Day39 复习日
@浙大疏锦行
作业:对之前的信贷项目,利用神经网络训练下,尝试用所学的知识让代码更规范美观
尝试进入nn.Moudle中,查看他的方法
# Day39 复习日
#作业:对之前的信贷项目,利用神经网络训练下,尝试用所学的知识让代码更规范美观
#尝试进入nn.Moudle中,查看他的方法
import pandas as pd
import numpy as np
# 读取信贷数据集(xlsx)
df_xlsx = pd.read_excel('data.xlsx')
print('XLSX 数据维度:', df_xlsx.shape)
# 读取信贷数据集(csv)并做清洗
df = pd.read_csv('data.csv')
print('CSV 原始数据维度:', df.shape)
# 将明显异常的占位值先标记为缺失值
# 常见:Current Loan Amount 里 99999999 表示异常值
if 'Current Loan Amount' in df.columns:
df.loc[df['Current Loan Amount'] == 99999999, 'Current Loan Amount'] = np.nan
# 缺失值统计
missing_before = df.isna().sum().sort_values(ascending=False)
print('缺失值统计(前10列):')
print(missing_before.head(10))
# 数值列与类别列划分
num_cols = df.select_dtypes(include=[np.number]).columns
cat_cols = df.select_dtypes(exclude=[np.number]).columns
# 异常值处理:对数值列用 IQR 进行截断(winsorize)
def clip_outliers_iqr(s):
q1 = s.quantile(0.25)
q3 = s.quantile(0.75)
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
return s.clip(lower, upper)
for c in num_cols:
df[c] = clip_outliers_iqr(df[c])
# 缺失值填补:数值列用中位数,类别列用众数
for c in num_cols:
median_val = df[c].median()
df[c] = df[c].fillna(median_val)
for c in cat_cols:
mode_val = df[c].mode(dropna=True)
if not mode_val.empty:
df[c] = df[c].fillna(mode_val.iloc[0])
# 处理后缺失值统计
missing_after = df.isna().sum().sum()
print('处理后缺失值总数:', missing_after)
print('处理后数据维度:', df.shape)
# 简要查看数据
print(df.head())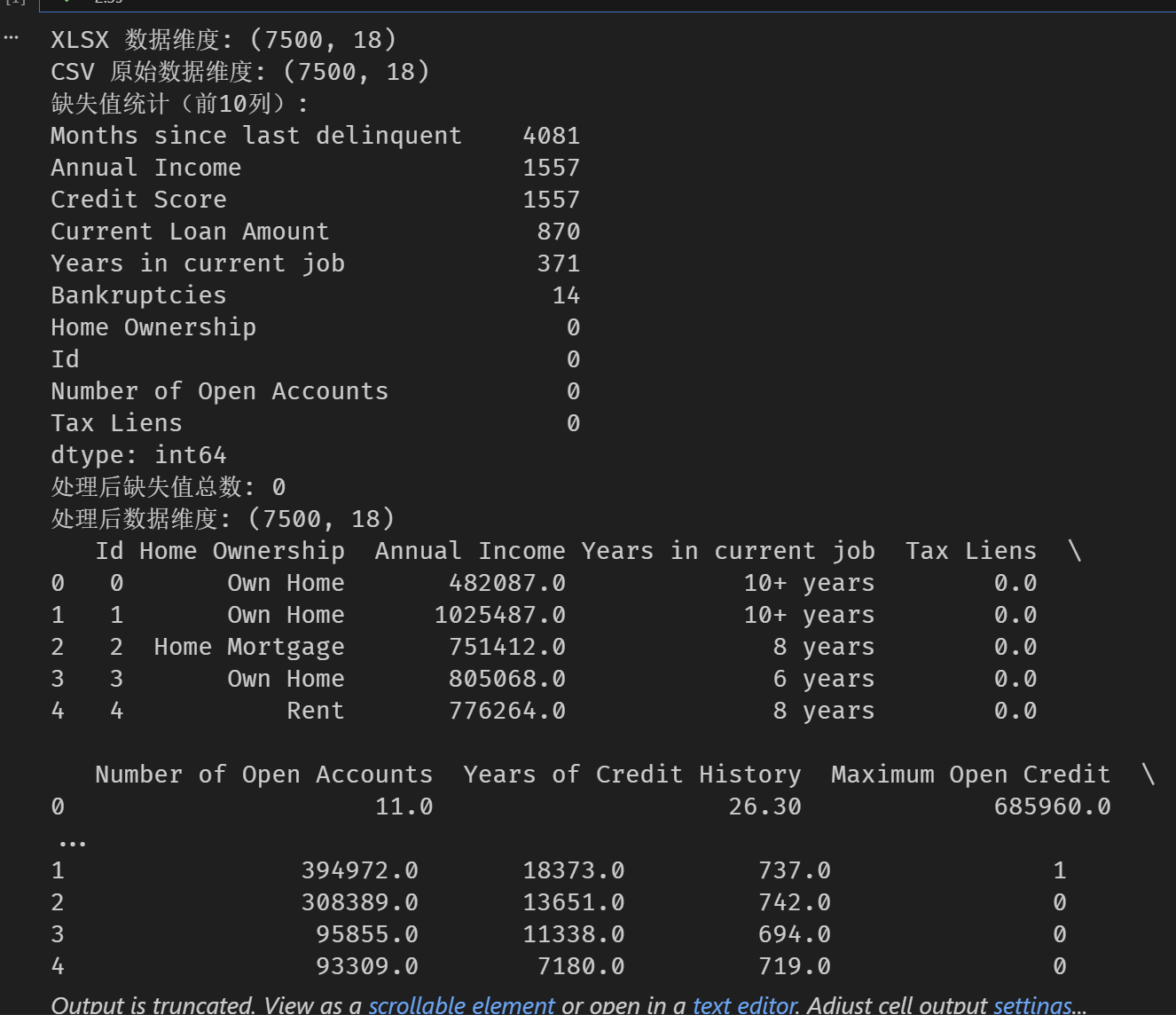
进入 nn.Module:查看源码与常用方法
# 进入 nn.Module:查看源码与常用方法
import inspect
import torch.nn as nn
print("nn.Module 文件路径:")
print(inspect.getfile(nn.Module))
print("
常用方法(部分):")
methods = [
"forward", "parameters", "named_parameters", "state_dict", "load_state_dict",
"train", "eval", "to", "cuda", "cpu", "zero_grad", "children", "modules"
]
for m in methods:
print("-", m)
print("
nn.Module 源码节选(前60行):")
src = inspect.getsource(nn.Module).splitlines()
print("
".join(src[:60]))
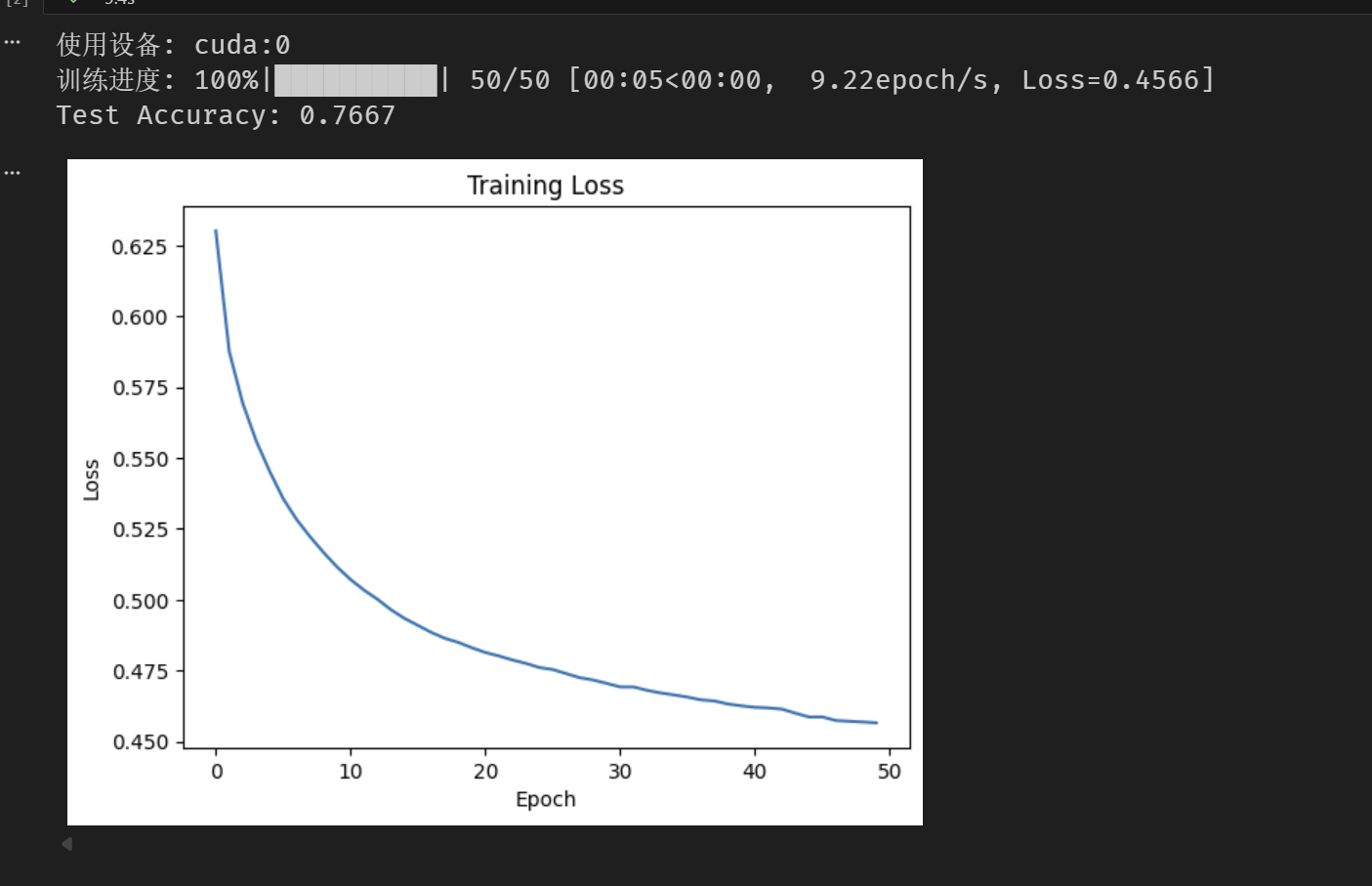
训练信贷数据集
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from tqdm import tqdm
# 设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 选择特征与标签(信贷)
target_col = "Credit Default"
drop_cols = ["Id"]
X = df.drop(columns=[target_col] + [c for c in drop_cols if c in df.columns])
y = df[target_col]
# 类别列独热编码
X = pd.get_dummies(X, drop_first=True)
# 标签转为 0/1
if y.dtype == "O":
y = y.map({"Yes": 1, "No": 0}).fillna(y)
y = y.astype(int)
# 划分训练/测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 标准化数值特征
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转为张量
X_train = torch.tensor(X_train, dtype=torch.float32).to(device)
y_train = torch.tensor(y_train.values, dtype=torch.float32).unsqueeze(1).to(device)
X_test = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test.values, dtype=torch.float32).unsqueeze(1).to(device)
train_loader = DataLoader(TensorDataset(X_train, y_train), batch_size=256, shuffle=True)
class CreditMLP(nn.Module):
def __init__(self, in_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
def forward(self, x):
return self.net(x)
model = CreditMLP(X_train.shape[1]).to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 50
losses = []
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:
for epoch in range(num_epochs):
model.train()
running = 0.0
for xb, yb in train_loader:
logits = model(xb)
loss = criterion(logits, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running += loss.item() * xb.size(0)
epoch_loss = running / len(train_loader.dataset)
losses.append(epoch_loss)
if (epoch + 1) % 5 == 0:
pbar.set_postfix({"Loss": f"{epoch_loss:.4f}"})
pbar.update(1)
# 评估
model.eval()
with torch.no_grad():
probs = torch.sigmoid(model(X_test))
preds = (probs >= 0.5).float()
acc = (preds.eq(y_test)).float().mean().item()
print(f"Test Accuracy: {acc:.4f}")
# 损失曲线
plt.plot(losses)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.show()效果图
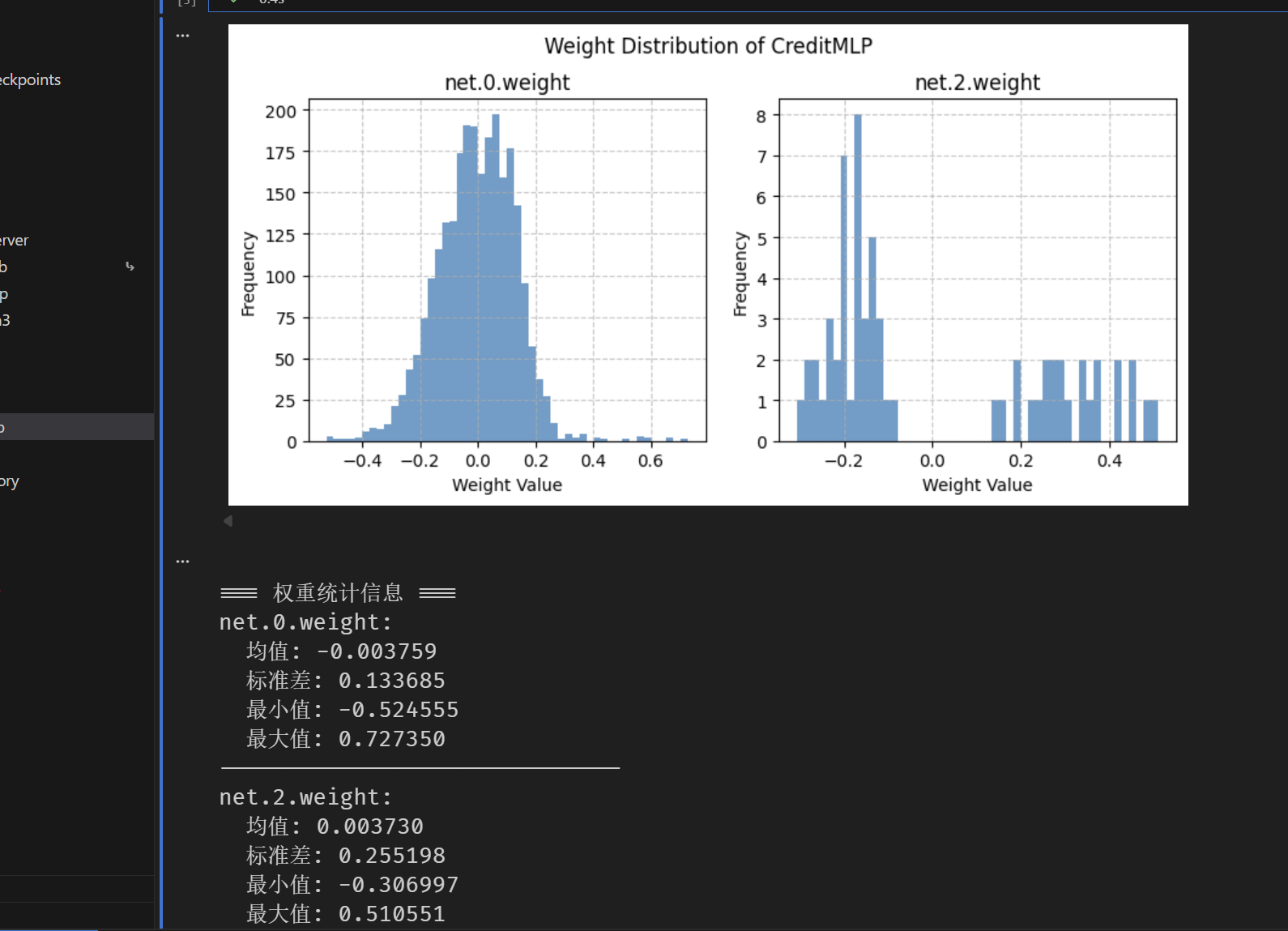
提取并可视化信贷模型权重
# 提取并可视化信贷模型权重
weight_data = {
name: param.detach().cpu().numpy()
for name, param in model.named_parameters()
if "weight" in name
}
if not weight_data:
print("未找到权重参数")
else:
# 可视化权重分布
fig, axes = plt.subplots(1, len(weight_data), figsize=(4 * len(weight_data), 4))
if len(weight_data) == 1:
axes = [axes]
fig.suptitle("Weight Distribution of CreditMLP")
for i, (name, weights) in enumerate(weight_data.items()):
weights_flat = weights.ravel()
axes[i].hist(weights_flat, bins=50, alpha=0.7)
axes[i].set_title(name)
axes[i].set_xlabel("Weight Value")
axes[i].set_ylabel("Frequency")
axes[i].grid(True, linestyle="--", alpha=0.7)
plt.tight_layout()
plt.subplots_adjust(top=0.85)
plt.show()
# 统计信息
print("
=== 权重统计信息 ===")
for name, weights in weight_data.items():
print(f"{name}:")
print(f" 均值: {weights.mean():.6f}")
print(f" 标准差: {weights.std():.6f}")
print(f" 最小值: {weights.min():.6f}")
print(f" 最大值: {weights.max():.6f}")
print("-" * 30)效果图
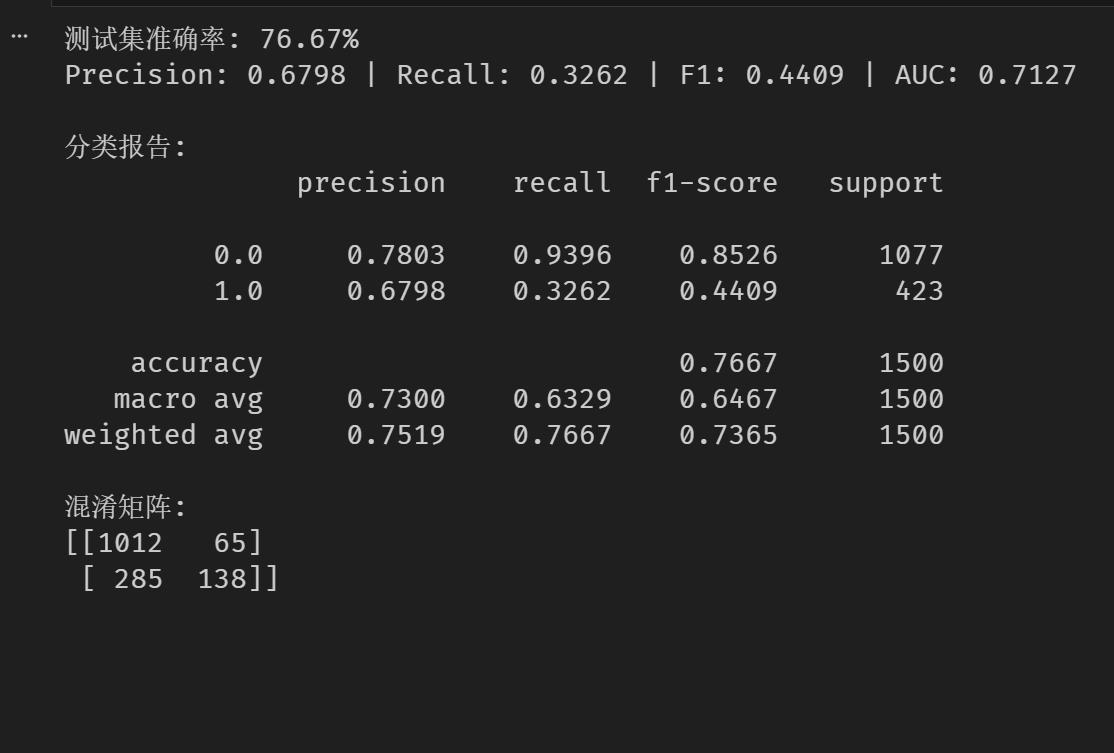
信贷数据集(二分类)评估
# 信贷数据集(二分类)评估
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, confusion_matrix, classification_report
)
model.eval()
with torch.no_grad():
logits = model(X_test)
probs = torch.sigmoid(logits)
preds = (probs >= 0.5).float()
# 转到 CPU 便于统计
y_true = y_test.detach().cpu().numpy().reshape(-1)
y_prob = probs.detach().cpu().numpy().reshape(-1)
y_pred = preds.detach().cpu().numpy().reshape(-1)
acc = accuracy_score(y_true, y_pred)
prec = precision_score(y_true, y_pred, zero_division=0)
rec = recall_score(y_true, y_pred, zero_division=0)
f1 = f1_score(y_true, y_pred, zero_division=0)
try:
auc = roc_auc_score(y_true, y_prob)
except ValueError:
auc = float("nan")
print(f"测试集准确率: {acc * 100:.2f}%")
print(f"Precision: {prec:.4f} | Recall: {rec:.4f} | F1: {f1:.4f} | AUC: {auc:.4f}")
print("
分类报告:")
print(classification_report(y_true, y_pred, digits=4))
print("混淆矩阵:")
print(confusion_matrix(y_true, y_pred))效果图