


干货分享:AI大模型奖励模型(RM)结构解析
在人工智能的大语言模型(LLM)训练中,奖励模型(Reward Model, RM)是实现人类反馈强化学习(RLHF)核心组件之一。

下面我来结合两幅图拆解奖励模型的原理和应用方法。
一、奖励模型的结构拆解

如图1所示,展示了奖励模型的结构构建流程:
1. 从语言模型(SFT模型)复制主干网络
左图部分为一个经过监督微调(SFT)的语言模型,它已具备生成合理文本的能力,它由多层 Decoder 组成,经过前馈网络,最终输出Logits。
2. 构建奖励模型(右侧)
奖励模型的主干网络与SFT模型保持一致,直接复制其 Decoder 层。
不同之处在于 LM Head(语言建模头)被替换成 Reward Head:
- 原LM Head为 Linear(hidden_size → vocab_size),用于输出词表大小的 logits;
- 奖励模型中的 Reward Head 为 Linear(hidden_size → out_dim = 1),即输出一个标量,用于表示整句话的好坏(奖励得分)。
二、奖励模型的训练流程
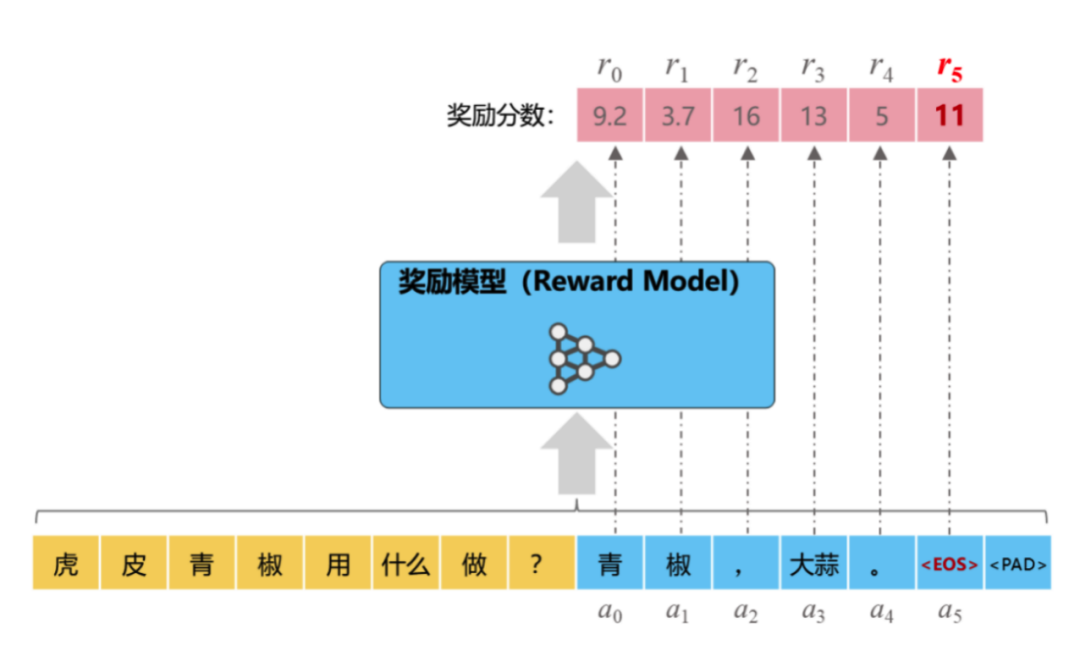
图2,展示了奖励模型在具体训练中的应用流程,以下是关键步骤:
1. 构造训练数据:Prompt + 多个回答
给定一个用户输入(Prompt),如“虎皮青椒用什么做?。
收集多个模型生成的回答(a₀ 到 a₅),这些回答风格、准确度、逻辑性可能有所差异。
2. 人类反馈打分
每个回答都由人工或策略生成一个奖励得分(r₀ ~ r₅)。
可以是绝对分数,也可以是相对排序。
3. 输入模型,输出奖励值
每个Prompt + 回答被喂入奖励模型。
奖励模型输出一个标量分数,用于回归/分类学习。
如图所示,每个回答产生一个对应的奖励分数,如 r₀=9.2、r₅=11 等。
4. 损失函数训练
通常使用 Pairwise Loss(一种损失函数):


如果 rA≫rB 即好回答得分远高于差回答,loss 趋近于 0(模型判断正确,损失很小)
如果 rA≤rB loss 趋近于最大值(模型判断错误,被惩罚)
Pairwise Loss一种常用于训练排序模型或奖励模型的损失函数,表示鼓励模型输出更高的分数给更优的回答。若使用标注的绝对分数,也可用 MSE 或 MAE 等回归损失
import torchimport torch.nn.functional as Fdef pairwise_loss(r_chosen, r_rejected): return -F.logsigmoid(r_chosen - r_rejected).mean()
三、奖励模型的作用
训练好的奖励模型有两个核心用途:
排序生成结果
- 多个候选回答中,选择得分最高的作为最终输出。
用于RLHF中的强化学习阶段
- 奖励模型作为环境,评价策略模型输出的优劣。
- PPO、DPO等算法用其生成奖励信号,反向更新策略模型权重。
未来方向
奖励模型并非完美。一个著名的难题是“奖励黑客”(Reward Hacking)。
Al模型可能会发现奖励评分系统的漏洞并加以利用,而不是真正提升内容质量。例如,如果模型发现“长回答“容易得高分,它可能会生成冗长但空洞的废话来“骗取”奖励。
未来的奖励模型可能会向多模态(结合图像、视频等)发展,并探索通过自监督学习减少对昂贵人工标注数据的依赖。
同时,如何设计更公平、透明且可解释的奖励机制,也是重要的研究方向。

本文地址:https://www.yitenyun.com/5029.html






