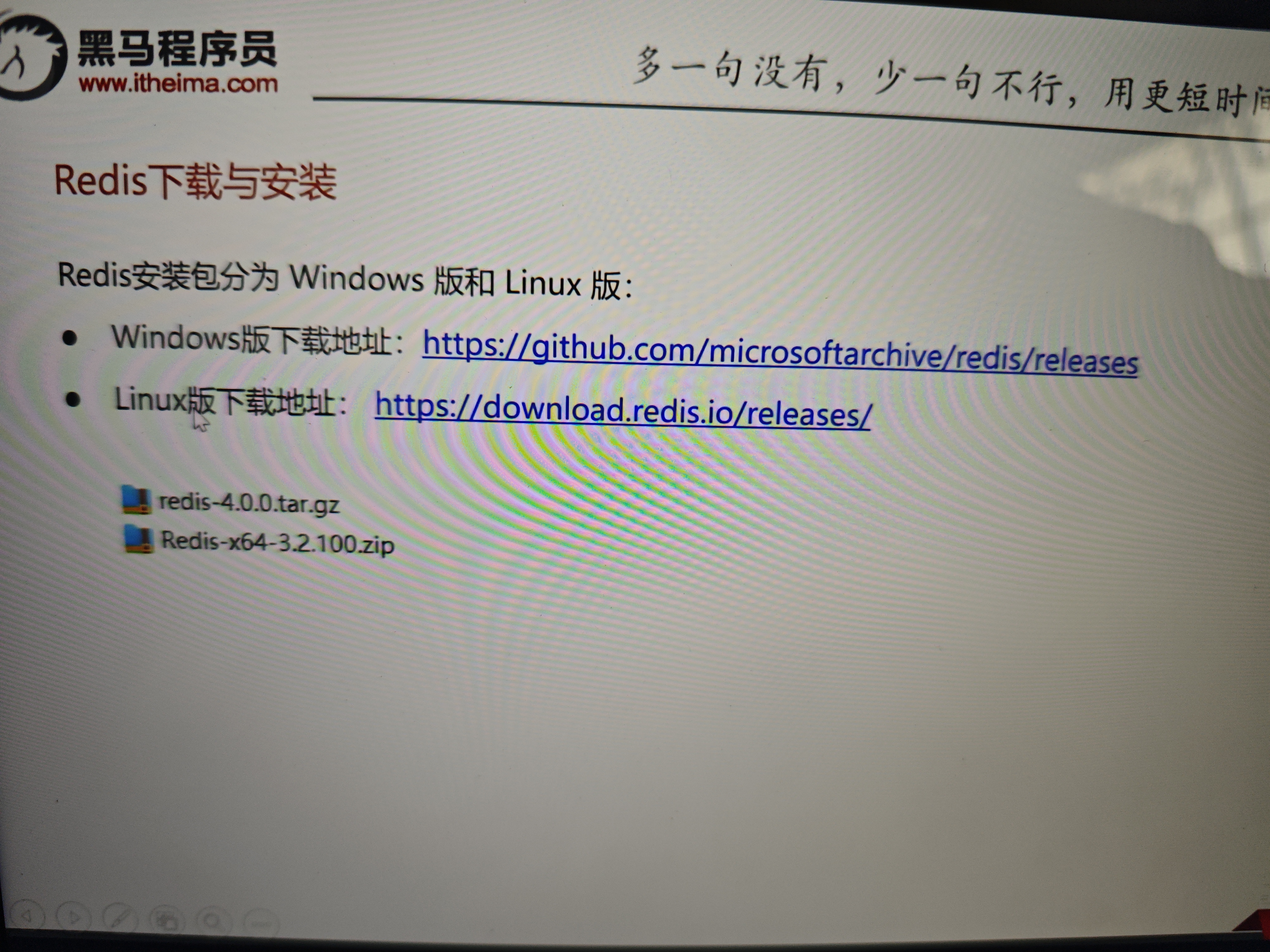
在人工智能的大语言模型(LLM)训练中,奖励模型(Reward Model, RM)是实现人类反馈强化学习(RLHF)核心组件之一。下面我来结



❝ 2024年OpenAI吹响“大模型主导未来变革”的号角,掌握AI大模型技术已成为职业发展的关键突破口。本计划融合学习理论与实

1. 实际应用场景与痛点分析 场景描述 - 周末想看电影或追剧,但面对海量片库,用户常遇到: 1. 不知道选什么类型,刷
概览 正则表达式介绍: 概述: 正确的, 符合特定规则的 字符串. Regular Expression, 正则表达式, 简称: re 细节: 1. 学正则表达
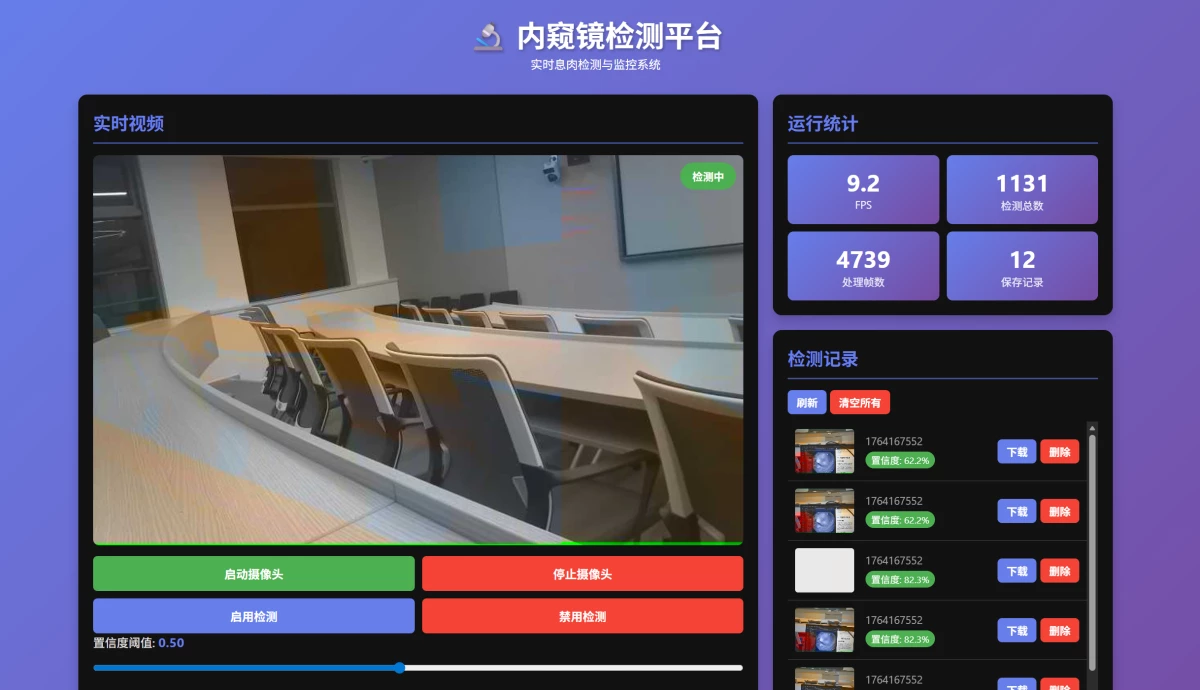
【项目实战】基于 K230 + RT-Smart 的内窥镜息肉检测平台设计与实现 rtthread论坛帖子地址:https://club.rt-thread.org/ask

你在前端可视化开发中遇到的ECharts/HighCharts初始化不渲染、数据更新不刷新问题,是可视化开发的高频兼容性BUG,表现为图表