


Java 基础常见问题总结(3)
JDK9中对字符串的拼接(+操作)做了什么优化?
结论:jdk9中,确定字符串拼接策略不再是编译阶段就完成的事,而是基于InvokeDynamic将拼接操作延迟到运行时期,并且能支持多种拼接策略,并且有些拼接策略还通过MethodHandle技术来实现
我们这里主要探讨一下字符串的加号拼接(具体使用反编译技术:javap -c Main.class)
jdk9 之前【这里使用Java1.8】,+号的具体操作是:
public class Main {
public static void main(String[] args) {
String a = "123";
String b = a + "222";
System.out.println(b);
}
}
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String 123
2: astore_1
3: new #3 // class java/lang/StringBuilder
6: dup
7: invokespecial #4 // Method java/lang/StringBuilder."":()V
10: aload_1
11: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
14: ldc #6 // String 222
16: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
22: astore_2
23: getstatic #8 // Field java/lang/System.out:Ljava/io/PrintStream;
26: aload_2
27: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
30: return
}
可以看到底层其实帮我们创建了 StringBuilder ,然后再调用append() 进行拼接,最后就是toString()
也就是说你每拼接一步就需要经过这样子3步,性能巨差
并且是在编译阶段就执行了这几步操作,没什么灵活性
jdk9开始【这里使用Java17】,+号的具体操作是:
public static void main(java.lang.String[]);
Code:
0: ldc #7 // String 123
2: astore_1
3: aload_1
4: invokedynamic #9, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;)Ljava/lang/String;
9: astore_2
10: getstatic #13 // Field java/lang/System.out:Ljava/io/PrintStream;
13: aload_2
14: invokevirtual #19 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
17: return
}
可以看到,编译阶段不再进行上面那三步,甚至可以说还没有开始进行拼接,而是出现了InvokeDynamic这个东西,其实引入了StringConcatFactory,它基于InvokeDynamic指令实现,允许操作延迟到运行时实现,也就是字符串拼接不再是编译阶段,而是在运行阶段
运行时具体的拼接策略有:
private enum Strategy {
/**
* 使用 StringBuilder 进行字符串拼接,但不预估所需的存储空间。
*/
BC_SB,
/**
* 使用 StringBuilder 进行字符串拼接,同时尝试估计所需的存储空间,以优化性能。
*/
BC_SB_SIZED,
/**
* 使用 StringBuilder 进行字符串拼接,且能够精确计算出所需的存储空间,以实现最高的效率。
*/
BC_SB_SIZED_EXACT,
/**
* 基于 MethodHandle 技术,使用 StringBuilder 进行拼接,并尝试预估所需的存储空间。
*/
MH_SB_SIZED,
/**
* 基于 MethodHandle 技术,使用 StringBuilder 进行拼接,并精确计算所需的存储空间。
*/
MH_SB_SIZED_EXACT,
/**
* 通过 MethodHandle 技术,直接从输入参数构建一个字节数组,并准确计算出所需的存储空间,以实现高效的字符串拼接。
*/
MH_INLINE_SIZED_EXACT
}
MethodHandle 和反射有点像,可以在运行时动态查看和调用方法,是偏底层的技术
到这里,是不是就能理解上面的结论是怎么来的
JDK9中String的存储发生了什么变化?
很明显的一个变化就是由原来的char数组换成了byte数组
private final byte[] value;
private final byte coder;
主要就是这两个属性
之所以要这样改动的原因就是为了节省内存,提高性能
众所周知,char是占用两个字节的,旧版本的String之所以要使用char数组进行存储就是考虑到有一些其他国家的语言,例如中文,单个字节存储不下,所以使用char数组进行存储
但是后来语言开发人员发现大部分使用者很少使用中文,更多是使用英文,就会造成内存浪费(因为每个字符都是占用2字节,实际却只用得到1字节)
所以换成了 byte 数组,但是换成byte数组之后为了继续兼容中文等语言,就通过coder字段进行标识
@Native static final byte LATIN1 = 0;
@Native static final byte UTF16 = 1;
并使用这样两个常量标识一个字符占用多少字节,当判断到字符串内容为纯英文的时候,coder 赋值为LATIN1,即每个字符占用一个字节
当判断到含有中文的时候,coder 赋值为UTF16,即每个字符使用两个字节进行存储,这样就能做到了兼容
缺点就是当一串字符串中只有一个中文,其他均为英文的时候,同样是一个字符占用两个字节,会有一定的浪费
Lambda表达式是如何实现的?
public class Main {
public static void main(String[] args) {
List list = Arrays.asList("a", "b", "c");
list.forEach((t) -> System.out.println(t));
}
}
其实这些语法糖都是依赖于底层的解析功能实现的,也就是在编译阶段,编译器会进行解糖操作,转化成使用内部的API进行实现
RPC接口返回中,使用基本类型还是包装类?
其实都可以,但是我们会优先使用包装类,因为包装类能表达的语义更广,可以支持null
可能在一些场景会出现调用异常,而不是真实的返回类型,这个时候使用包装类返回的是null,使用基本类型返回的是默认值,会有歧义
serialVersionUID有何用途?如果没定义会有什么问题?
首先就是要知道序列化和反序列化
因为无论是网络还是磁盘都是只能传输字节的,不能传输原始对象,所以需要进行序列化和反序列化
而serialVersionUID就相当于是一个身份校验,主要的作用就是在进行反序列化的时候,jvm会判断传递过来的字节流中的serialVersionUID和要进行反序列化的接收类定义的serialVersionUID是否是一致的,如果是一致的,就允许序列化,否则会抛出异常
ava.io.InvalidClassException: com.hollis.User1; local class
incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2
最后就是只要是实现了 Serializable接口就建议指定一下serialVersionUID,如果没有的话系统也会自动的分配一个,但是如果你的类结构发生改变就可能导致serialVersionUID发生变化,造成对应不上,导致反序列化失败
SimpleDateFormat是线程安全的吗?使用时应该注意什么?
在Java中获取时间的方式有很多,但是不同方法获取出来的格式不同,这个时候就需要工具类来进行格式化,也就是使用SimpleDateFormat,但是它是线程不安全的,绝对不能定义成static进行共享
之所以线程不安全是因为它里面使用calendar来保存时间,当多线程可以共享的时候就会导致这个记录的时间被反复修改
那怎么保证线程安全?
- 加锁
- 定义成局部变量
- 和ThreadLocal绑定,就能做到线程独立
- 使用jdk8推荐的DateTimeFormatter
Stream的并行流一定比串行流更快吗?
不一定,底层其实是使用ForkJoin框架来实现的
List list = Arrays.asList("1", "2", "3", "4", "5");
list.parallelStream().forEach(a -> System.out.println(a));
ForkJoin是分治思想,就是把大任务分成多个子任务,执行之后再将各个子任务的结果进行合并返回
具体分成多少个任务就要看机器的配置了,如果核数比较少或是内存较紧张的情况下,线程很难上去,真正执行的线程可能没几个
可以总结一下几个核心影响因素:
- 创建线程的开销
- 机器物理资源
- 任务分配的均匀程度
- 单任务执行时长
普遍情况下,单核,串行效率高,多核,并行效率高
String、StringBuilder和StringBuffer的区别?
可变性:String 不可变,StringBuilder和StringBuffer可变
线程安全:StringBuilder线程不安全、String和StringBuffer线程安全
性能:StringBuilder性能最好、StringBuffer其次、String最差
StringBuilder为什么线程不安全?StringBuffer和String又是如何保证安全的?
String做到线程安全的方式就是因为它不可变,一变就创建一个新对象,而StringBuffer则是对可能出现冲突的方法加上了synchronized关键字进行修饰
而StringBulider却什么都没有,所以它线程不安全
String a = "ab"; String b = "a" + "b"; a == b 吗?
等于
public class Main {
public static void main(String[] args) {
String a = "ab";
String b = "a" + "b";
System.out.println(a == b);
}
}
答案就是一样,运行结果为true
因为String底层其实是使用的字符串常量池存储每一个常量,"a" + "b" 最终结果是 "ab" ,。所以底层只会存储一份常量
== 比较的是地址,这两个再常量池中指向的是同一个对象,所以结果为true
String str=newString("caixukun")创建了几个对象?
1个或是2个
首先就是new这个动作就一定会在堆中创建出一个对象,然后会到常量池中寻找是否有字符串 "caixukun"
如果有的话,堆中的对象就会记录这个字符串的引用,没有就会先创建这个字符串,然后才把引用赋值给堆中的这个对象

结论就是一个或是两个,取决于这个对象原先是否已经存在了
String是如何实现不可变的?为什么设计成不可变的?
下面是jdk8的源码,jdk9之后char数组变成了byte数组,不过原理一样
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
}
可以发现,String的不可变主要体现在以下几个方面:
- String类被声明为final,这意味着它不能被继承。那么他里面的方法就是没办法被重写的。
- 用final修饰字符串内容的char[](从JDK 1.9开始,char[]变成了byte[]),由于该数组被声明为final,一旦数组被初始化,就不能再指向其他数组。
- String类没有提供用于修改字符串内容的公共方法。例如,没有提供用于追加、删除或修改字符的方法。如果需要对字符串进行修改,会创建一个新的String对象。
那我们平时在代码中对字符串进行修改的操作,底层是怎么变的
public static void main(String[] args) {
String str = "123";
str = "bbb";
}

其实底层不是修改字符串,而是创建一个新的对象出来,str指向的是新的对象,所以如果是一些字符串更新比较频繁的场景,最好还是用StringBuilder和StringBuffer吧
然后就是为什么字符串要设置成不可变
我认为主要是因为有缓存池的存在,两个相同的字符串,其实会共用缓存池中的同一个对象,要是可以修改的话,那会影响到另一个
其次就是线程安全性,正因为不可变,所以天然就是线程安全的
String有长度限制吗?是多少?
有,并且编译器和运行期还不一样
编译器最大为65534
运行期为2^31-1(int的最大长度),之所以受到int的影响是因为length是int类型(差不多4GB)
虽然运行期能达到的长度非常长,但是受到JVM的限制,一般是达不到的
字符串是什么时候进入字符串常量池的?String中intern的原理是什么?
public static void main(String[] args) {
String s1 = new String("11");
String s2 = "222";
}
对于直接双引号声明的方式,会在编译期入池,而对于手动调用new String("111").intern()这种就是运行期入池
public static void main(String[] args) {
String str = new String("111").intern();
String s = "111";
System.out.println(s == str); // true
}
首先需要先知道intern() 的作用,它会先到常量池中找一下要创建的字符串是否是存在的,如果是不存在的就直接创建到常量池中,并把这个地址返回给变量
接下来直接上实战
String s1 = "1" + "2";
String s2 = "12";
System.out.println(s1 == s2); //true
String s1 = new String("12");
String s2 = "12";
System.out.println(s1 == s2); //false
String s1 = new String("1") + new String("2");
String s2 = "12";
System.out.println(s1 == s2); //false
String s1 = new String("1") + new String("2");
s1.intern();
String s2 = "12";
System.out.println(s1 == s2); //true
String s1 = new String("1") + new String("2");
String s2 = "12";
s1.intern();
System.out.println(s1 == s2); //false
看到这可能就有人会觉得头大了,但是不要慌,一点一点来剖析
首先我们先确定一个前提:new String("12") 和 String str = "12" 这两种方式都会在常量池中创建字符串"12"
我们这里解析就按照jdk6之后的版本来吧,众所周知,jdk7开始,常量池已经迁移到堆中了

第一种情况,执行的时候底层会把 "1" + "2" 优化成 "12" 再存起来,所以结果自然是true

第二种情况是因为s1存储的是堆中对象的引用,所以比较的结果也自然是false
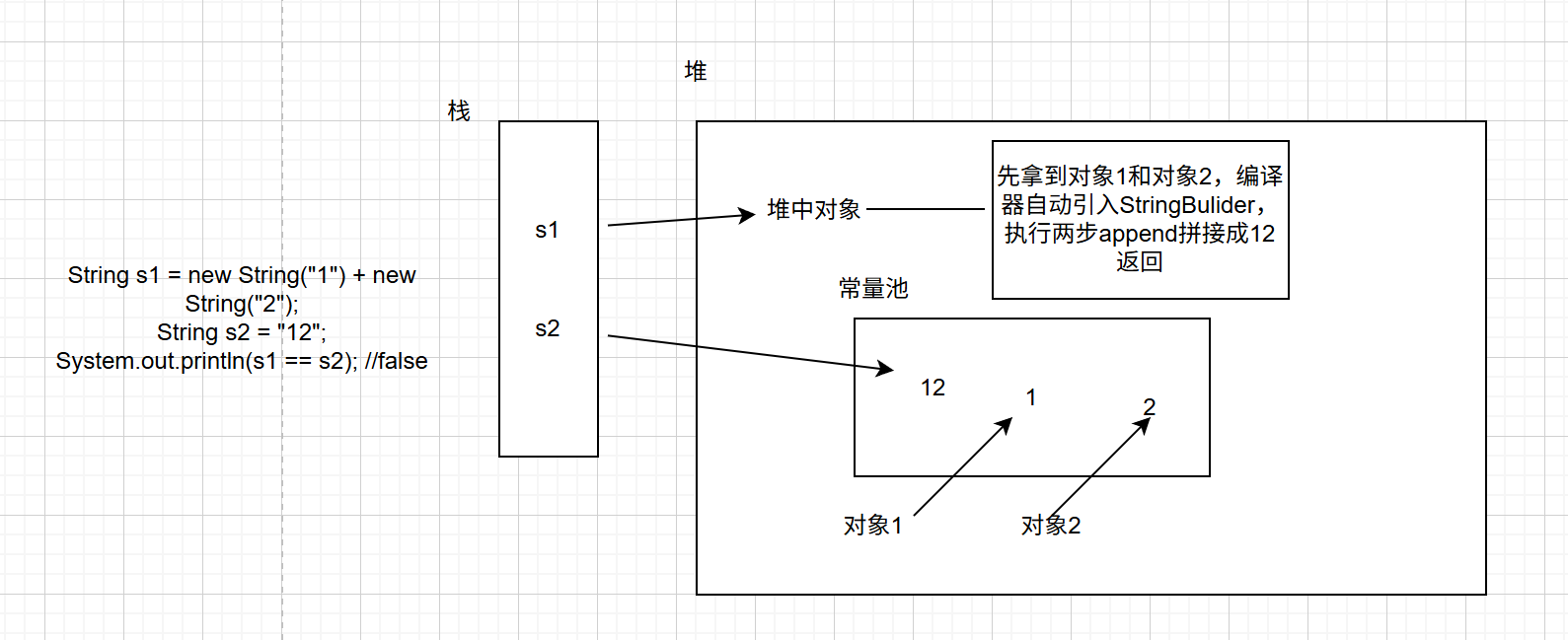
第三种情况是一个陷阱,执行String s1 = new String("1") + new String("2");的时候其实只创建了"1" "2" 两个常量,然后编译器引入了StringBulider实现拼接为12返回,但是常量池中并不存在"12"
当执行String s2 = "12";才将"12"放到常量池中

第四种情况,前面部分一样,但是当执行s1.intern();的时候会把s1的引用放到常量池中,所以后面String s2 = "12";指向的其实就是常量池中存储的这个引用,这是jdk6之后比较大的一个变化,不再复制,而是存储引用
所以后面会一样
注意:s1.intern()会判断s1表示的字符串是否在常量池中存在,不存在的时候会直接把s1的引用塞到常量池中,并返回这个引用在常量池中存储的地址
那么最后一种就很好理解了
String s1 = new String("1") + new String("2");
String s2 = "12";
s1.intern();
System.out.println(s1 == s2); //false
因为当执行s1.intern();的时候发现"12" 已经在常量池中存在,所以会返回它的引用,不过我们这里因为没有重新对s1进行赋值,所以结果不同
try中returnA,catch中returnB,finally中returnC,最终返回值是什么?
返回C
nt t() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
return 3;
}
}
最终结果只会返回3,因为无论是执行try还是catch的代码,当执行到return语句的时候都会先把要返回的结果暂存起来,先执行finally ,然后再去执行暂存起来的,但是如果执行finally时遇到return,就就没办法了,会直接结束
while(true)和for(;;)哪个性能好?
其实性能是一样的,我之前在网上看过一篇文章,有人对两部分代码进行反编译,结果发现一摸一样,所以没有性能上的区别
常见的字符编码有哪些?有什么区别?
|
编码 |
核心特点 |
使用场景 |
|
ASCII |
128个字符,1字节 |
纯英文 |
|
Unicode |
字符集标准,定义了全世界字符的编号 |
理论标准 |
|
UTF-8 |
Unicode的实现,1-4字节变长 |
互联网主流,兼容ASCII |
|
UTF-16 |
Unicode的实现,2或4字节 |
Java、Windows内部 |
|
GBK/GB2312/GB18030 |
中文专用,2字节为主 |
中文Windows、国内老系统 |
Unicode 和 UTF-8 的关系?
- Unicode:只规定字符的唯一编号(如"中"=U+4E2D),不规定怎么存
- UTF-8:是Unicode的一种实现方式,用1-4个字节变长存储,英文1字节、中文3字节
之所以使用变长存储就是为了节省空间,英文用不了那么多,中文又用不了那么少,所以直接区别处理
为什么有UTF-8还要GBK?
关键就是节省空间,正是因为UTF-8太全了,对中文的表示排到了需要使用3个字节表示的位置,但是我们如果只是做一个给中国人看的网站,直接用GBK比较好,它只需要2个字节就行
为什么会有乱码现象?
就是编码和解码的方式对应不上







